Comments (62)
 noobpwnftw
commented on August 22, 2024
15
noobpwnftw
commented on August 22, 2024
15
Generation of full 7-piece set is done.
Files available at:
ftp://ftp.chessdb.cn/pub/syzygy/7men/
Thanks to everyone who helped during the process.
from tb.
 MichaelB7
commented on August 22, 2024
1
MichaelB7
commented on August 22, 2024
1
Sent from my iPhone
On Aug 19, 2018, at 12:08 PM, noobpwnftw ***@***.***> wrote:
Generation of full 7-piece set is done.
Files available at:
ftp://ftp.chessdb.cn/pub/syzygy/7men/
Thanks to everyone who helped during the process.
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub, or mute the thread.
from tb.
 snicolet
commented on August 22, 2024
1
snicolet
commented on August 22, 2024
1
Fascinating thread between two masters :-)
Congrats!
from tb.
noobpwnftw
commented on August 22, 2024
The generation looks fine so far, as for discussion, I wish to follow the previous memory bandwidth problem of mine, I have observed via "perf top" and these are hot-spots during iteration process.
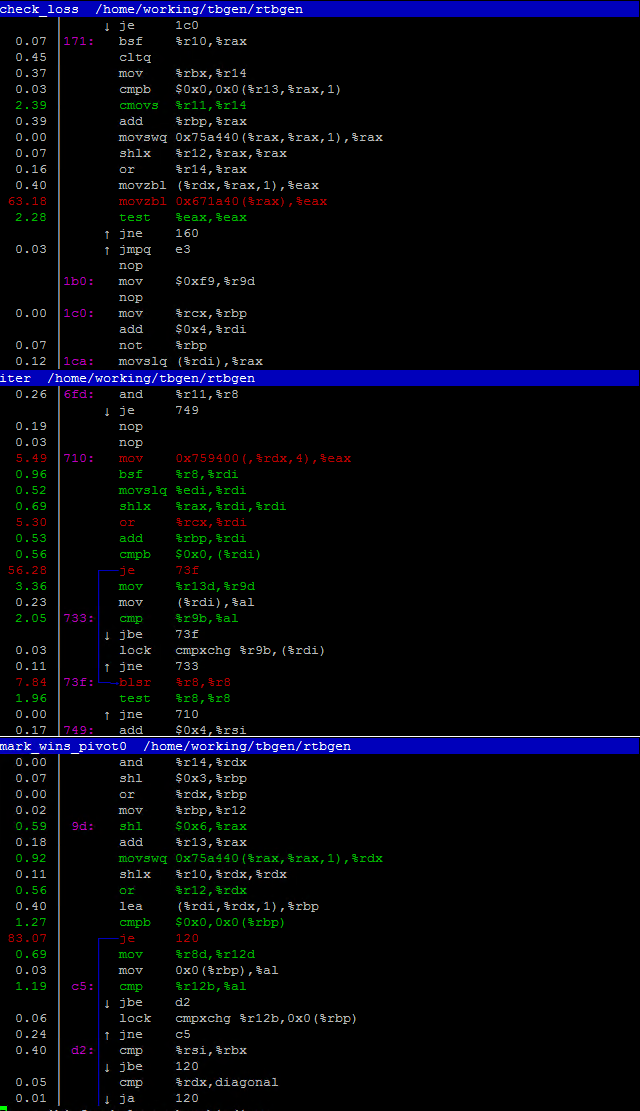
It would no longer cause slowdowns when I use less threads, but this makes me wonder how did people pull this off a few years earlier, which I could assume a magnitude slower interconnect was required to aggregate physical memory from multiple machines in order to hold the intermediate table: even if a space-optimized indexing scheme was used, it still cannot justify the performance loss between UPI vs interconnect.
Any insights?
from tb.
 syzygy1
commented on August 22, 2024
syzygy1
commented on August 22, 2024
What slows down your system the most must be the inter-node accesses.
An improved algorithm might "pin" KK slices to nodes in a clever way and somehow streamline the accesses across KK slices, in particular those across nodes.
It might already help a lot to control what nodes are working on what parts of the table. Then inter-node accesses can be limited to looking up king moves. With 8 nodes, there only need to be inter-node accesses for moves of the white king. As it is now, moves of essentially all pieces can trigger inter-node accesses because a thread will usually be working on non-local memory.
The Lomonosov generator runs on a cluster with very many nodes and 8 cores per node. I suppose each node holds at least one KK slice and inter-node accesses are somehow queued and performed in batches. Some links:
https://plus.google.com/100454521496393505718/posts/R2pxYGaW4JA
https://plus.google.com/100454521496393505718/posts/WfM5ARPec7f
https://plus.google.com/100454521496393505718/posts/DvmgwVHdLqD
https://plus.google.com/100454521496393505718/posts/7cAF7dweRmn
I think the Lomonosov generator uses 2 bytes per position during generation. That avoids the need for reduction steps (which are more painful when generating DTM tables).
