Comments (35)
 thangvubk
commented on May 24, 2024
thangvubk
commented on May 24, 2024
What is the AP50 that you got?
from softgroup.
 CodeFly-123
commented on May 24, 2024
CodeFly-123
commented on May 24, 2024
What is the AP50 that you got?
Yes,set val get AP50 is 0.502 in Area_5. The value is reasonable?
from softgroup.
thangvubk
commented on May 24, 2024
AP50 of 0.502 is lower than expected.
from softgroup.
CodeFly-123
commented on May 24, 2024
AP50 of 0.502 is lower than expected.
I use script of downsample.py get ori dataset,default downsample ratio is 0.25. Then retraining model ,get AP,AP50,AP25 is 0.43,0.59,0.69. I found worse than your result about eight points,Can you give me some ideas to
improve indicators?Thank you very much!
from softgroup.
thangvubk
commented on May 24, 2024
Are you using downsampled data for both train set and validation set?
from softgroup.
CodeFly-123
commented on May 24, 2024
Yes,I use downsampled data both train set and validation,other settings remain unchanged.
from softgroup.
thangvubk
commented on May 24, 2024
Does that mean you sample two times on the train dataset.
Lines 237 to 243 in 91c58d1
from softgroup.
CodeFly-123
commented on May 24, 2024
Thanks you! I don‘t notice this step. It mays affect the results. Can pre training model(softgroup_s3dis.pth)test directly s3dis dataset?I want to try again to verify whether it is the reason for this step.
from softgroup.
thangvubk
commented on May 24, 2024
If the pretrained data and test data have different sparsity, the results will be affected.
from softgroup.
CodeFly-123
commented on May 24, 2024
I quite understand your point of view. The point cloud sparsity Influences model generalization ability. now I test whether this is the reason
from softgroup.
CodeFly-123
commented on May 24, 2024
hi,When I give up downsample data,testing a data file of Area_2 about 9 millions points ,occurred cuda out of memory . use sigle gpu GTX 1080 Ti 11GB,
Can you tell me what the solution is?
from softgroup.
thangvubk
commented on May 24, 2024
You may skip large scene test on Area_5 which has fewer points.
from softgroup.
CodeFly-123
commented on May 24, 2024
if test large scene ,Is there any way to achieve it? fewer points scene can Successful implementation.
from softgroup.
thangvubk
commented on May 24, 2024
You should use large GPU mem.
from softgroup.
CodeFly-123
commented on May 24, 2024
hi.I'm running the latest version of the program.When Distributed training backbone set four gpus,still appear error of cuda out of memory in first epoch validation. Can you tell me what can be done to ease cuda restrictions to continue training successfully?
from softgroup.
thangvubk
commented on May 24, 2024
If you are using the latest version, the followings may help to run on small mem GPU.
1) Change data_root of test set only to dataset/s3dis/preprocess_sample.
2) Disable testing config x4_split by setting to False since we don't need to downsample the second time.
3) Add --skip_validate to your train script e.g. ./tools/dish_train.sh .... --skip_validate. Validation + training will need more mem.
4) You may enable mix-precision training to further save GPU mem.
from softgroup.
CodeFly-123
commented on May 24, 2024
hi.Thank you for your answer.There are the following problems.
1)According to the original configuration of the code,After training,test in s3dis of Area_5 get AP,AP_50%,AP_25% is 0.349 , 0.502, 0.625
2)Use your pretrained model softgroup_s3dis_spconv2.pth, get AP,AP_50%,AP_25% is 0.367 , 0.529, 0.653
Why is it so different from your result?Hope to get the author's answer

.
from softgroup.
thangvubk
commented on May 24, 2024
The two models are trained in different ways with different data density i think.
from softgroup.
CodeFly-123
commented on May 24, 2024
I use your pretrained model of softgroup_s3dis_spconv2.pth to test. test data is process_sample.
command line :./tools/dist_test.sh configs/softgroup_s3dis_fold5.yaml softgroup_s3dis_spconv2.pth
Is that right?If there are problems, please give guidance.
from softgroup.
thangvubk
commented on May 24, 2024
If you use pretrained model to test the process_sample you need to disable x4_split to get good results. That's it.
from softgroup.
CodeFly-123
commented on May 24, 2024
If you use pretrained model to test the
process_sampleyou need to disable x4_split to get good results. That's it.
When I follow your setup,the results is almost the same as before. At present, I want to have a good effect in s3dis dataset


