With python 3.8, feedforward neural networks (conventional and convolutional neural networks) are developed for classifying pictures. Create the neural network architecture and train it. Classify pictures according to enhancement.
| 🔢 | Ход работы | ℹ️ |
|---|---|---|
| 1️⃣ | Установить библиотеку keras, tensorflow. | ✅ |
| 2️⃣ | Скачать датасет с симпсонами варианту (для каждого класса отдельная директория). | ✅ |
| 3️⃣ | Создать архитектуру нейронной сети прямого распространения с двумя полносвязными скрытыми слоями и сверточной нейронной сети с двумя сверточными и двумя полносвязными слоями и скомпилировать модели (model.summary()). | ✅ |
С помощью python 3.8 разработать нейронные сети с прямой связью (обычную и свёрточную нейронные сети) для классификации картинок. Создать архетектуру нейронной сети и обучить её. Классифицировать картинки в соответствии с вариантом.
Нейронная сеть прямого распространения - это разновидность искусственной нейронной сети, в которой соединения между узлами не образуют цикла. Мы подаём на вход "сырые" картинки, а на выходе получаем вероятность принадлежности какому-то классу. В FFNN данные сразу передаются в нейронную сеть.
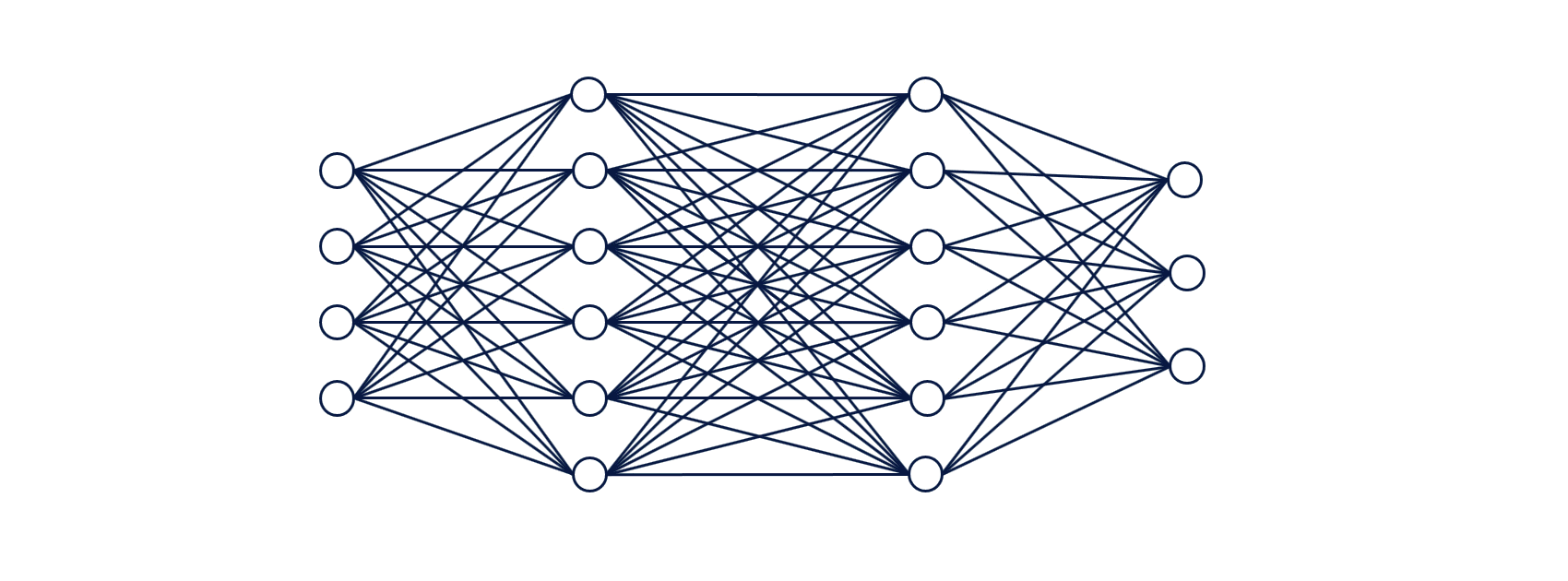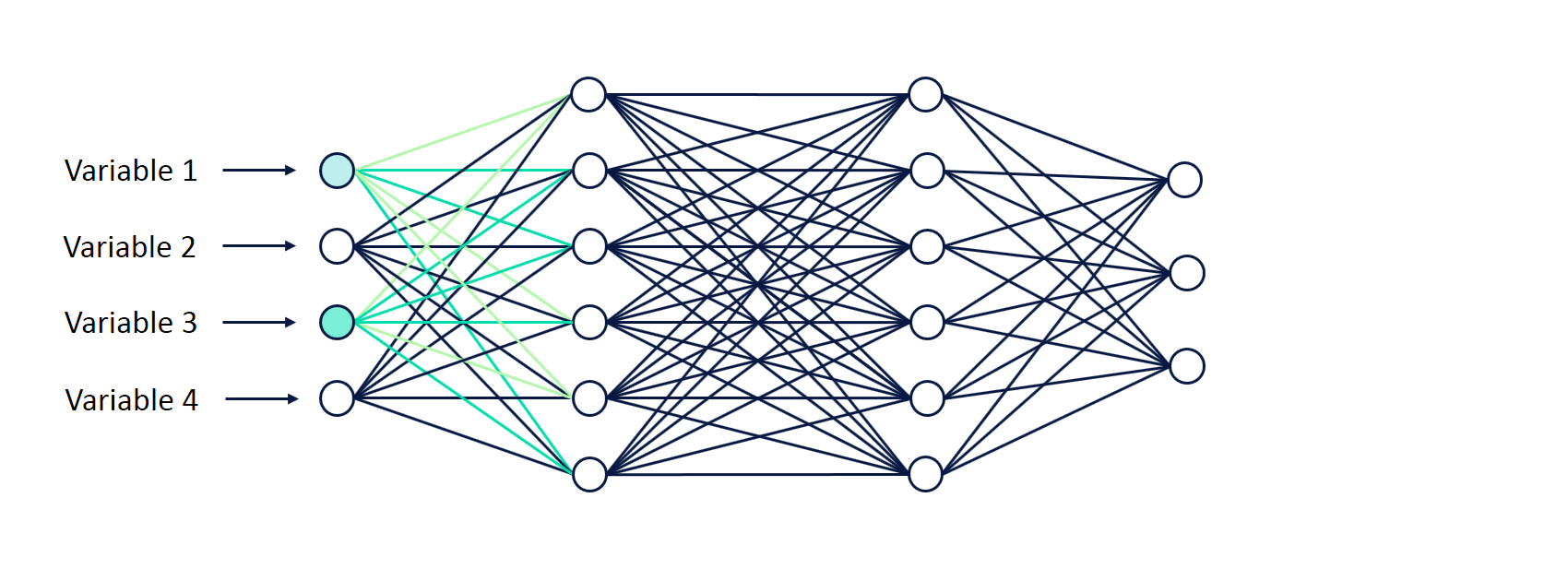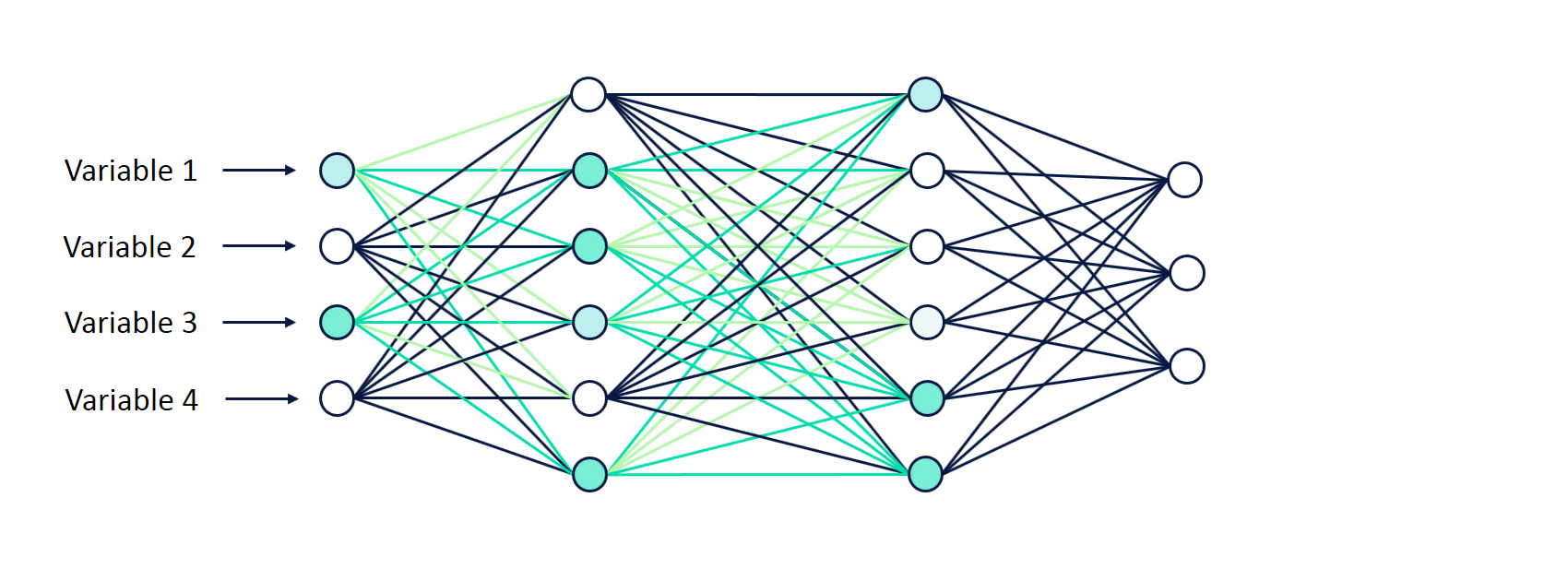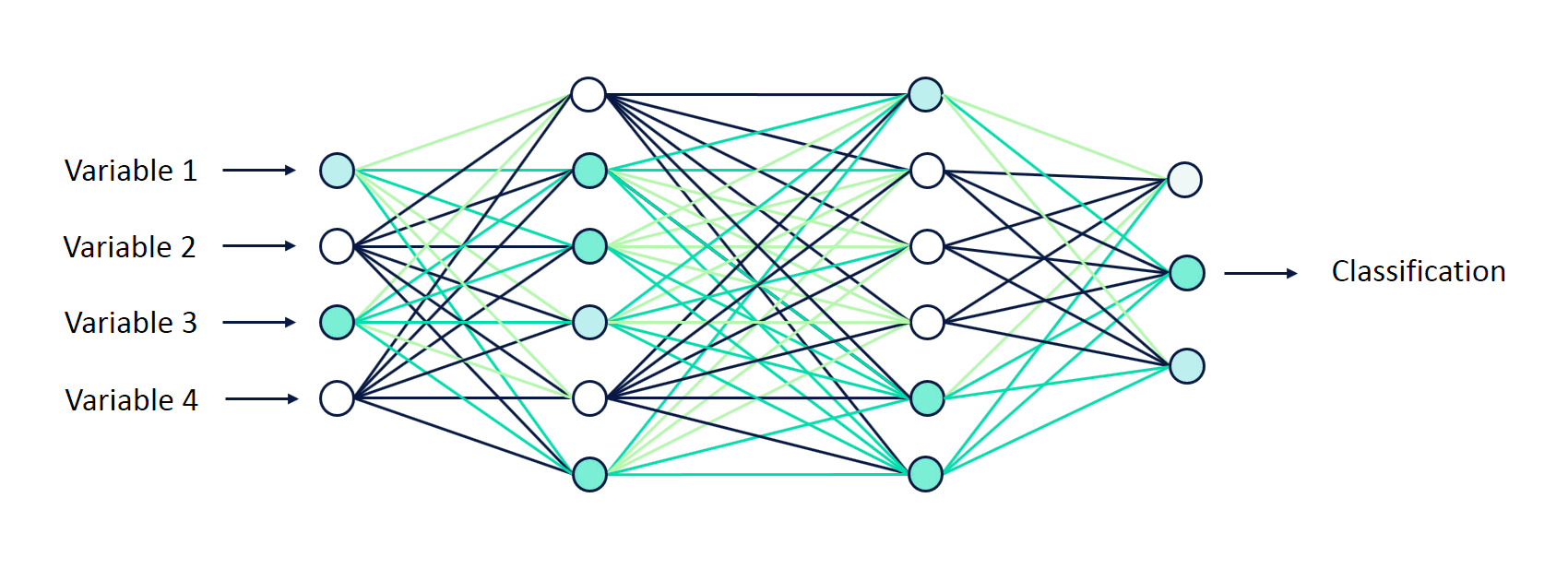
В файле feed_forward_neural_network содержится программа программа для классификации изображений на основе нейронной сети прямого распространения (Основные шаги программы расписаны по пунктам):
- В файле сразу после библиотек идут пути к папкам с картинками:
- Путь train_path ведёт к тренировочным папкам по которым будет учиться нейронная сети. Путь test_path ведёт к файлам, которые мы будем классифицировать. Путь result_path указывает куда будут сохраняются файлы которые нейронная сеть обработала. Путь plot_path указывает куда сохранить график.
