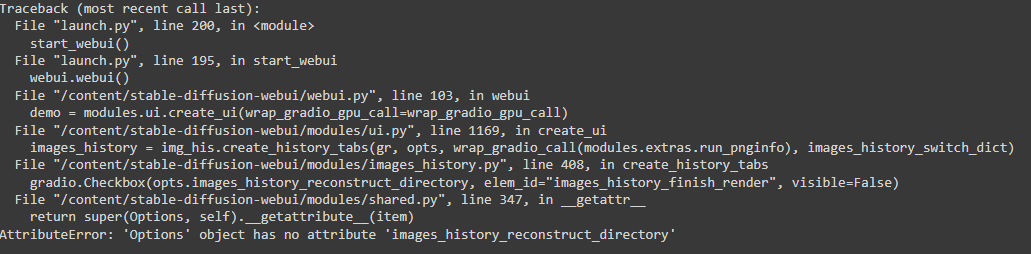
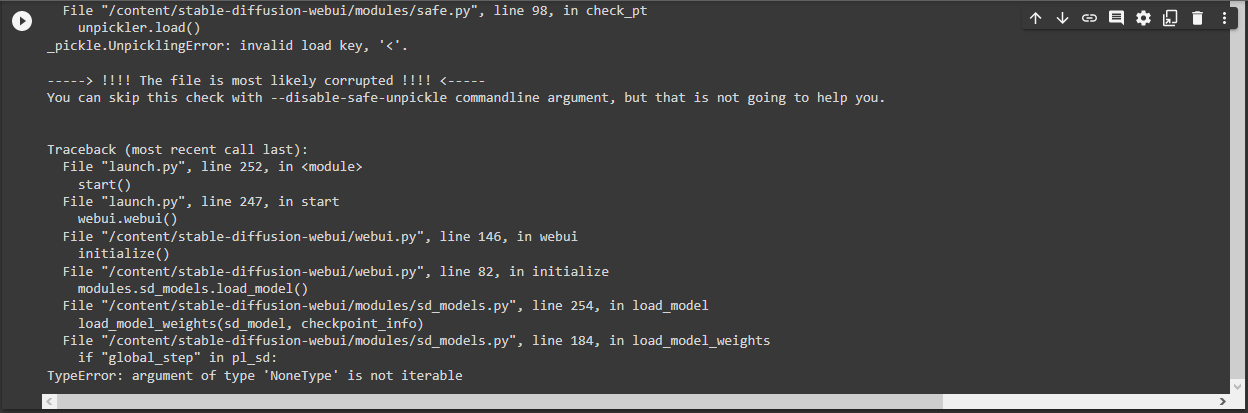
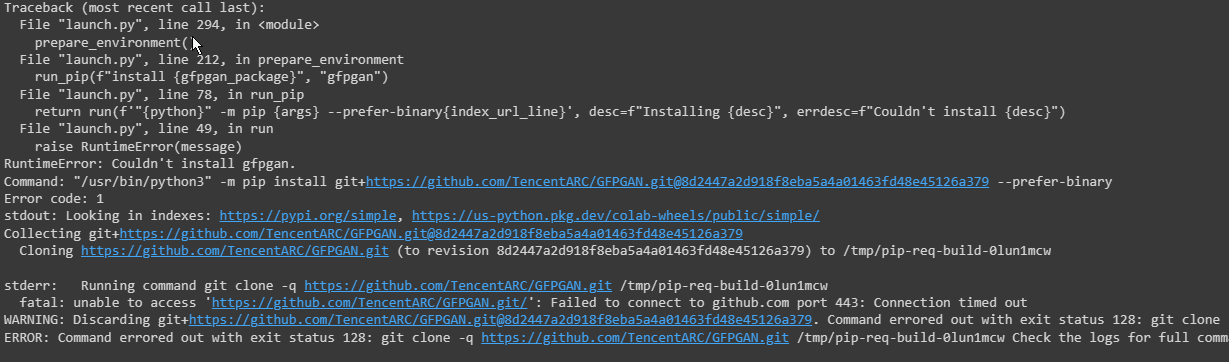
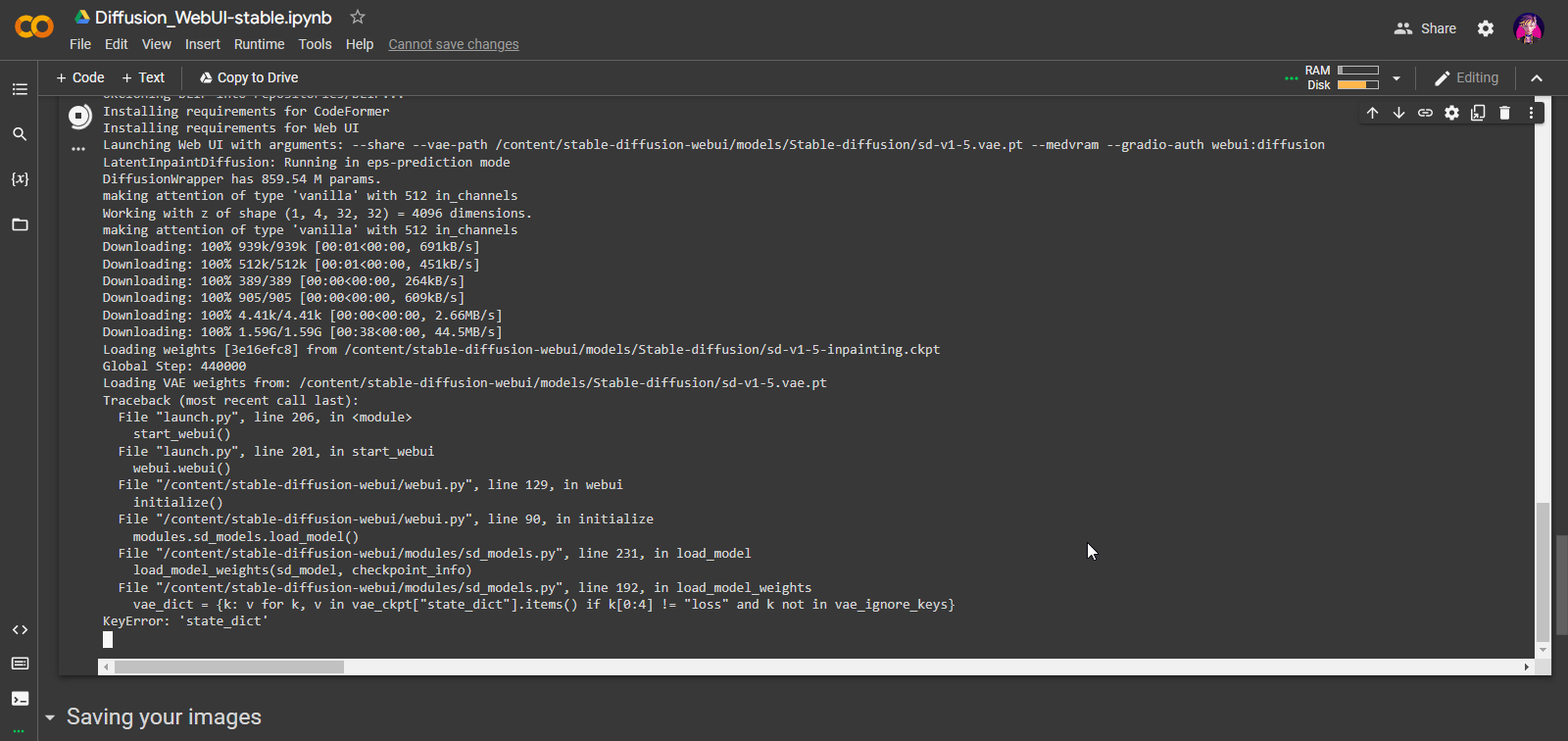
RuntimeError: Error(s) in loading state_dict for AutoencoderKL:
Missing key(s) in state_dict: "encoder.conv_in.weight", "encoder.conv_in.bias", "encoder.down.0.block.0.norm1.weight", "encoder.down.0.block.0.norm1.bias", "encoder.down.0.block.0.conv1.weight", "encoder.down.0.block.0.conv1.bias", "encoder.down.0.block.0.norm2.weight", "encoder.down.0.block.0.norm2.bias", "encoder.down.0.block.0.conv2.weight", "encoder.down.0.block.0.conv2.bias", "encoder.down.0.block.1.norm1.weight", "encoder.down.0.block.1.norm1.bias", "encoder.down.0.block.1.conv1.weight", "encoder.down.0.block.1.conv1.bias", "encoder.down.0.block.1.norm2.weight", "encoder.down.0.block.1.norm2.bias", "encoder.down.0.block.1.conv2.weight", "encoder.down.0.block.1.conv2.bias", "encoder.down.0.downsample.conv.weight", "encoder.down.0.downsample.conv.bias", "encoder.down.1.block.0.norm1.weight", "encoder.down.1.block.0.norm1.bias", "encoder.down.1.block.0.conv1.weight", "encoder.down.1.block.0.conv1.bias", "encoder.down.1.block.0.norm2.weight", "encoder.down.1.block.0.norm2.bias", "encoder.down.1.block.0.conv2.weight", "encoder.down.1.block.0.conv2.bias", "encoder.down.1.block.0.nin_shortcut.weight", "encoder.down.1.block.0.nin_shortcut.bias", "encoder.down.1.block.1.norm1.weight", "encoder.down.1.block.1.norm1.bias", "encoder.down.1.block.1.conv1.weight", "encoder.down.1.block.1.conv1.bias", "encoder.down.1.block.1.norm2.weight", "encoder.down.1.block.1.norm2.bias", "encoder.down.1.block.1.conv2.weight", "encoder.down.1.block.1.conv2.bias", "encoder.down.1.downsample.conv.weight", "encoder.down.1.downsample.conv.bias", "encoder.down.2.block.0.norm1.weight", "encoder.down.2.block.0.norm1.bias", "encoder.down.2.block.0.conv1.weight", "encoder.down.2.block.0.conv1.bias", "encoder.down.2.block.0.norm2.weight", "encoder.down.2.block.0.norm2.bias", "encoder.down.2.block.0.conv2.weight", "encoder.down.2.block.0.conv2.bias", "encoder.down.2.block.0.nin_shortcut.weight", "encoder.down.2.block.0.nin_shortcut.bias", "encoder.down.2.block.1.norm1.weight", "encoder.down.2.block.1.norm1.bias", "encoder.down.2.block.1.conv1.weight", "encoder.down.2.block.1.conv1.bias", "encoder.down.2.block.1.norm2.weight", "encoder.down.2.block.1.norm2.bias", "encoder.down.2.block.1.conv2.weight", "encoder.down.2.block.1.conv2.bias", "encoder.down.2.downsample.conv.weight", "encoder.down.2.downsample.conv.bias", "encoder.down.3.block.0.norm1.weight", "encoder.down.3.block.0.norm1.bias", "encoder.down.3.block.0.conv1.weight", "encoder.down.3.block.0.conv1.bias", "encoder.down.3.block.0.norm2.weight", "encoder.down.3.block.0.norm2.bias", "encoder.down.3.block.0.conv2.weight", "encoder.down.3.block.0.conv2.bias", "encoder.down.3.block.1.norm1.weight", "encoder.down.3.block.1.norm1.bias", "encoder.down.3.block.1.conv1.weight", "encoder.down.3.block.1.conv1.bias", "encoder.down.3.block.1.norm2