This is the code for the paper
Julieta Martinez, Michael J. Black, Javier Romero. On human motion prediction using recurrent neural networks. In CVPR 17.
It can be found on arxiv as well: https://arxiv.org/pdf/1705.02445.pdf
The code in this repository was written by Julieta Martinez and Javier Romero.
- h5py -- to save samples
- Tensorflow 1.2 or later.
First things first, clone this repo and get the human3.6m dataset on exponential map format.
git clone https://github.com/una-dinosauria/human-motion-prediction.git
cd human-motion-prediction
mkdir data
cd data
wget http://www.cs.stanford.edu/people/ashesh/h3.6m.zip
unzip h3.6m.zip
rm h3.6m.zip
cd ..For a quick demo, you can train for a few iterations and visualize the outputs of your model.
To train, run
python src/translate.py --action walking --seq_length_out 25 --iterations 10000To save some samples of the model, run
python src/translate.py --action walking --seq_length_out 25 --iterations 10000 --sample --load 10000Finally, to visualize the samples run
python src/forward_kinematics.pyThis should create a visualization similar to this one
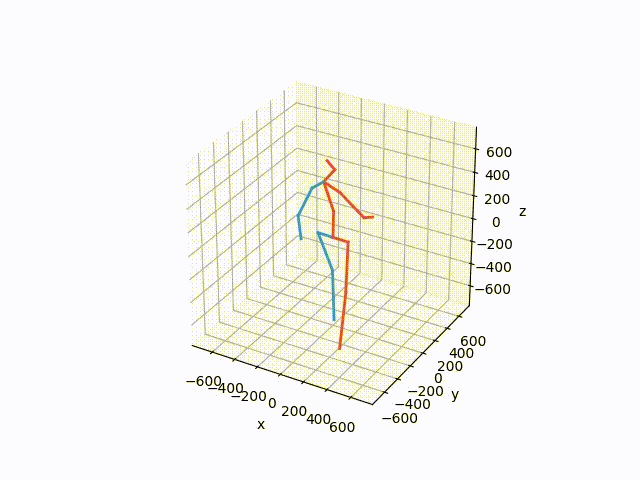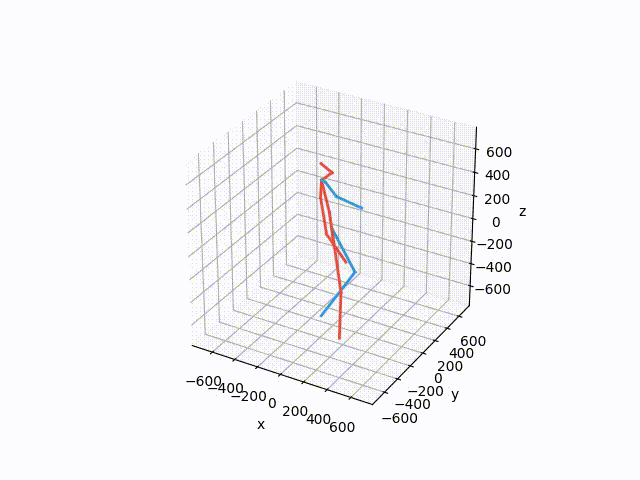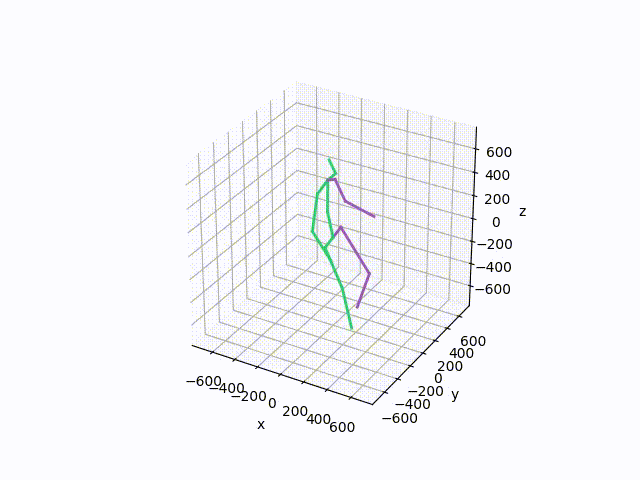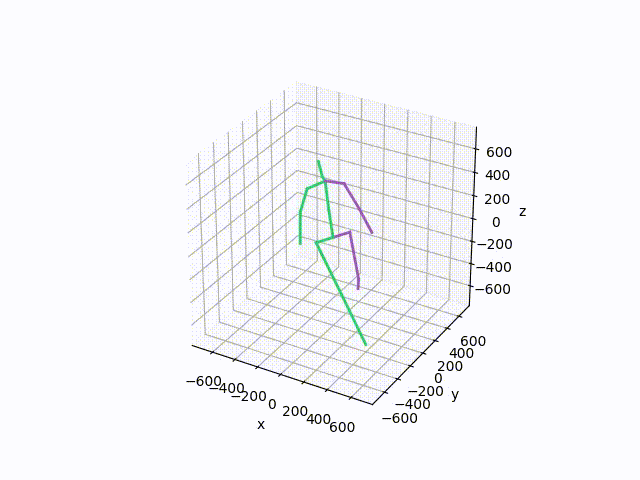
To reproduce the running average baseline results from our paper, run
python src/baselines.py
To train and reproduce the results of our models, use the following commands
| model | arguments | training time (gtx 1080) | notes |
|---|---|---|---|
| Sampling-based loss (SA) | python src/translate.py --action walking --seq_length_out 25 |
45s / 1000 iters | Realistic long-term motion, loss computed over 1 second. |
| Residual (SA) | python src/translate.py --residual_velocities --action walking |
35s / 1000 iters | |
| Residual unsup. (MA) | python src/translate.py --residual_velocities --learning_rate 0.005 --omit_one_hot |
65s / 1000 iters | |
| Residual sup. (MA) | python src/translate.py --residual_velocities --learning_rate 0.005 |
65s / 1000 iters | best quantitative. |
| Untied | python src/translate.py --residual_velocities --learning_rate 0.005 --architecture basic |
70s / 1000 iters |
You can substitute the --action walking parameter for any action in
["directions", "discussion", "eating", "greeting", "phoning",
"posing", "purchases", "sitting", "sittingdown", "smoking",
"takingphoto", "waiting", "walking", "walkingdog", "walkingtogether"]
or --action all (default) to train on all actions.
The code will log the error in Euler angles for each action to tensorboard. You can track the progress during training by typing tensorboard --logdir experiments in the terminal and checking the board under http://127.0.1.1:6006/ in your browser (occasionally, tensorboard might pick another url).
If you use our code, please cite our work
@inproceedings{julieta2017motion,
title={On human motion prediction using recurrent neural networks},
author={Martinez, Julieta and Black, Michael J. and Romero, Javier},
booktitle={CVPR},
year={2017}
}
The pre-processed human 3.6m dataset and some of our evaluation code (specially under src/data_utils.py) was ported/adapted from SRNN by @asheshjain399.
MIT


























































































