train_path = "dataset/train"
test_path = "dataset/test"
result_path = "dataset/saved_ffnn"
plot_path = "../../Desktop/lr-6-opc-master/loss-accuracy-ffnn.png"-
Далее происходит инициализация данных и меток, массив data будет содержать набор данных о картинках т.е. вектора связанные с картинкой, которые представляют RGB матрицу (Матрица размерности = ширина х высоту х 3(так как 3 цвета)). А массив labels содержит название картинок.
-
С помощью метода listdir смотрим какие папки находятся на пути:
train_labels = os.listdir(train_path)- С помощью метода sort() сортируем по имени:
train_labels.sort()- Цикл по изображениям из папки train - вытаскивает картинки и кладет в data, а их класс (имя одного из симпсонов) в labels. С помощью метода path.join запоминанием пути к каждой папке, current_label название текущей папки. Далее создаём пути для каждой папки path.
dir = os.path.join(train_path, training_name)
current_label = training_name- Создаём пути для тренировки:
path = train_path + "/" + training_name- С помощью метода listdir определяем содержание папки:
x = os.listdir(dir)- Пробегаем по каждому файлу и создаём путь для каждой картинки. С помощью метода imread считываем картинку.С помощью метода resize преобразуем изображение в размер 32х32, а с помощью метода flatten(его используют так как нейронная сеть работает только с одномерными массивами ) преобразуем картинку в одномерный массив, где его элементами будут пиксели RGB расцветки.
for y in x:
file = path + "/" + str(y)
image = cv2.imread(file)
image = cv2.resize(image, (32, 32)).flatten()
data.append(image)
labels.append(current_label)- Следующим шагом разбиваем данные на обучающую и тестовую выборки, при этом используя 80% данных для обучения (trainX, testX ) и оставшиеся 20% (trainY, testY) для тестирования. Для разбиения используем метод train_test_split:
seed = 15 # random.randint(1, 100)
print("seed =", seed)
(trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.2, random_state=seed)
print(testY)-
Параметр random_state=seed влияет на принцип деления данных по закономерности, он конвертирует метки из целых чисел в векторы (в seed указывается рандомное значение, которое влияет на принцип деления данных)
-
Используя метод LabelBinarizer для каждого класса формируем вектор(к примеру если классов 5, то вектор длинны 5)
lb = LabelBinarizer()- Теперь перейдем к основному этапу программы, а именно создадим архитектуру нейронной сети с помощью модели Sequential. С помощью метода add добавляем слои( Dense спрятанный слой). input_shape входная размерность указывается только в первом слое или методе и равна 3072(или 32х32х3). Далее определим выходное значение нейрона в зависимости от результата взвешенной суммы входов и порогового значения для этого используем функцию активации activation="sigmoid". Добавим ещё один слой 512 точек используем функцию активации activation="sigmoid". Последний слой имеет длину lb.classes_ и функцию активации activation="softmax". И наконец инициализируем скорость обучения и общее число эпох EPOCHS = 20:
model = Sequential()
model.add(Dense(1024, input_shape=(3072,), activation="sigmoid"))
model.add(Dense(512, activation="sigmoid"))
model.add(Dense(len(lb.classes_), activation="softmax"))
EPOCHS = 20- Скомпилируем модель, используя метод Adam в качестве оптимизатора для более быстрых вычислений и категориальную кросс-энтропию в качестве функции потерь:
print("[INFO] training network...")
opt = Adam(lr=0.001, beta_1=0.9, beta_2=0.999)- Используем метод compile, функцию потерь , кросс-энтропию и метрику точности компилируем модель нейронной сети:
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])- Используем метод summary построим таблицу архитектуры нейронной сети:
model.summary()- C помощью метода fit загружаем в модель тренировочные и тестовые данные и количество эпох (параметр batch_size управляет размером пакетов в компьютере).
