OntoED: A Model for Low-resource Event Detection with Ontology Embedding
🍎 The project is an official implementation for OntoED model and a repository for OntoEvent dataset, which has firstly been proposed in the paper OntoED: Low-resource Event Detection with Ontology Embedding accepted by ACL 2021.
🤗 The implementations are based on Huggingface's Transformers and remanagement is referred to MAVEN's baselines & DeepKE.
🤗 We also provide some baseline implementations for reproduction.
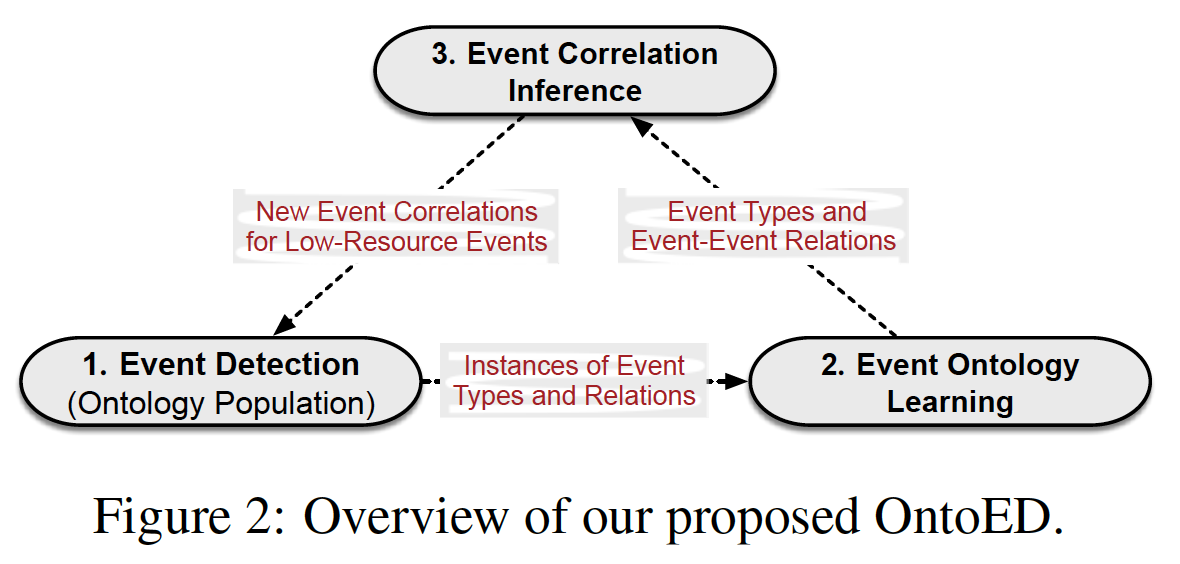
OntoED is a model that resolves event detection under low-resource conditions. It models the relationship between event types through ontology embedding: it can transfer knowledge of high-resource event types to low-resource ones, and the unseen event type can establish connection with seen ones via event ontology.
The structure of data and code is as follows:
Reasoning_In_EE
├── README.md
├── OntoED # model
│ ├── README.md
│ ├── data_utils.py # for data processing
│ ├── ontoed.py # main model
│ ├── run_ontoed.py # for model running
│ └── run_ontoed.sh # bash file for model running
├── OntoEvent # data
│ ├── README.md
│ ├── __init__.py
│ ├── event_dict_data_on_doc.json.zip # raw full ED data
│ ├── event_dict_train_data.json # ED data for training
│ ├── event_dict_test_data.json # ED data for testing
│ ├── event_dict_valid_data.json # ED data for validation
│ └── event_relation.json # event-event relation data
└── baselines # baseline models
├── DMCNN
│ ├── README.md
│ ├── convert.py # for data processing
│ ├── data # data
│ │ └── labels.json
│ ├── dmcnn.config # configure training & testing
│ ├── eval.sh # bash file for model evaluation
│ ├── formatter
│ │ ├── DmcnnFormatter.py # runtime data processing
│ │ └── __init__.py
│ ├── main.py # project entrance
│ ├── model
│ │ ├── Dmcnn.py # main model
│ │ └── __init__.py
│ ├── raw
│ │ └── 100.utf8 # word vector
│ ├── reader
│ │ ├── MavenReader.py # runtime data reader
│ │ └── __init__.py
│ ├── requirements.txt # requirements
│ ├── train.sh # bash file for model training
│ └── utils
│ ├── __init__.py
│ ├── configparser_hook.py
│ ├── evaluation.py
│ ├── global_variables.py
│ ├── initializer.py
│ └── runner.py
├── JMEE
│ ├── README.md
│ ├── data # to store data file
│ ├── enet
│ │ ├── __init__.py
│ │ ├── consts.py # configurable parameters
│ │ ├── corpus
│ │ │ ├── Corpus.py # dataset class
│ │ │ ├── Data.py
│ │ │ ├── Sentence.py
│ │ │ └── __init__.py
│ │ ├── models # modules of JMEE
│ │ │ ├── DynamicLSTM.py
│ │ │ ├── EmbeddingLayer.py
│ │ │ ├── GCN.py
│ │ │ ├── HighWay.py
│ │ │ ├── SelfAttention.py
│ │ │ ├── __init__.py
│ │ │ ├── ee.py
│ │ │ └── model.py # main model
│ │ ├── run
│ │ │ ├── __init__.py
│ │ │ └── ee
│ │ │ ├── __init__.py
│ │ │ └── runner.py # runner class
│ │ ├── testing.py # evaluation
│ │ ├── training.py # training
│ │ └── util.py
│ ├── eval.sh # bash file for model evaluation
│ ├── requirements.txt # requirements
│ └── train.sh # bash file for model training
├── README.md
├── eq1.png
├── eq2.png
├── jointEE-NN
│ ├── README.md
│ ├── data
│ │ └── fistDoc.nnData4.txt # data format sample
│ ├── evaluateJEE.py # model evaluation
│ ├── jeeModels.py # main model
│ ├── jee_processData.py # data process
│ └── jointEE.py # project entrance
└── stanford.zip # cleaned dataset for baseline models-
python==3.6.9
-
torch==1.8.0 (lower may also be OK)
-
transformers==2.8.0
-
sklearn==0.20.2
1. Project Preparation:Download this project and unzip the dataset. You can directly download the archive, or run git clone https://github.com/231sm/Reasoning_In_EE.git at your teminal.