.weight", "encoder.down.3.block.1.norm2.bias", "encoder.down.3.block.1.conv2.weight", "encoder.down.3.block.1.conv2.bias", "encoder.mid.block_1.norm1.weight", "encoder.mid.block_1.norm1.bias", "encoder.mid.block_1.conv1.weight", "encoder.mid.block_1.conv1.bias", "encoder.mid.block_1.norm2.weight", "encoder.mid.block_1.norm2.bias", "encoder.mid.block_1.conv2.weight", "encoder.mid.block_1.conv2.bias", "encoder.mid.attn_1.norm.weight", "encoder.mid.attn_1.norm.bias", "encoder.mid.attn_1.q.weight", "encoder.mid.attn_1.q.bias", "encoder.mid.attn_1.k.weight", "encoder.mid.attn_1.k.bias", "encoder.mid.attn_1.v.weight", "encoder.mid.attn_1.v.bias", "encoder.mid.attn_1.proj_out.weight", "encoder.mid.attn_1.proj_out.bias", "encoder.mid.block_2.norm1.weight", "encoder.mid.block_2.norm1.bias", "encoder.mid.block_2.conv1.weight", "encoder.mid.block_2.conv1.bias", "encoder.mid.block_2.norm2.weight", "encoder.mid.block_2.norm2.bias", "encoder.mid.block_2.conv2.weight", "encoder.mid.block_2.conv2.bias", "encoder.norm_out.weight", "encoder.norm_out.bias", "encoder.conv_out.weight", "encoder.conv_out.bias", "decoder.conv_in.weight", "decoder.conv_in.bias", "decoder.mid.block_1.norm1.weight", "decoder.mid.block_1.norm1.bias", "decoder.mid.block_1.conv1.weight", "decoder.mid.block_1.conv1.bias", "decoder.mid.block_1.norm2.weight", "decoder.mid.block_1.norm2.bias", "decoder.mid.block_1.conv2.weight", "decoder.mid.block_1.conv2.bias", "decoder.mid.attn_1.norm.weight", "decoder.mid.attn_1.norm.bias", "decoder.mid.attn_1.q.weight", "decoder.mid.attn_1.q.bias", "decoder.mid.attn_1.k.weight", "decoder.mid.attn_1.k.bias", "decoder.mid.attn_1.v.weight", "decoder.mid.attn_1.v.bias", "decoder.mid.attn_1.proj_out.weight", "decoder.mid.attn_1.proj_out.bias", "decoder.mid.block_2.norm1.weight", "decoder.mid.block_2.norm1.bias", "decoder.mid.block_2.conv1.weight", "decoder.mid.block_2.conv1.bias", "decoder.mid.block_2.norm2.weight", "decoder.mid.block_2.norm2.bias", "decoder.mid.block_2.conv2.weight", "decoder.mid.block_2.conv2.bias", "decoder.up.0.block.0.norm1.weight", "decoder.up.0.block.0.norm1.bias", "decoder.up.0.block.0.conv1.weight", "decoder.up.0.block.0.conv1.bias", "decoder.up.0.block.0.norm2.weight", "decoder.up.0.block.0.norm2.bias", "decoder.up.0.block.0.conv2.weight", "decoder.up.0.block.0.conv2.bias", "decoder.up.0.block.0.nin_shortcut.weight", "decoder.up.0.block.0.nin_shortcut.bias", "decoder.up.0.block.1.norm1.weight", "decoder.up.0.block.1.norm1.bias", "decoder.up.0.block.1.conv1.weight", "decoder.up.0.block.1.conv1.bias", "decoder.up.0.block.1.norm2.weight", "decoder.up.0.block.1.norm2.bias", "decoder.up.0.block.1.conv2.weight", "decoder.up.0.block.1.conv2.bias", "decoder.up.0.block.2.norm1.weight", "decoder.up.0.block.2.norm1.bias", "decoder.up.0.block.2.conv1.weight", "decoder.up.0.block.2.conv1.bias", "decoder.up.0.block.2.norm2.weight", "decoder.up.0.block.2.norm2.bias", "decoder.up.0.block.2.conv2.weight", "decoder.up.0.block.2.conv2.bias", "decoder.up.1.block.0.norm1.weight", "decoder.up.1.