由于最近针对chia做了一次修改,所以对chia进行了一些研究,梳理一下,共同研究
sk: 私钥
pk: 公钥,可以通过私钥获取
chia的账户(地址)采用的是bls算法,同时支持HD钱包。
通过24个单词的助记词生成主私钥 master_sk ,同时会派生几个私钥:
1. farmer_sk 对应HD路径: m/12381/8444/0/0
2. pool_sk 对应HD路径: m/12381/8444/1/0
3. wallet_sk 对应HD路径: m/12381/8444/2/0
- bls 一个支持多签验证的加密算法
// 签名
sig1 = Sign(sk1, msg1)
sig2 = Sign(sk2, msg2)
aggSig = Aggregate(sig1, sig2)
// 验证
Verify((pk1, pk2), (msg1, msg2), aggSig)
官方原图

plotId有两种组成方式, 官方图如下:
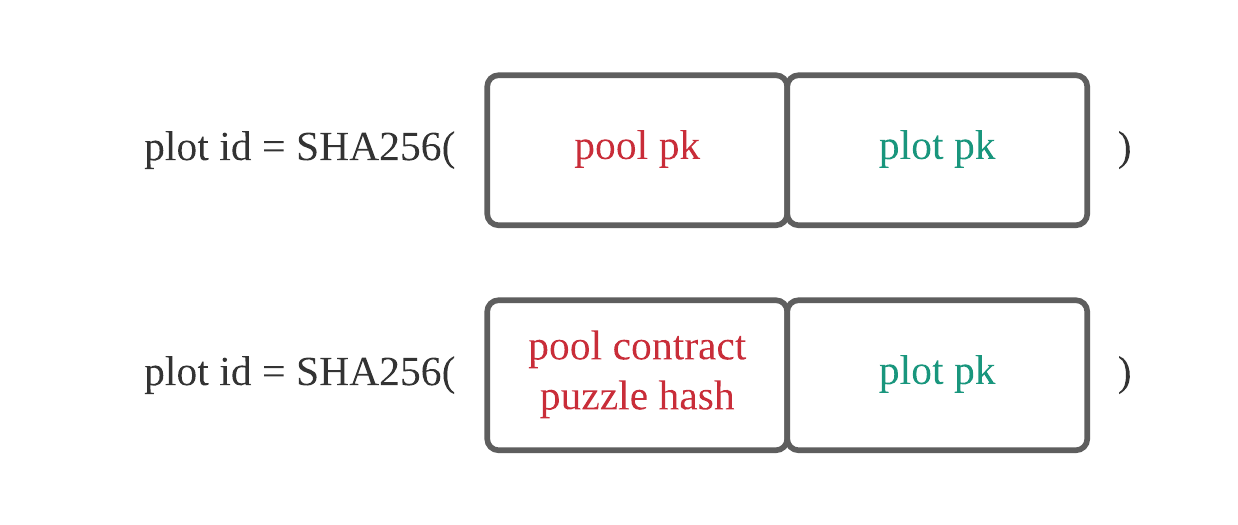
第一种:
- plotId 由 poolPk 和 plotPk 组成
- plotPk 由 (localPk + farmerPk) 组成
- poolPk 是写在plot文件中的,如果没有指定,则会使用默认(生成的第一个masterSk对应的poolPk)
第二种:
- plotId 由 poolContract 和 plotPk 组成
- 此模式下通过合约控制
ps:
签名区块的时候需要获取的3个key(poolPk,farmerPk,localSk)的位置
是固定的(通过get_memo()可以获取到),所以,理论上可以修改plot的poolPk和farmerPk
localSk是每个plot文件随机生成的私钥,只存在于plot文件中,使用时,会通过解析plot的头部信息,进行获取
- p盘时使用 poolPk 和 famrerPk,默认使用系统的第一个masterSk派生,同时需要指定k的大小
- k控制文件大小,主网允许的最小k=32(101.4GIB, GIB是1024进制,GB是10进制),文件大小的计算公式为 size = 780*k**2(k-10)
此处记录了 pool_public_key(48) or puzzle_hash(32), farmer_public_key(48), local_master_sk(32)
官方图

- plot文件由7个表(table)组成,每个表有2**k的实体,2到7的表里每个实体有2个指针,指向前一个表的实体。
表1的每个实体有一个整数对(0-2**k, 0-2**k),称为 x-values
- pos的证明是64个x-values的集合
- 证明从第7个表开始,从一个实体出发(具体是哪个实体是根据挑战选择的,后面会说到),通过实体的2个指针
继续查找后面的表,最终会形成两棵树(因为一个实体有两个指针),树的最低层是表1对应的x-values,
总共有64个x-values(2**7 <- 2**6 <- 2**5 <- 2**4 <- 2**3 <- 2**2 <- 2**1)
- 读取的数据量很小,官方数据每次实体的读取在10ms左右,到了表1需要640ms,因为要读64次
- 为了优化检索过程,只分别检索两棵树的1个分支(具体哪个分支取决于挑战hash),最终会得到两个x-values
- 然后计算 quality_str = hash(两个x-values), quality_str
- 然后计算 required_iters = calculate_iterations_quality(
self.harvester.constants.DIFFICULTY_CONSTANT_FACTOR, // 配置文件的值
quality_str, // 上面的quality_str
plot_info.prover.get_size(), // k
new_challenge.difficulty, // 难度
new_challenge.sp_hash, // singage point hash 后面讨论
)
- 如果返回的required_iters 小于一定的大小(sub_slot_iters/64), 则再去获取整一个证明,
这样就会减少磁盘读取,每个分支只需要7次搜索和读取,总共需要14次,大约140ms
ps:
这里没有说challenge是怎么来的,并且是怎么在第7个表里开始的。
源码里的challenge是signage_point_challenge,由plot_id, signage_point_hash, challenge_hash计算
而来,随后通过prover.get_qualities_for_challenge(sp_challenge_hash)获取
quality_strings
在进行查找答案之前,会先通过一层过滤,目的是过滤掉大多plot,使他们不用扫描plot,当然也没有收益😂
具体算法是 hash(challenge+plot_id), 如果得到的字符串的前n(配置文件修改)位都是0,则他们有资格扫描plot
进行搜索答案
由于上面的plotId有两种组成,所以存在两种挖矿方式:
1. farm to pool public key,通过poolPk挖矿
- 此模式下
- plot的奖励地址(target_reward_address)必须使用poolSk进行签名
- 未完成的区块(unfinished_block)必须通过farmerSk和localSk的多重签名才能有效
- 代码里是先通过harvester进行localSk签名,再通过farmer进行farmerSk签名,然后进行多签验证。
最后通过pookPk进行验证奖励地址
- 目前矿池采用这种方式,首先需要用户签名授权矿池地址(用户的poolSk签名矿池地址),然后
在多重签名的地方做一些流程修改
- 当多机部署时,由于harvester只存储了localSk,所以即使收到攻击,也不会修改奖励地址
2. farm to pool contract puzzle hash(官方暂未开放 截止2021-04-28)
chia的共识依赖vdf