Earlier approaches used less RAM and a lot more time.
from tb.
syzygy1
commented on August 22, 2024
I think it does not make sense not to make the generator "NUMA aware" during generation, so I will start working on it.
How much time does a permutation step take on your machine?
I think it is theoretically possible to speed this phase up by looping in the right way, but it seems very tricky to implement that in a general way (I haven't spend much thought on it yet).
The compression algorithm does many passes over the data, but it is very sequential so it should scale quite well to a big machine. Making it NUMA aware should still help, but it might not be crucial.
The other thing of course is to take into account same-piece symmetry.
from tb.
noobpwnftw
commented on August 22, 2024
Permutation step of DTZ usually takes about 5 minutes on a 4v3 table.
Time usage example:
Generating KQQBvKQQ
Found 531 tablebases.
number of threads = 64
Initialising broken positions.
time taken = 0:22.907 <- this can go very long if I raise number of threads
Calculating white captures.
time taken = 0:30.608
time taken = 1:02.598
time taken = 2:30.105 <- this can go very long if I raise number of threads
Calculating black captures.
time taken = 0:14.264
time taken = 0:47.799
time taken = 1:04.080
time taken = 0:58.022 <- this can go very long if I raise number of threads
Calculating mate positions.
time taken = 1:33.258 <- this can go very long if I raise number of threads
Iteration 1 ...
The most time consuming steps are the first few iterations(Iteration 1~3), first saving for reduction if it reaches "Iteration 62...", it can take some 30 minutes, following saves are usually faster.
Compression iteration steps are indeed pretty quick.
from tb.
noobpwnftw
commented on August 22, 2024
I am using interleaving memory allocation and not binding threads(let the OS re-balance automatically), it turns out to be the fastest way. Excessive threads just made everything significantly slower thus the symptom looked like the OS migration was the killer, which it wasn't.
from tb.
syzygy1
commented on August 22, 2024
I have now created a numa branch. Only rtbgen works for the moment. This might allow you to run the generator with many more threads without slowing down. It supports 2, 4 and 8 nodes.
I think you will have to disable "node interleaving" in the bios. (If I understand you correctly, you have now enabled it.)
from tb.
noobpwnftw
commented on August 22, 2024
I will test it in a moment.
In BIOS, there is no such option that controls interleaving memory across NUMA nodes(only per socket interleaving if I read correctly). Manual Pg.77
This behavior was controlled by invoking via "numactl --interleave=all" on the OS side, by observing "numactl -H" I can see interleaved allocation across nodes and eventually gets migrated to busy nodes by the OS.
So I will run it without memory interleaving and/or disable NUMA re-balancer from the OS and see how it goes.
from tb.
syzygy1
commented on August 22, 2024
Ah I see, then no need for a reboot. I think some mainboards have an option to just interleave all memory over all nodes and to hide the NUMAness from the OS.
It might still help to run with numactl --interleave=all, for example if the numa-aware rtbgen now does worse in the permutation and compression steps.
from tb.
syzygy1
commented on August 22, 2024
Oh I forgot to say that you need to add the "-n" option to enable NUMA.
And to compile, you will need to have libnuma and its headers installed.
from tb.
noobpwnftw
commented on August 22, 2024
I have figured them out. And good news, it does not cause any slowdowns.
Some timings:
Generating KQQBvKRB
Found 536 tablebases.
Number of threads = 192
Number of NUMA nodes = 8
Initialising broken positions.
time taken = 3:38.691
Calculating white captures.
time taken = 0:04.877
time taken = 0:19.015
time taken = 0:18.662
Calculating black captures.
time taken = 0:03.883
time taken = 0:10.985
time taken = 0:14.552
time taken = 0:21.434
Calculating mate positions.
time taken = 0:19.627
Iteration 1 ... done.
Iteration 2 ...
One exception is the first broken init step, during which the OS tries to migrate memory pages to appropriate nodes, upgrading them to huge pages and/or parallel disk access, but I think it is not worth optimizing.
Observing "numactl -H" shows about even memory distribution across nodes, so “numactl --interleave=all” would not be necessary anymore.
Also I have measured memory bandwidth and latency under load, local: 106GB/s(87ns), remote: 16GB/s(160ns~220ns).
So this brings about a very big performance improvement. Cheers!
from tb.
noobpwnftw
commented on August 22, 2024
Blazing fast confirmed, even with HT on.
Generating KQQBvKRB
Found 536 tablebases.
Number of threads = 384
Number of NUMA nodes = 8
Initialising broken positions.
time taken = 0:07.155
Calculating white captures.
time taken = 0:03.686
time taken = 0:15.008
time taken = 0:14.650
Calculating black captures.
time taken = 0:03.026
time taken = 0:07.907
time taken = 0:11.374
time taken = 0:18.956
Calculating mate positions.
time taken = 0:19.196
Iteration 1 ...
I solved the slow first step problem by "cat *.rtbw > /dev/null".
from tb.
syzygy1
commented on August 22, 2024
Excellent!
So now I will have a look at rtbgenp.