.
from softgroup.
thangvubk
commented on May 24, 2024
Ah. The current dataset suppose x4_split at test time for s3dis. A workaround is to comment out these two functions to use default transform and collate_fn. Below is the result of downsampled data on my machine. I will update the testing on sampled data when available.
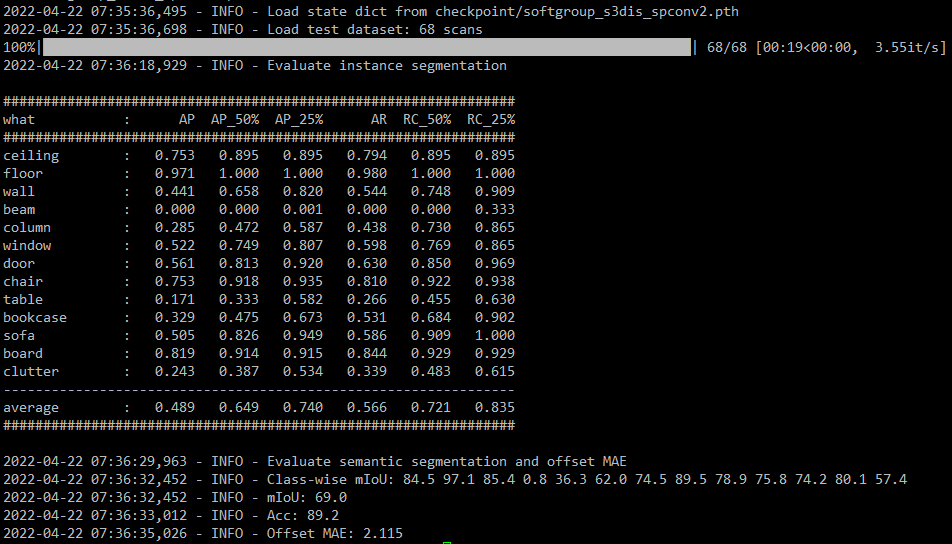
from softgroup.
CodeFly-123
commented on May 24, 2024
Thanks!
Can you tell me where the comment out are? I try when I direct comment out the code of two functions in s3dis.py,the program get errors.

from softgroup.
thangvubk
commented on May 24, 2024
I just append _old to names of two these functions. Did you make other changes in the code?
from softgroup.
CodeFly-123
commented on May 24, 2024
I don't make other changes in the code. set x4_split=True, test in process_sample data. append _old to names of two these functions is right? But still get errors.

from softgroup.
thangvubk
commented on May 24, 2024
If you use pretrained model to test the
process_sampleyou need to disable x4_split to get good results. That's it.
You should set x4_split to False instead.
from softgroup.
CodeFly-123
commented on May 24, 2024
hi. I have successfully tested in Area_5 test set. The result is similar to yours. But, When I want to test a big scene pointcloud about nine millions at an example of train set. scene name is Area_2_auditorium_2_inst_nostuff.pth. The test result looks a little bad.

The test acc on train dataset should show very good performance. Hope get your answer.
Thank you!
from softgroup.
thangvubk
commented on May 24, 2024
How about the performance of the whole set. This scene may be an outlier
.
from softgroup.
CodeFly-123
commented on May 24, 2024
The performance of the whole Area_2 set is good. But it's all small scenes that perform well. The large scene is bad. I think when the large scene are used as training sets,test acc should show very good performance. for example overfitting. so I want to know is there any way to improve,maybe the algorithm model is not very good to handle big scenes.
from softgroup.
thangvubk
commented on May 24, 2024
Maybe it is side effect of random crop during training.
from softgroup.
CodeFly-123
commented on May 24, 2024
hi. Sorry to bother you again.I have the following two questions:
1)Can I train the large scene data by loading your pre train model softgroup_s3dis_spconv2.pth?I also disable the code of random crop during training.
2)When I running script of prepare_data_inst.py in Area_2_auditorium_1 scene, a data format error has occurred. What caused this?

from softgroup.
thangvubk
commented on May 24, 2024
please check here #51
from softgroup.
CodeFly-123
commented on May 24, 2024
Hi. I test a file of s3dis which croping into a small part. This data is mainly concerned with chairs. But This result still doesn't separate each chair instance. I guess there is a problem in the clustering part. Can you help me analyze the reason?first picture is input. second is pre-instance.


from softgroup.
thangvubk
commented on May 24, 2024
This is a difficult case since the chair is too close to each other.
from softgroup.
 liujingangel
commented on May 24, 2024
liujingangel
commented on May 24, 2024
This is a difficult case since the chair is too close to each other.
hello, I train the model on custom data. then test and visualize . I find the instance performance on the objects that are very close is so bad(but semantic result is good!). Can you help to explain the reason.Looking forward to your reply.
from softgroup.
Related Issues (20)
- Circular import error HOT 1
- How to output the file for Scannet Online Benchmark?
- Low metrics during inference and resumed trainings (GPU-SHARED SERVERS) HOT 1
- ValueError: invalid literal for int() with base 10: '106.000000' HOT 1
- Train my own data error: HOT 3
- IndexError: index 1039 is out of bounds for axis 0 with size 65
- AssertionError: Empty Area_2 in training SIDIS HOT 1
- when i training stpls3d,i have some problems HOT 1
- Install issues HOT 3
- AssertionError: No instance result - results/pred_instance/scene0011_00.txt. HOT 1
- "AssertionError: empty batch" error when training your own dataset HOT 4
- What is the split strategy when working with S3DIS data set? HOT 4
- Explanation of some config parameters HOT 2
- TypeError: forward() takes 6 positional arguments but 9 were given(maybe something wrong with the source codes? HOT 1
- How to obtain voxel labels? HOT 2
- Request code to evaluate mPrec mRec mCov mWcov HOT 1
- Transform_train for custom dataset HOT 1
- Train SoftGroup on different Scenarios HOT 1
- Custom dataset visualization HOT 3
- Why do you need "force_fp32"? HOT 2
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from softgroup.