H = model.fit(trainX, trainY, validation_data=(testX, testY), epochs=EPOCHS, batch_size=32)- Произведём оценку нейронной сети. Для этого воспользуемся методом predict, который предсказывает вероятности принадлежности классам и построим табличку.
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1), predictions.argmax(axis=1), target_names=lb.classes_))- В завершении построим графики потерь и точности loss и accuracy значения для тренировочных данных и val_loss и val_accuracy значения для тестовых данных.
- Строим сетку графика. Параметр N = np.arange на сколько он будет длинным по оси.
N = np.arange(0, EPOCHS)- Метод plot добавляет график. В h содержится матрица параметров для каждой эпохи, а с помощью метода history выдает значения для каждой эпохи.
plt.plot(N, H.history["loss"], label="training loss")
plt.plot(N, H.history["val_loss"], label="validation loss")
plt.plot(N, H.history["accuracy"], label="training accuracy")
plt.plot(N, H.history["val_accuracy"], label="validation accuracy")- Начинаем предсказывать принадлежность изображения к классу. Так с помощью метода listdir запоминанием название картинок и путь к ним, а также считываем его.
test_labels = os.listdir(test_path)- Загружаем входное изображение и меняем его размер на необходимый. Для каждой картинки мы запоминаем путь, считываем и копируем его.
path_for_save = result_path + "/" + test_file
test_file = test_path + "/" + test_file
image = cv2.imread(test_file)
image_copy = image.copy()
image = cv2.resize(image, (32, 32)).flatten()- Выводим название класса и вероятность принадлежности на картинку.
text = f'{label}: {round(predictions[0][i] * 100, 2)}%'- С помощью метода imwrite сохраняем классифицированное изображение в папку.
cv2.imwrite(path_for_save, image_copy)
Оценка полноты, точности и аккуратности

График потерь и точности для каждой модели


Данные полученные в результате выполнения программы с нестандартными картинками для FFNN
Свёрточная нейронная сеть - это такая же нейронная сеть, но прежде чем подать данные их предварительно обрабатывают для получения вектора фитч. CNN(Convolutional Neural Network)-предварительная обработка данных.

При обработки изображений CNN выполняются следующие операции:
- Классификация - это первый этап обработки изображения на, котором происходит разделение объектов на определённое количество классов по определённым признакам, при этом задано конечное множество объектов, для которых уже определен класс. Для остальных необходимо построить алгоритм, способный классифицировать их. Так же для классификации используются полносвязные слои.

- Детекция – задача, в рамках которой необходимо выделить несколько объектов на изображении посредством нахождения координат их ограничивающих рамок и классификации этих ограничивающих рамок из множества заранее известных классов.

- Сегментация - поиск групп пикселей, каждая из которых обладает определенными признаками. Сверточные слои обычно рисуются в виде набора плоскостей или объемов. Каждая плоскость на таком рисунке или каждый срез в этом объеме — это, по сути, один нейрон, который реализует операцию свертки. По сути, это матричный фильтр, который трансформирует исходное изображение в какое-то другое, и это можно делать много раз.

- Слои субдискретизации (Subsampling или Pooling) просто уменьшают размер изображения: было 200х200 ps, после Subsampling стало 32х32 ps. По сути, усреднение.