block.0.norm1.bias", "decoder.up.1.block.0.conv1.weight", "decoder.up.1.block.0.conv1.bias", "decoder.up.1.block.0.norm2.weight", "decoder.up.1.block.0.norm2.bias", "decoder.up.1.block.0.conv2.weight", "decoder.up.1.block.0.conv2.bias", "decoder.up.1.block.0.nin_shortcut.weight", "decoder.up.1.block.0.nin_shortcut.bias", "decoder.up.1.block.1.norm1.weight", "decoder.up.1.block.1.norm1.bias", "decoder.up.1.block.1.conv1.weight", "decoder.up.1.block.1.conv1.bias", "decoder.up.1.block.1.norm2.weight", "decoder.up.1.block.1.norm2.bias", "decoder.up.1.block.1.conv2.weight", "decoder.up.1.block.1.conv2.bias", "decoder.up.1.block.2.norm1.weight", "decoder.up.1.block.2.norm1.bias", "decoder.up.1.block.2.conv1.weight", "decoder.up.1.block.2.conv1.bias", "decoder.up.1.block.2.norm2.weight", "decoder.up.1.block.2.norm2.bias", "decoder.up.1.block.2.conv2.weight", "decoder.up.1.block.2.conv2.bias", "decoder.up.1.upsample.conv.weight", "decoder.up.1.upsample.conv.bias", "decoder.up.2.block.0.norm1.weight", "decoder.up.2.block.0.norm1.bias", "decoder.up.2.block.0.conv1.weight", "decoder.up.2.block.0.conv1.bias", "decoder.up.2.block.0.norm2.weight", "decoder.up.2.block.0.norm2.bias", "decoder.up.2.block.0.conv2.weight", "decoder.up.2.block.0.conv2.bias", "decoder.up.2.block.1.norm1.weight", "decoder.up.2.block.1.norm1.bias", "decoder.up.2.block.1.conv1.weight", "decoder.up.2.block.1.conv1.bias", "decoder.up.2.block.1.norm2.weight", "decoder.up.2.block.1.norm2.bias", "decoder.up.2.block.1.conv2.weight", "decoder.up.2.block.1.conv2.bias", "decoder.up.2.block.2.norm1.weight", "decoder.up.2.block.2.norm1.bias", "decoder.up.2.block.2.conv1.weight", "decoder.up.2.block.2.conv1.bias", "decoder.up.2.block.2.norm2.weight", "decoder.up.2.block.2.norm2.bias", "decoder.up.2.block.2.conv2.weight", "decoder.up.2.block.2.conv2.bias", "decoder.up.2.upsample.conv.weight", "decoder.up.2.upsample.conv.bias", "decoder.up.3.block.0.norm1.weight", "decoder.up.3.block.0.norm1.bias", "decoder.up.3.block.0.conv1.weight", "decoder.up.3.block.0.conv1.bias", "decoder.up.3.block.0.norm2.weight", "decoder.up.3.block.0.norm2.bias", "decoder.up.3.block.0.conv2.weight", "decoder.up.3.block.0.conv2.bias", "decoder.up.3.block.1.norm1.weight", "decoder.up.3.block.1.norm1.bias", "decoder.up.3.block.1.conv1.weight", "decoder.up.3.block.1.conv1.bias", "decoder.up.3.block.1.norm2.weight", "decoder.up.3.block.1.norm2.bias", "decoder.up.3.block.1.conv2.weight", "decoder.up.3.block.1.conv2.bias", "decoder.up.3.block.2.norm1.weight", "decoder.up.3.block.2.norm1.bias", "decoder.up.3.block.2.conv1.weight", "decoder.up.3.block.2.conv1.bias", "decoder.up.3.block.2.norm2.weight", "decoder.up.3.block.2.norm2.bias", "decoder.up.3.block.2.conv2.weight", "decoder.up.3.block.2.conv2.bias", "decoder.up.3.upsample.conv.weight", "decoder.up.3.upsample.conv.bias", "decoder.norm_out.weight", "decoder.norm_out.bias", "decoder.conv_out.weight", "decoder.conv_out.bias", "quant_conv.weight", "quant_conv.bias", "post_quant_conv.weight", "post_quant_conv.bias".
