Learning to Cluster Faces on an Affinity Graph, CVPR 2019 (Oral) [Project Page]
Install dependencies
conda install pytorch=0.4.1 cuda90 -c pytorch
conda install faiss-gpu -c pytorch
pip install -r requirements.txtDownload 1 part testing data from Google Drive or BaiduYun (passwd: yhhe).
or with scripts below:
python tools/download_data.pydata
├── features
├── part0_train.bin # acbbc780948e7bfaaee093ef9fce2ccb
├── part1_test.bin # ced42d80046d75ead82ae5c2cdfba621
├── labels
├── part0_train.meta # 8573, 576494
├── part1_test.meta # 8573, 584013
├── knns
├── part0_train/faiss_k_80.npz # 5e4f6c06daf8d29c9b940a851f28a925
├── part1_test/faiss_k_80.npz # d4a7f95b09f80b0167d893f2ca0f5be5
├── pretrained_models
├── pretrained_gcn_d.pth.tar # 213598e70ddbc50f5e3661a6191a8be1
Download entire benchmarks data (including above one) from GoogleDrive or OneDrive. The folder structure is the same as the data above.
[Optional] Download precomputed knns from
OneDrive
and move it to data folder.
It can save a lot of time to search knn, especially in the large setting.
[Optional] Download the splitted image list from GoogleDrive or OneDrive. You can train your own feature extractor with the list.
[Optional] Download YTBFace data from GoogleDrive or OneDrive.
Fetch code & Create soft link
git clone [email protected]:yl-1993/learn-to-cluster.git
cd learn-to-cluster
ln -s xxx/data dataRun
sh scripts/pipeline.shThe scripts/pipeline.sh can be decomposed into following steps:
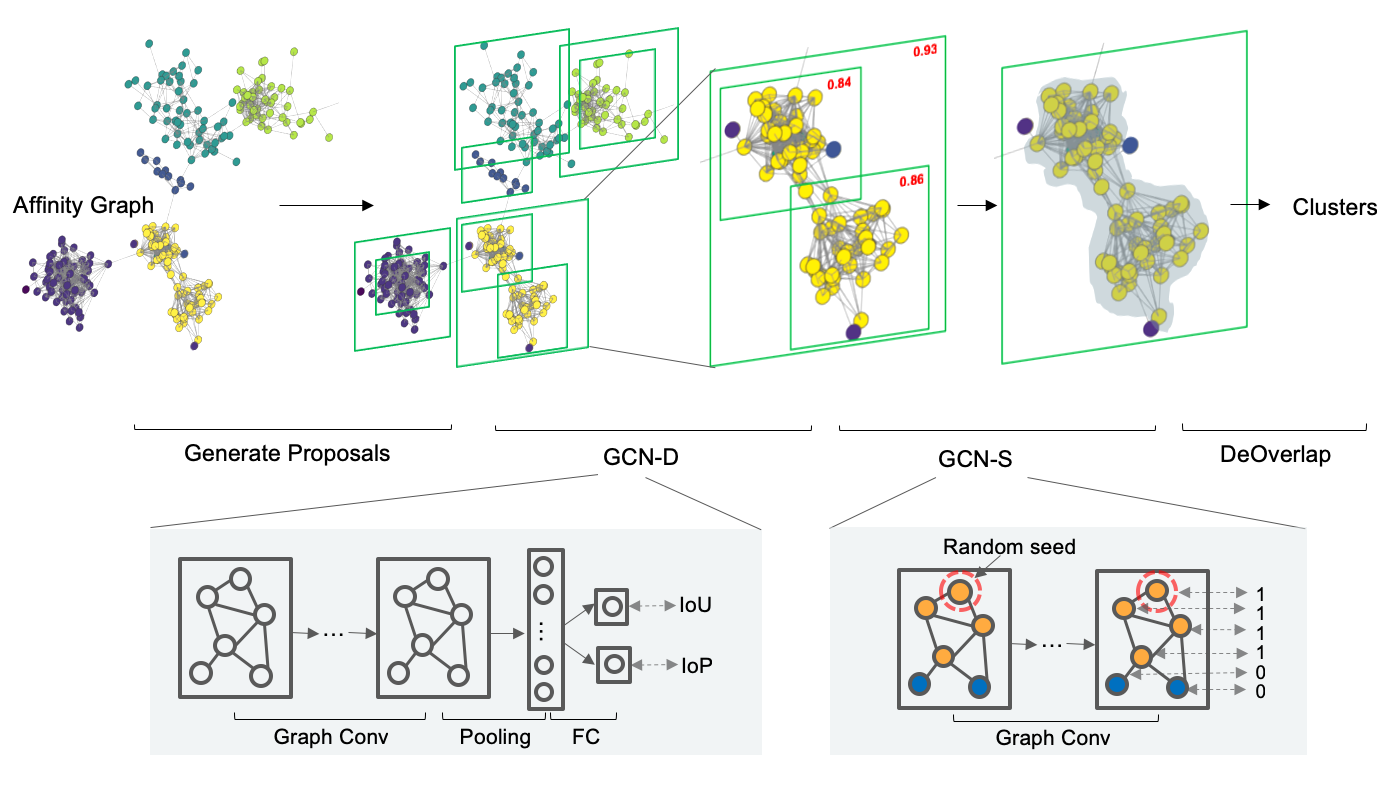
- Cluster Proposals
generate multi-scale proposals with different
k,thresholdormaxsz.