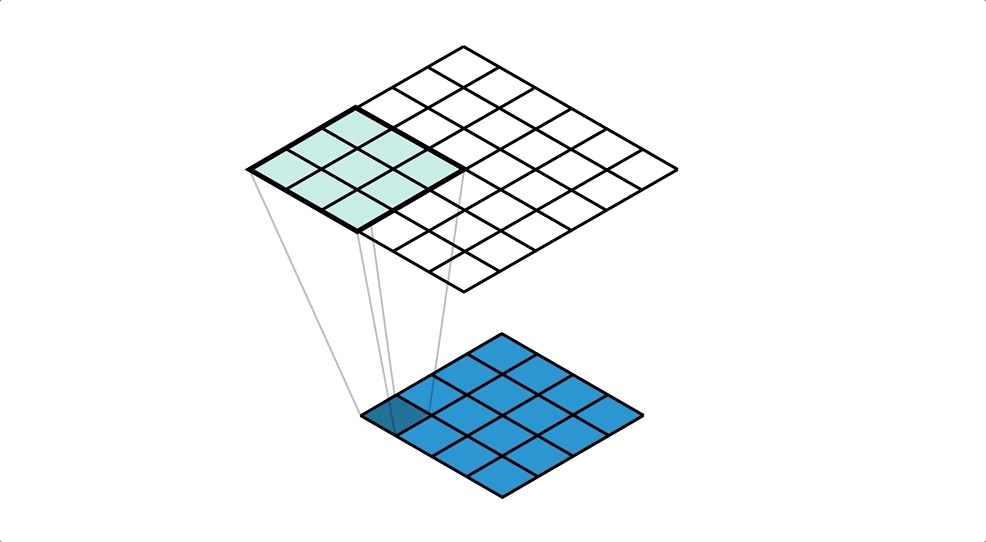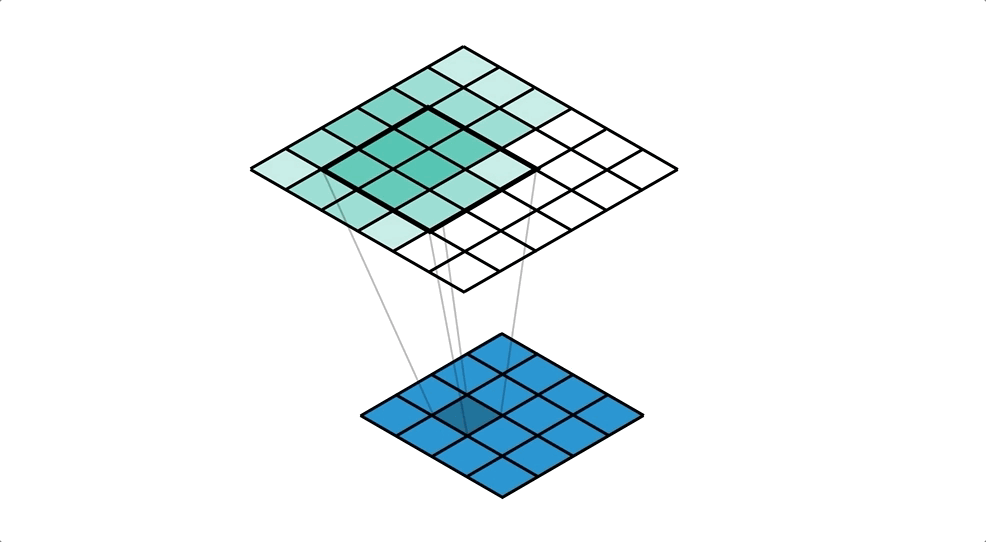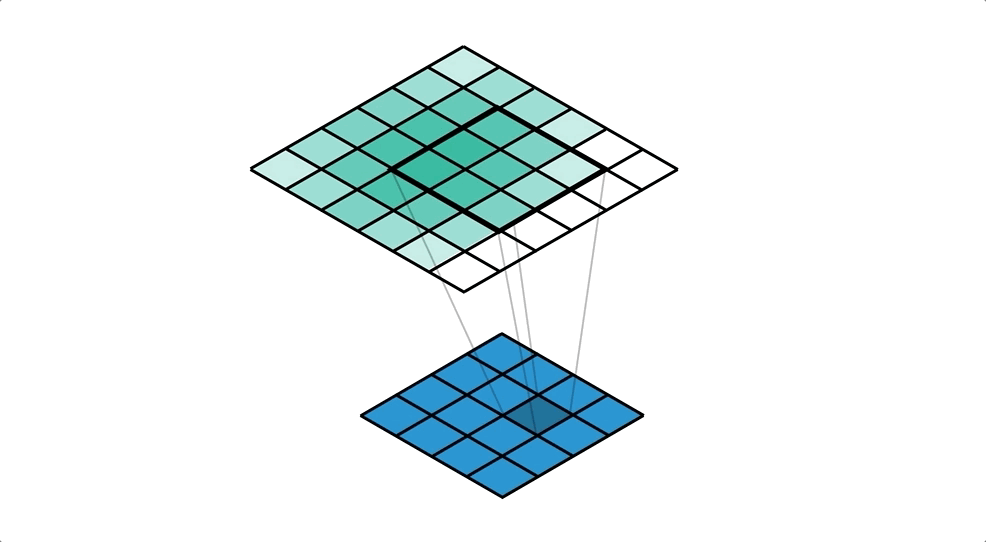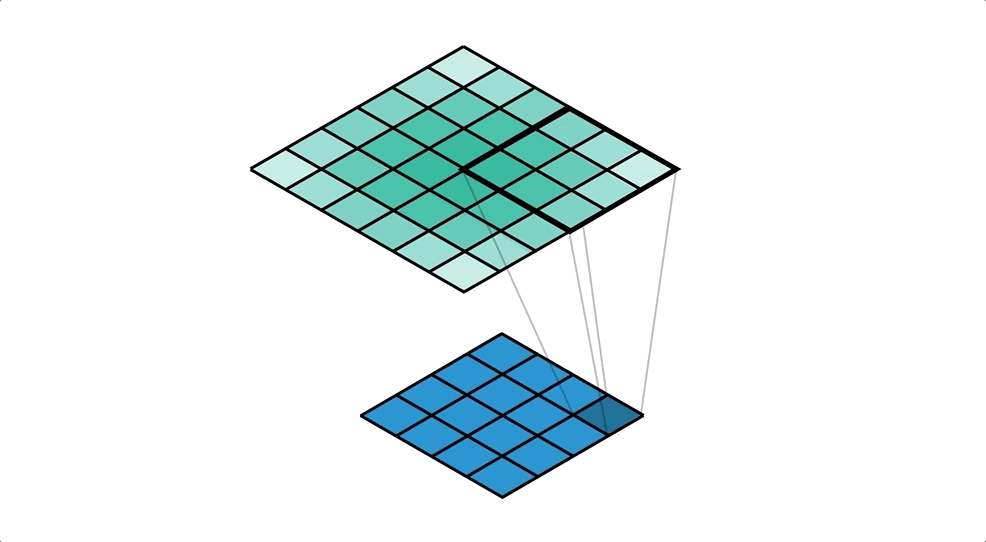
Как говорилось выше свёрточная нейронная сеть работает практически так же, как сеть прямого распространения за исключением того, что изображения предварительно обрабатываются. Изображения не загружаются в массив, то есть остаётся матрица 32х32х3 с которой будем работать.
В файле convolution_neural_network практически всё тоже самое, что в файле feed_forward_neural_network. И там и там содержится программа для классификации изображений на основе нейронной сети. Но стоит дойти до создания архитектуры с использованием модели Sequential, тут и начинаются отличия.
- Conv2D это слой свёртки. Идея свёртки такая, что сначала задаём какую-то матрицу с помощью которой получаем набор других матриц.Параметр kernel_size - это размер свёртки. Выходные фильтры будут иметь такую же размерность, как и входные фильтры.
model.add(Conv2D(filters=64, kernel_size=(5, 5), padding="same", activation="relu", input_shape=(32, 32, 3)))- Метод MaxPooling2D обрезает матрицу в два раза по оси Х и Y. Он делит матрицу на квадраты 2х2 и в каждом таком квадрате сохраняет максимальное число.
model.add(MaxPooling2D(pool_size=(2, 2)))- На выходе получается вектор длинны 1024 и с помощью метода Flatten вытягиваем и получаем входные данные .
model.add(Flatten())А дальше мы делаем все тоже самое как и с FFNN.

Оценка полноты, точности и аккуратности

График потерь и точности для каждой модели


Данные полученные в результате выполнения программы с нестандартными картинками для CNN
Так же напоминаю для тех кому интересно выполнить задание самому или протестировать данную программу, то прошу перейти сюда