Unexpected key(s) in state_dict: "model.diffusion_model.input_blocks.0.0.weight", "model.diffusion_model.input_blocks.0.0.bias", "model.diffusion_model.time_embed.0.weight", "model.diffusion_model.time_embed.0.bias", "model.diffusion_model.time_embed.2.weight", "model.diffusion_model.time_embed.2.bias", "model.diffusion_model.input_blocks.1.1.norm.weight", "model.diffusion_model.input_blocks.1.1.norm.bias", "model.diffusion_model.input_blocks.1.1.proj_in.weight", "model.diffusion_model.input_blocks.1.1.proj_in.bias", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.input_blocks.1.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.input_blocks.1.1.proj_out.weight", "model.diffusion_model.input_blocks.1.1.proj_out.bias", "model.diffusion_model.input_blocks.2.1.norm.weight", "model.diffusion_model.input_blocks.2.1.norm.bias", "model.diffusion_model.input_blocks.2.1.proj_in.weight", "model.diffusion_model.input_blocks.2.1.proj_in.bias", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.input_blocks.2.1.proj_out.weight", "model.diffusion_model.input_blocks.2.1.proj_out.bias", "model.diffusion_model.input_blocks.1.0.in_layers.0.weight", "model.diffusion_model.input_blocks.1.0.in_layers.0.bias", "model.diffusion_model.input_blocks.1.0.in_layers.2.weight", "model.diffusion_model.input_blocks.1.0.in_layers.2.bias", "model.diffusion_model.input_blocks.1.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.1.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.1.0.out_layers.0.weight", "model.diffusion_model.input_blocks.1.0.out_layers.0.bias", "model.diffusion_model.input_blocks.1.0.out_layers.3.weight", "model.diffusion_model.input_blocks.1.0.out_layers.3.bias", "model.diffusion_model.input_blocks.2.0.in_layers.0.weight", "model.diffusion_model.input_blocks.2.0.in_layers.0.bias", "model.diffusion_model.input_blocks.2.0.in_layers.2.weight", "model.diffusion_model.input_blocks.2.0.in_layers.2.bias", "model.diffusion_model.input_blocks.2.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.2.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.2.0.out_layers.0.weight", "model.diffusion_model.input_blocks.2.0.out_layers.0.bias", "model.diffusion_model.input_blocks.2.0.out_layers.3.weight", "model.diffusion_model.input_blocks.2.0.out_layers.3.bias", "model.diffusion_model.input_blocks.3.0.op.weight", "model.diffusion_model.input_blocks.3.0.op.bias", "model.diffusion_model.input_blocks.4.1.norm.weight", "model.diffusion_model.input_blocks.4.1.norm.bias", "model.diffusion_model.input_blocks.4.1.proj_in.weight", "model.diffusion_model.input_blocks.4.1.proj_in.bias", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.input_blocks.4.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.input_blocks.4.1.proj_out.weight", "model.diffusion_model.input_blocks.4.1.proj_out.bias", "model.diffusion_model.input_blocks.5.1.norm.weight", "model.diffusion_model.input_blocks.5.1.norm.bias", "model.diffusion_model.input_blocks.5.1.proj_in.weight", "model.diffusion_model.input_blocks.5.1.proj_in.bias", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.input_blocks.5.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.input_blocks.5.1.proj_out.weight", "model.diffusion_model.input_blocks.5.1.proj_out.bias", "model.diffusion_model.input_blocks.4.0.in_layers.0.weight", "model.diffusion_model.input_blocks.4.0.in_layers.0.bias", "model.diffusion_model.input_blocks.4.0.in_layers.2.weight", "model.diffusion_model.input_blocks.4.0.in_layers.2.bias", "model.diffusion_model.input_blocks.4.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.4.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.4.0.out_layers.0.weight", "model.diffusion_model.input_blocks.4.0.out_layers.0.bias", "model.diffusion_model.input_blocks.4.0.out_layers.3.weight", "model.diffusion_model.input_blocks.4.0.out_layers.3.bias", "model.diffusion_model.input_blocks.4.0.skip_connection.weight", "model.diffusion_model.input_blocks.4.0.skip_connection.bias", "model.diffusion_model.input_blocks.5.0.in_layers.0.weight", "model.diffusion_model.input_blocks.5.0.in_layers.0.bias", "model.diffusion_model.input_blocks.5.0.in_layers.2.weight", "model.diffusion_model.input_blocks.5.0.in_layers.2.bias", "model.diffusion_model.input_blocks.5.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.5.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.5.0.out_layers.0.weight", "model.diffusion_model.input_blocks.5.0.out_layers.0.bias", "model.diffusion_model.input_blocks.5.0.out_layers.3.weight", "model.diffusion_model.input_blocks.5.0.out_layers.3.bias", "model.diffusion_model.input_blocks.6.0.op.weight", "model.diffusion_model.input_blocks.6.0.op.bias", "model.diffusion_model.input_blocks.7.1.norm.weight", "model.diffusion_model.input_blocks.7.1.norm.bias", "model.diffusion_model.input_blocks.7.1.proj_in.weight", "model.diffusion_model.input_blocks.7.1.proj_in.bias", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.input_blocks.7.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.input_blocks.7.1.proj_out.weight", "model.diffusion_model.input_blocks.7.1.proj_out.bias", "model.diffusion_model.input_blocks.8.1.norm.weight", "model.diffusion_model.input_blocks.8.1.norm.bias", "model.diffusion_model.input_blocks.8.1.proj_in.weight", "model.diffusion_model.input_blocks.8.1.proj_in.bias", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.input_blocks.8.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.input_blocks.8.1.proj_out.weight", "model.diffusion_model.input_blocks.8.1.proj_out.bias", "model.diffusion_model.input_blocks.7.0.in_layers.0.weight", "model.diffusion_model.input_blocks.7.0.in_layers.0.bias", "model.diffusion_model.input_blocks.7.0.in_layers.2.weight", "model.diffusion_model.input_blocks.7.0.in_layers.2.bias", "model.diffusion_model.input_blocks.7.