sh scripts/generate_proposals.sh- Cluster Detection
sh scripts/test_cluster_det.sh- Deoverlap
sh scripts/deoverlap.sh [pred_score]- Evaluation
sh scripts/evaluate.sh [gt_label] [pred_label]- [Optional] GCN Upper Bound It yields the performance when accuracy of GCN is 100%.
sh scripts/gcn_upper_bound.shWe follow the apis of mmdet to construct our training and testing.
Checkout dsgcn/train_cluster_det.py and mmdet for more details.
- Generate proposals on part0_train
Modify
nametopart0_trainand generate proposals.
sh scripts/generate_proposals.sh- Train cluster detection (gcn-d)
Edit
dsgcn/configs/cfg_train_0.7_0.75.yamlto use approriate proposals. Generally, more proposals, better performance.
sh scripts/train_cluster_det.sh| Method | Precision | Recall | F-score |
|---|---|---|---|
| Approx Rank Order (knn=80, th=0) | 99.77 | 7.2 | 13.42 |
| MiniBatchKmeans (ncluster=5000, bs=100) | 45.48 | 80.98 | 58.25 |
| KNN DBSCAN (knn=80, th=0.7, eps=0.7, min=40) | 62.38 | 50.66 | 55.92 |
| FastHAC (dist=0.72, single) | 92.07 | 57.28 | 70.63 |
| DaskSpectral (ncluster=8573, affinity='rbf') | 78.75 | 66.59 | 72.16 |
| CDP (single model, th=0.7) | 80.19 | 70.47 | 75.02 |
| GCN-D (0.7, 0.75) | 95.41 | 67.79 | 79.26 |
| GCN-D (0.7, 0.75) + iter1 (0.4, 2, 16) | 95.52 | 68.81 | 80.00 |
| GCN-D (0.65, 0.7, 0.75) | 94.64 | 71.53 | 81.48 |
| GCN-D (0.6, 0.65, 0.7, 0.75) | 94.60 | 72.52 | 82.10 |
Generally, more proposals leads to better results. You can control the number of proposals to strike a balance between time and performance.
1, 3, 5, 7, 9 denotes different scales of clustering.
Details can be found in Face Clustering Benchmarks.
| Methods | 1 | 3 | 5 | 7 | 9 |
|---|---|---|---|---|---|
| CDP (single model, th=0.7) | 75.02 | 70.75 | 69.51 | 68.62 | 68.06 |
| GCN-D (0.7, 0.75) | 79.26 | 75.72 | 73.90 | 72.62 | 71.63 |
| GCN-D (0.6, 0.65, 0.7, 0.75) | 82.10 | 77.63 | 75.38 | 73.91 | 72.77 |
Please cite the following paper if you use this repository in your reseach.
@inproceedings{yang2019learning,
title={Learning to Cluster Faces on an Affinity Graph},
author={Yang, Lei and Zhan, Xiaohang and Chen, Dapeng and Yan, Junjie and Loy, Chen Change and Lin, Dahua},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2019}
}

