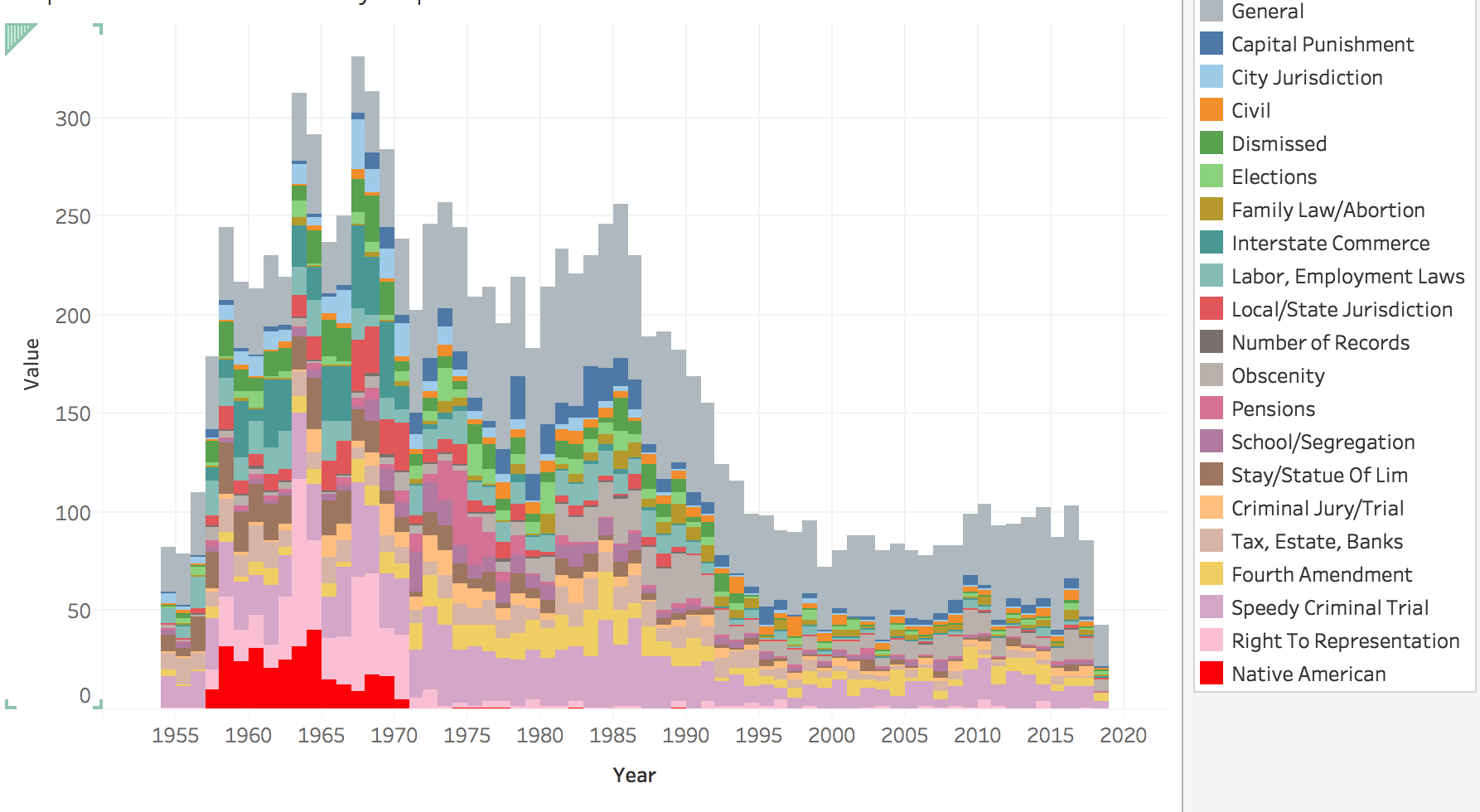
For this project I used Natural Language Processing and unsupervised learning to preform topic modeling on supreme court cases/opinions.
The tools I used were NLTK, sklearn and spacey, as well as beautiful soup for webscraping. I scraped the site https://caselaw.findlaw.com/court/us-supreme-court/ to get all the opinions over the history of the US supreme court. My original intent was to find which supreme court justices were most similar to each other, but my model mainly just picked out the various topics that they wrote about (for example fourth amendment cases, sixth amendment cases, labor laws, etc.) so I pivoted my focus to do topic modeling on the various cases. Due to the large amount of "legalese" in the documents, my model often had a hard time differentiating the cases, so I ended up with one large miscellaneous group (or topic).
These notebooks will take you through my process.
first I scraped wikipedia to the name of all the justices.
then I scraped the site caselaw.findlaw.com to get the link to each individual case on that site, then grabbed the text of the opinions from each link.
I pulled out the name of each case and divided them between justices --since each case often had multiple justices writing opinions: majority opinion, concurring opinions and dissenting opinions.
The next two notebooks are very similar, the first is topic modeling cases from the last 60 years, and then topic modeling all cases from the beginning of the court to present.
Then I used my seperated-by-justice documents to see which justices were similar and what topics (from the topic modeling) they wrote about each year.
the last notebook I just used to do some visualization. I used that to save a csv which I put into Tableau so the visualization process is not actually in that notebook.