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.7.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.7.0.out_layers.0.weight", "model.diffusion_model.input_blocks.7.0.out_layers.0.bias", "model.diffusion_model.input_blocks.7.0.out_layers.3.weight", "model.diffusion_model.input_blocks.7.0.out_layers.3.bias", "model.diffusion_model.input_blocks.7.0.skip_connection.weight", "model.diffusion_model.input_blocks.7.0.skip_connection.bias", "model.diffusion_model.input_blocks.8.0.in_layers.0.weight", "model.diffusion_model.input_blocks.8.0.in_layers.0.bias", "model.diffusion_model.input_blocks.8.0.in_layers.2.weight", "model.diffusion_model.input_blocks.8.0.in_layers.2.bias", "model.diffusion_model.input_blocks.8.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.8.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.8.0.out_layers.0.weight", "model.diffusion_model.input_blocks.8.0.out_layers.0.bias", "model.diffusion_model.input_blocks.8.0.out_layers.3.weight", "model.diffusion_model.input_blocks.8.0.out_layers.3.bias", "model.diffusion_model.input_blocks.9.0.op.weight", "model.diffusion_model.input_blocks.9.0.op.bias", "model.diffusion_model.input_blocks.10.0.in_layers.0.weight", "model.diffusion_model.input_blocks.10.0.in_layers.0.bias", "model.diffusion_model.input_blocks.10.0.in_layers.2.weight", "model.diffusion_model.input_blocks.10.0.in_layers.2.bias", "model.diffusion_model.input_blocks.10.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.10.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.10.0.out_layers.0.weight", "model.diffusion_model.input_blocks.10.0.out_layers.0.bias", "model.diffusion_model.input_blocks.10.0.out_layers.3.weight", "model.diffusion_model.input_blocks.10.0.out_layers.3.bias", "model.diffusion_model.input_blocks.11.0.in_layers.0.weight", "model.diffusion_model.input_blocks.11.0.in_layers.0.bias", "model.diffusion_model.input_blocks.11.0.in_layers.2.weight", "model.diffusion_model.input_blocks.11.0.in_layers.2.bias", "model.diffusion_model.input_blocks.11.0.emb_layers.1.weight", "model.diffusion_model.input_blocks.11.0.emb_layers.1.bias", "model.diffusion_model.input_blocks.11.0.out_layers.0.weight", "model.diffusion_model.input_blocks.11.0.out_layers.0.bias", "model.diffusion_model.input_blocks.11.0.out_layers.3.weight", "model.diffusion_model.input_blocks.11.0.out_layers.3.bias", "model.diffusion_model.output_blocks.0.0.in_layers.0.weight", "model.diffusion_model.output_blocks.0.0.in_layers.0.bias", "model.diffusion_model.output_blocks.0.0.in_layers.2.weight", "model.diffusion_model.output_blocks.0.0.in_layers.2.bias", "model.diffusion_model.output_blocks.0.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.0.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.0.0.out_layers.0.weight", "model.diffusion_model.output_blocks.0.0.out_layers.0.bias", "model.diffusion_model.output_blocks.0.0.out_layers.3.weight", "model.diffusion_model.output_blocks.0.0.out_layers.3.bias", "model.diffusion_model.output_blocks.0.0.skip_connection.weight", "model.diffusion_model.output_blocks.0.0.skip_connection.bias", "model.diffusion_model.output_blocks.1.0.in_layers.0.weight", "model.diffusion_model.output_blocks.1.0.in_layers.0.bias", "model.diffusion_model.output_blocks.1.0.in_layers.2.weight", "model.diffusion_model.output_blocks.1.0.in_layers.2.bias", "model.diffusion_model.output_blocks.1.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.1.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.1.0.out_layers.0.weight", "model.diffusion_model.output_blocks.1.0.out_layers.0.bias", "model.diffusion_model.output_blocks.1.0.out_layers.3.weight", "model.diffusion_model.output_blocks.1.0.out_layers.3.bias", "model.diffusion_model.output_blocks.1.0.skip_connection.weight", "model.diffusion_model.output_blocks.1.0.skip_connection.bias", "model.diffusion_model.output_blocks.2.0.in_layers.0.weight", "model.diffusion_model.output_blocks.2.0.in_layers.0.bias", "model.diffusion_model.output_blocks.2.0.in_layers.2.weight", "model.diffusion_model.output_blocks.2.0.in_layers.2.bias", "model.diffusion_model.output_blocks.2.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.2.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.2.0.out_layers.0.weight", "model.diffusion_model.output_blocks.2.0.out_layers.0.bias", "model.diffusion_model.output_blocks.2.0.out_layers.3.weight", "model.diffusion_model.output_blocks.2.0.out_layers.3.bias", "model.diffusion_model.output_blocks.2.0.skip_connection.weight", "model.diffusion_model.output_blocks.2.0.skip_connection.bias", "model.diffusion_model.output_blocks.2.1.conv.weight", "model.diffusion_model.output_blocks.2.1.conv.bias", "model.diffusion_model.output_blocks.3.1.norm.weight", "model.diffusion_model.output_blocks.3.1.norm.bias", "model.diffusion_model.output_blocks.3.1.proj_in.weight", "model.diffusion_model.output_blocks.3.1.proj_in.bias", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.3.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.3.1.proj_out.weight", "model.diffusion_model.output_blocks.3.1.proj_out.bias", "model.diffusion_model.output_blocks.4.1.norm.weight", "model.diffusion_model.output_blocks.4.1.norm.bias", "model.diffusion_model.output_blocks.4.1.proj_in.weight", "model.diffusion_model.output_blocks.4.1.proj_in.bias", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.4.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.4.1.proj_out.weight", "model.diffusion_model.output_blocks.4.1.proj_out.bias", "model.diffusion_model.output_blocks.5.1.norm.weight", "model.diffusion_model.output_blocks.5.1.norm.bias", "model.diffusion_model.output_blocks.5.1.proj_in.weight", "model.diffusion_model.output_blocks.5.1.proj_in.bias", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.5.