cd [LOCAL_PROJECT_PATH]
git clone https://github.com/231sm/Reasoning_In_EE.git
2. Running Preparation: Adjust the parameters in run_ontoed.sh bash file, and input the true path of 'LABEL_PATH' and 'RELATION_PATH' at the end of data_utils.py.
cd Reasoning_In_EE/OntoED
vim run_ontoed.sh
(input the parameters, save and quit)
vim data_utils.py
(input the path of 'LABEL_PATH' and 'RELATION_PATH', save and quit)
Hint:
- Please refer to
main()function inrun_ontoed.pyfile for detail meanings of each parameters. - 'LABEL_PATH' and 'RELATION_PATH' means the path for event_dict_train_data.json and event_relation.json respectively.
3. Running Model: Run ./run_ontoed.sh for training, validation, and testing.
A folder with configuration, models weights, and results (in is_test_true_eval_results.txt) will be saved at the path you input ('--output_dir') in the bash file run_ontoed.sh.
cd Reasoning_In_EE/OntoED
./run_ontoed.sh
('--do_train', '--do_eval', '--evaluate_during_training', '--do_test' is necessarily input in 'run_ontoed.sh')
Or you can run run_ontoed.py with manual parameter input (parameters can be copied from 'run_ontoed.sh')
python run_ontoed.py --para...
OntoEvent is proposed for ED and also annotated with correlations among events. It contains 13 supertypes with 100 subtypes, derived from 4,115 documents with 60,546 event instances. Please refer to OntoEvent for details.
The statistics of OntoEvent are shown below, and the detailed data schema can be referred to our paper.
| Dataset | #Doc | #Instance | #SuperType | #SubType | #EventCorrelation |
|---|---|---|---|---|---|
| ACE 2005 | 599 | 4,090 | 8 | 33 | None |
| TAC KBP 2017 | 167 | 4,839 | 8 | 18 | None |
| FewEvent | - | 70,852 | 19 | 100 | None |
| MAVEN | 4,480 | 111,611 | 21 | 168 | None |
| OntoEvent | 4,115 | 60,546 | 13 | 100 | 3,804 |
The OntoEvent dataset is stored in json format.
🍒For each event instance in event_dict_data_on_doc.json, the data format is as below:
{
'doc_id': '...',
'doc_title': 'XXX',
'sent_id': ,
'event_mention': '......',
'event_mention_tokens': ['.', '.', '.', '.', '.', '.'],
'trigger': '...',
'trigger_pos': [, ],
'event_type': ''
}
🍒For each event relation in event_relation.json, we list the event instance pair, and the data format is as below:
'EVENT_RELATION_1': [
[
{
'doc_id': '...',
'doc_title': 'XXX',
'sent_id': ,
'event_mention': '......',
'event_mention_tokens': ['.', '.', '.', '.', '.', '.'],
'trigger': '...',
'trigger_pos': [, ],
'event_type': ''
},
{
'doc_id': '...',
'doc_title': 'XXX',
'sent_id': ,
'event_mention': '......',
'event_mention_tokens': ['.', '.', '.', '.', '.', '.'],
'trigger': '...',
'trigger_pos': [, ],
'event_type': ''
}
],
...
]
🍒Especially for "COSUPER", "SUBSUPER" and "SUPERSUB", we list the event type pair, and the data format is as below:
"COSUPER": [
["Conflict.Attack", "Conflict.Protest"],
["Conflict.Attack", "Conflict.Sending"],
...
]
📋 Thank you very much for your interest in our work. If you use or extend our work, please cite the following paper:
@inproceedings{ACL2021_OntoED,
title = "{O}nto{ED}: Low-resource Event Detection with Ontology Embedding",
author = "Deng, Shumin and
Zhang, Ningyu and
Li, Luoqiu and
Hui, Chen and
Huaixiao, Tou and
Chen, Mosha and
Huang, Fei and
Chen, Huajun",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.220",
doi = "10.18653/v1/2021.acl-long.220",
pages = "2828--2839"
}