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.5.1.proj_out.weight", "model.diffusion_model.output_blocks.5.1.proj_out.bias", "model.diffusion_model.output_blocks.3.0.in_layers.0.weight", "model.diffusion_model.output_blocks.3.0.in_layers.0.bias", "model.diffusion_model.output_blocks.3.0.in_layers.2.weight", "model.diffusion_model.output_blocks.3.0.in_layers.2.bias", "model.diffusion_model.output_blocks.3.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.3.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.3.0.out_layers.0.weight", "model.diffusion_model.output_blocks.3.0.out_layers.0.bias", "model.diffusion_model.output_blocks.3.0.out_layers.3.weight", "model.diffusion_model.output_blocks.3.0.out_layers.3.bias", "model.diffusion_model.output_blocks.3.0.skip_connection.weight", "model.diffusion_model.output_blocks.3.0.skip_connection.bias", "model.diffusion_model.output_blocks.4.0.in_layers.0.weight", "model.diffusion_model.output_blocks.4.0.in_layers.0.bias", "model.diffusion_model.output_blocks.4.0.in_layers.2.weight", "model.diffusion_model.output_blocks.4.0.in_layers.2.bias", "model.diffusion_model.output_blocks.4.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.4.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.4.0.out_layers.0.weight", "model.diffusion_model.output_blocks.4.0.out_layers.0.bias", "model.diffusion_model.output_blocks.4.0.out_layers.3.weight", "model.diffusion_model.output_blocks.4.0.out_layers.3.bias", "model.diffusion_model.output_blocks.4.0.skip_connection.weight", "model.diffusion_model.output_blocks.4.0.skip_connection.bias", "model.diffusion_model.output_blocks.5.0.in_layers.0.weight", "model.diffusion_model.output_blocks.5.0.in_layers.0.bias", "model.diffusion_model.output_blocks.5.0.in_layers.2.weight", "model.diffusion_model.output_blocks.5.0.in_layers.2.bias", "model.diffusion_model.output_blocks.5.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.5.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.5.0.out_layers.0.weight", "model.diffusion_model.output_blocks.5.0.out_layers.0.bias", "model.diffusion_model.output_blocks.5.0.out_layers.3.weight", "model.diffusion_model.output_blocks.5.0.out_layers.3.bias", "model.diffusion_model.output_blocks.5.0.skip_connection.weight", "model.diffusion_model.output_blocks.5.0.skip_connection.bias", "model.diffusion_model.output_blocks.5.2.conv.weight", "model.diffusion_model.output_blocks.5.2.conv.bias", "model.diffusion_model.output_blocks.6.1.norm.weight", "model.diffusion_model.output_blocks.6.1.norm.bias", "model.diffusion_model.output_blocks.6.1.proj_in.weight", "model.diffusion_model.output_blocks.6.1.proj_in.bias", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.6.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.6.1.proj_out.weight", "model.diffusion_model.output_blocks.6.1.proj_out.bias", "model.diffusion_model.output_blocks.7.1.norm.weight", "model.diffusion_model.output_blocks.7.1.norm.bias", "model.diffusion_model.output_blocks.7.1.proj_in.weight", "model.diffusion_model.output_blocks.7.1.proj_in.bias", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.7.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.7.1.proj_out.weight", "model.diffusion_model.output_blocks.7.1.proj_out.bias", "model.diffusion_model.output_blocks.8.1.norm.weight", "model.diffusion_model.output_blocks.8.1.norm.bias", "model.diffusion_model.output_blocks.8.1.proj_in.weight", "model.diffusion_model.output_blocks.8.1.proj_in.bias", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.8.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.8.1.proj_out.weight", "model.diffusion_model.output_blocks.8.1.proj_out.bias", "model.diffusion_model.output_blocks.6.0.in_layers.0.weight", "model.diffusion_model.output_blocks.6.0.in_layers.0.bias", "model.diffusion_model.output_blocks.6.0.in_layers.2.weight", "model.diffusion_model.output_blocks.6.0.in_layers.2.bias", "model.diffusion_model.output_blocks.6.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.6.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.6.0.out_layers.0.weight", "model.diffusion_model.output_blocks.6.0.out_layers.0.bias", "model.diffusion_model.output_blocks.6.0.out_layers.3.weight", "model.diffusion_model.output_blocks.6.0.out_layers.3.bias", "model.diffusion_model.output_blocks.6.0.skip_connection.weight", "model.diffusion_model.output_blocks.6.0.skip_connection.bias", "model.diffusion_model.output_blocks.7.0.in_layers.0.weight", "model.diffusion_model.output_blocks.7.0.in_layers.0.bias", "model.diffusion_model.output_blocks.7.0.in_layers.2.weight", "model.diffusion_model.output_blocks.7.0.in_layers.2.bias", "model.diffusion_model.output_blocks.7.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.7.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.7.0.out_layers.0.weight", "model.diffusion_model.output_blocks.7.0.out_layers.0.bias", "model.diffusion_model.output_blocks.7.0.out_layers.3.weight", "model.diffusion_model.output_blocks.7.0.out_layers.3.bias", "model.diffusion_model.output_blocks.7.0.skip_connection.weight", "model.diffusion_model.output_blocks.7.0.skip_connection.bias", "model.diffusion_model.output_blocks.8.0.in_layers.0.weight", "model.diffusion_model.output_blocks.8.0.in_layers.0.bias", "model.diffusion_model.output_blocks.8.0.in_layers.2.weight", "model.diffusion_model.output_blocks.8.0.in_layers.2.bias", "model.diffusion_model.output_blocks.8.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.8.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.8.0.out_layers.0.weight", "model.diffusion_model.output_blocks.8.0.out_layers.0.bias", "model.diffusion_model.output_blocks.8.0.out_layers.3.weight", "model.diffusion_model.output_blocks.8.0.out_layers.3.bias", "model.diffusion_model.output_blocks.8.0.skip_connection.weight", "model.diffusion_model.output_blocks.8.0.skip_connection.bias", "model.diffusion_model.output_blocks.8.2.conv.weight", "model.diffusion_model.output_blocks.8.2.conv.bias", "model.diffusion_model.output_blocks.9.1.norm.weight", "model.diffusion_model.output_blocks.9.1.norm.bias", "model.diffusion_model.output_blocks.9.1.proj_in.weight", "model.diffusion_model.output_blocks.9.1.proj_in.bias", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.9.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.9.1.proj_out.weight", "model.diffusion_model.output_blocks.9.1.proj_out.bias", "model.diffusion_model.output_blocks.10.1.norm.weight", "model.diffusion_model.output_blocks.10.1.norm.bias", "model.diffusion_model.output_blocks.10.1.proj_in.weight", "model.diffusion_model.output_blocks.10.1.proj_in.bias", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.10.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.10.1.proj_out.weight", "model.diffusion_model.output_blocks.10.1.proj_out.bias", "model.diffusion_model.output_blocks.11.1.norm.weight", "model.diffusion_model.output_blocks.11.1.norm.bias", "model.diffusion_model.output_blocks.11.1.proj_in.weight", "model.diffusion_model.output_blocks.11.1.proj_in.bias", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.output_blocks.11.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.output_blocks.11.1.proj_out.weight", "model.diffusion_model.output_blocks.11.1.proj_out.bias", "model.diffusion_model.output_blocks.9.0.in_layers.0.weight", "model.diffusion_model.output_blocks.9.0.in_layers.0.bias", "model.diffusion_model.output_blocks.9.0.in_layers.2.weight", "model.diffusion_model.output_blocks.9.0.in_layers.2.bias", "model.diffusion_model.output_blocks.9.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.9.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.9.0.out_layers.0.weight", "model.diffusion_model.output_blocks.9.0.out_layers.0.bias", "model.diffusion_model.output_blocks.9.0.out_layers.3.weight", "model.diffusion_model.output_blocks.9.0.out_layers.3.bias", "model.diffusion_model.output_blocks.9.0.skip_connection.weight", "model.diffusion_model.output_blocks.9.0.skip_connection.bias", "model.diffusion_model.output_blocks.10.0.in_layers.0.weight", "model.diffusion_model.output_blocks.10.0.in_layers.0.bias", "model.diffusion_model.output_blocks.10.0.in_layers.2.weight", "model.diffusion_model.output_blocks.10.0.in_layers.2.bias", "model.diffusion_model.output_blocks.10.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.10.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.10.0.out_layers.0.weight", "model.diffusion_model.output_blocks.10.0.out_layers.0.bias", "model.diffusion_model.output_blocks.10.0.out_layers.3.weight", "model.diffusion_model.output_blocks.10.0.out_layers.3.bias", "model.diffusion_model.output_blocks.10.0.skip_connection.weight", "model.diffusion_model.output_blocks.10.0.skip_connection.bias", "model.diffusion_model.output_blocks.11.0.in_layers.0.weight", "model.diffusion_model.output_blocks.11.0.in_layers.0.bias", "model.diffusion_model.output_blocks.11.0.in_layers.2.weight", "model.diffusion_model.output_blocks.11.0.in_layers.2.bias", "model.diffusion_model.output_blocks.11.0.emb_layers.1.weight", "model.diffusion_model.output_blocks.11.0.emb_layers.1.bias", "model.diffusion_model.output_blocks.11.0.out_layers.0.weight", "model.diffusion_model.output_blocks.11.0.out_layers.0.bias", "model.diffusion_model.output_blocks.11.0.out_layers.3.weight", "model.diffusion_model.output_blocks.11.0.out_layers.3.bias", "model.diffusion_model.output_blocks.11.0.skip_connection.weight", "model.diffusion_model.output_blocks.11.0.skip_connection.bias", "model.diffusion_model.middle_block.1.norm.weight", "model.diffusion_model.middle_block.1.norm.bias", "model.diffusion_model.middle_block.1.proj_in.weight", "model.diffusion_model.middle_block.1.proj_in.bias", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn1.to_q.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn1.to_k.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn1.to_v.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn1.to_out.0.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn1.to_out.0.bias", "model.diffusion_model.middle_block.1.transformer_blocks.0.ff.net.0.proj.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.ff.net.0.proj.bias", "model.diffusion_model.middle_block.1.transformer_blocks.0.ff.net.2.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.ff.net.2.bias", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_q.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_k.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_v.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_out.0.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.attn2.to_out.0.bias", "model.diffusion_model.middle_block.1.transformer_blocks.0.norm1.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.norm1.bias", "model.diffusion_model.middle_block.1.transformer_blocks.0.norm2.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.norm2.bias", "model.diffusion_model.middle_block.1.transformer_blocks.0.norm3.weight", "model.diffusion_model.middle_block.1.transformer_blocks.0.norm3.bias", "model.diffusion_model.middle_block.1.proj_out.weight", "model.diffusion_model.middle_block.1.proj_out.bias", "model.diffusion_model.middle_block.0.in_layers.0.weight", "model.diffusion_model.middle_block.0.in_layers.0.bias", "model.diffusion_model.middle_block.0.in_layers.2.weight", "model.diffusion_model.middle_block.0.in_layers.2.bias", "model.diffusion_model.middle_block.0.emb_layers.1.weight", "model.diffusion_model.middle_block.0.emb_layers.1.bias", "model.diffusion_model.middle_block.0.out_layers.0.weight", "model.diffusion_model.middle_block.0.out_layers.0.bias", "model.diffusion_model.middle_block.0.out_layers.3.weight", "model.diffusion_model.middle_block.0.out_layers.3.bias", "model.diffusion_model.middle_block.2.in_layers.0.weight", "model.diffusion_model.middle_block.2.in_layers.0.bias", "model.diffusion_model.middle_block.2.in_layers.2.weight", "model.diffusion_model.middle_block.2.in_layers.2.bias", "model.diffusion_model.middle_block.2.emb_layers.1.weight", "model.diffusion_model.middle_block.2.emb_layers.1.bias", "model.diffusion_model.middle_block.2.out_layers.0.weight", "model.diffusion_model.middle_block.2.out_layers.0.bias", "model.diffusion_model.middle_block.2.out_layers.3.weight", "model.diffusion_model.middle_block.2.out_layers.3.bias", "model.diffusion_model.out.0.weight", "model.diffusion_model.out.0.bias", "model.diffusion_model.out.2.weight", "model.diffusion_model.out.2.bias", "first_stage_model.encoder.conv_in.weight", "first_stage_model.encoder.conv_in.bias", "first_stage_model.encoder.down.0.block.0.norm1.weight", "first_stage_model.encoder.down.0.block.0.norm1.bias", "first_stage_model.encoder.down.0.block.0.conv1.weight", "first_stage_model.encoder.down.0.block.0.conv1.bias", "first_stage_model.encoder.down.0.block.0.norm2.weight", "first_stage_model.encoder.down.0.block.0.norm2.bias", "first_stage_model.encoder.down.0.block.0.conv2.weight", "first_stage_model.encoder.down.0.block.0.conv2.bias", "first_stage_model.encoder.down.0.block.1.norm1.weight", "first_stage_model.encoder.down.0.block.1.norm1.bias", "first_stage_model.encoder.down.0.block.1.conv1.weight", "first_stage_model.encoder.down.0.block.1.conv1.bias", "first_stage_model.encoder.down.0.block.1.norm2.weight", "first_stage_model.encoder.down.0.block.1.norm2.bias", "first_stage_model.encoder.down.0.block.1.conv2.weight", "first_stage_model.encoder.down.0.block.1.conv2.bias", "first_stage_model.encoder.down.0.downsample.conv.weight", "first_stage_model.encoder.down.0.downsample.conv.bias", "first_stage_model.encoder.down.1.block.0.norm1.weight", "first_stage_model.encoder.down.1.block.0.norm1.bias", "first_stage_model.encoder.down.1.block.0.conv1.weight", "first_stage_model.encoder.down.1.block.0.conv1.bias", "first_stage_model.encoder.down.1.block.0.norm2.weight", "first_stage_model.encoder.down.1.block.0.norm2.bias", "first_stage_model.encoder.down.1.block.0.conv2.weight", "first_stage_model.encoder.down.1.block.0.conv2.bias", "first_stage_model.encoder.down.1.block.0.nin_shortcut.weight", "first_stage_model.encoder.down.1.block.0.nin_shortcut.bias", "first_stage_model.encoder.down.1.block.1.norm1.weight", "first_stage_model.encoder.down.1.block.1.norm1.bias", "first_stage_model.encoder.down.1.block.1.conv1.weight", "first_stage_model.encoder.down.1.block.1.conv1.bias", "first_stage_model.encoder.down.1.block.1.norm2.weight", "first_stage_model.encoder.down.1.block.1.norm2.bias", "first_stage_model.encoder.down.1.block.1.conv2.weight", "first_stage_model.encoder.down.1.block.1.conv2.bias", "first_stage_model.encoder.down.1.downsample.conv.weight", "first_stage_model.encoder.down.1.downsample.conv.bias", "first_stage_model.encoder.down.2.block.0.norm1.weight", "first_stage_model.encoder.down.2.block.0.norm1.bias", "first_stage_model.encoder.down.2.block.0.conv1.weight", "first_stage_model.encoder.down.2.block.0.conv1.bias", "first_stage_model.encoder.down.2.block.0.norm2.weight", "first_stage_model.encoder.down.2.block.0.norm2.bias", "first_stage_model.encoder.down.2.block.0.conv2.weight", "first_stage_model.encoder.down.2.block.0.conv2.bias", "first_stage_model.encoder.down.2.block.0.nin_shortcut.weight", "first_stage_model.encoder.down.2.block.0.nin_shortcut.bias", "first_stage_model.encoder.down.2.block.1.norm1.weight", "first_stage_model.encoder.down.2.block.1.norm1.bias", "first_stage_model.encoder.down.2.block.1.conv1.weight", "first_stage_model.encoder.down.2.block.1.conv1.bias", "first_stage_model.encoder.down.2.block.1.norm2.weight", "first_stage_model.encoder.down.2.block.1.norm2.bias", "first_stage_model.encoder.down.2.block.1.conv2.weight", "first_stage_model.encoder.down.2.block.1.conv2.bias", "first_stage_model.encoder.down.2.downsample.conv.weight", "first_stage_model.encoder.down.2.downsample.conv.bias", "first_stage_model.encoder.down.3.block.0.norm1.weight", "first_stage_model.encoder.down.3.block.0.norm1.bias", "first_stage_model.encoder.down.3.block.0.conv1.weight", "first_stage_model.encoder.down.3.block.0.conv1.bias", "first_stage_model.encoder.down.3.block.0.norm2.weight", "first_stage_model.encoder.down.3.block.0.norm2.bias", "first_stage_model.encoder.down.3.block.0.conv2.weight", "first_stage_model.encoder.down.3.block.0.conv2.bias", "first_stage_model.encoder.down.3.block.1.norm1.weight", "first_stage_model.encoder.down.3.block.1.norm1.bias", "first_stage_model.encoder.down.3.block.1.conv1.weight", "first_stage_model.encoder.down.3.block.1.conv1.bias", "first_stage_model.encoder.down.3.block.1.norm2.weight", "first_stage_model.encoder.down.3.block.1.norm2.bias", "first_stage_model.encoder.down.3.block.1.conv2.weight", "first_stage_model.encoder.down.3.block.1.conv2.bias", "first_stage_model.encoder.mid.attn_1.norm.weight", "first_stage_model.encoder.mid.attn_1.norm.bias", "first_stage_model.encoder.mid.attn_1.q.weight", "first_stage_model.encoder.mid.attn_1.q.bias", "first_stage_model.encoder.mid.attn_1.k.weight", "first_stage_model.encoder.mid.attn_1.k.bias", "first_stage_model.encoder.mid.attn_1.v.weight", "first_stage_model.encoder.mid.attn_1.v.bias", "first_stage_model.encoder.mid.attn_1.proj_out.weight", "first_stage_model.encoder.mid.attn_1.proj_out.bias", "first_stage_model.encoder.mid.block_1.norm1.weight", "first_stage_model.encoder.mid.block_1.norm1.bias",
...