The slow initialisation reminds me of a problem that Cfish had on NUMA machines when it used numa_alloc_interleaved() for allocating the TT. I changed that to letting each node fault in a part of the TT. It seems that numa_tonode_memory() also makes the initial allocation slow. I could try the same as I did for Cfish, but I wonder if the kernel might then start migrating pages between nodes.
from tb.
syzygy1
commented on August 22, 2024
Btw, please check that the generated tables are correct, just to make sure I made no mistake. You could test this with a 6-piece table, for example.
from tb.
noobpwnftw
commented on August 22, 2024
That 7 second init was from a fresh reboot + *.rtbw in system cache, so I guess it is not a problem now.
Tested a 6-piece table with numa branch, generator stats are correct, compressed files are correct, but compression iterations became very slow.
from tb.
syzygy1
commented on August 22, 2024
I overlooked the 7s initialisation of the second run.
I guess the first time your system needed time to free up memory. Maybe it would have been sufficient to do echo 1 >/proc/sys/vm/drop_caches.
For speeding up the capture calculations it might help to precache the relevant *.rtbw files.
It would also be possible to force them into memory when they are first mmap()ed by adding MAP_POPULATE to to the flags in map_file() (util.c). This might be more important for 7-piece pawnful generation.
from tb.
syzygy1
commented on August 22, 2024
Did compression get slower while using the -d option?
With -d, compression takes place in the memory originally allocated for generating the table. This memory is now pinned to nodes in a non-random way. It is probably bad if all threads are working on memory located at the same node.
This could probably be improved by letting the threads do the compression passes in a sort of random order instead of linearly from start to end.
Even better might be to rebind the memory to the nodes and let each thread work on local memory. But it might be too expensive to migrate all those pages.
from tb.
noobpwnftw
commented on August 22, 2024
Last checking run was not using the -d option, with it there is the same slowdown(perf says in replace_pairs_u8).
It wasn't slow before because I never get this far to the compression step with this many threads.
Maybe it is because in a 6-piece table memory is too small to split among too many threads? I can try compress a 7-piece table and see what happens.
The situation on the other machine that is building pawnful tables is rather different, there it has zero slowdowns without NUMA partitioning running with all cores(4 nodes), I can't figure out why.
from tb.
syzygy1
commented on August 22, 2024
How many threads are you using on the other machine?
from tb.
noobpwnftw
commented on August 22, 2024
88 threads. E5-4669v4, actually running with 176 threads works just fine too, where in the newer one it suffers on more than 64 threads no matter how I fiddle, unless running the NUMA branch.
P.S. I just checked price, that v4 is more expansive than Scalable, that might explain.
And following the previous compression slowdown, it is the same with a 7-piece table, this memory is allocated anew.
I'm wrapping "run_threaded" with a thread limit parameter, then skip the while loop in "worker" of threads beyond limit, only the compression step should apply, results seems good and tables built are correct.
from tb.
noobpwnftw
commented on August 22, 2024
Generation now is about 10x faster, permutation 5x(5min -> 1min), compression remain the same because I limited threads.
from tb.
syzygy1
commented on August 22, 2024
10x faster is very good!
That permutation becomes so fast (because of more threads, I guess) is surprising. It moves around a lot of data.
Compression will hopefully improve with changes I am working on now.
Improving pawnful generation will be a bit more tricky. I think I will first NUMA-ify generation with 1 pawn and then use the same technique as in the ppppp branch for multiple pawns.
I may also have a look at the reduction step.
from tb.
syzygy1
commented on August 22, 2024
I don't know if the v4 is supposed to have higher bandwidth than the newer generation, but it makes sense that being NUMA aware is more important on 8 nodes than on 4 nodes.
from tb.
noobpwnftw
commented on August 22, 2024
Stats verify failed for KQQNvKQB after reconstruction, comparing with master to find out why.
It is my thread limit patch caused it probably, I have it fixed and no tables affected.
from tb.
syzygy1
commented on August 22, 2024
Strange, the way you described it it sounded OK.
from tb.
noobpwnftw
commented on August 22, 2024
See my reference PR, the first version can skip other NUMA queues entirely. I'm regenerating with the third version to be sure.
from tb.
syzygy1
commented on August 22, 2024
I made some changes, which I have tried to explain in the commit message.
I have not taken into account your PR yet (except for fix_closs, I think).
When running without -d, the generator now makes the permutation step NUMA aware.
This also allows the compression step to be NUMA aware.
The reason the compression step is slow with many threads might be that big arrays are being accessed that are in remote array. It shouldn't be too difficult to allocate those arrays per node, but I have not worked on that yet. I will study your PR later to see if this could be the explanation.
For now, you could re-implement the changes in your PR by changing HIGH to LOW where necessary.
from tb.
noobpwnftw
commented on August 22, 2024
Compression with high threads works better than before, less congestion, but still a slowdown, so does tramsform.
It should be problem free. Tables KQQNvKQR and KQQNvKQB are successfully built.
from tb.
syzygy1
commented on August 22, 2024
OK, then I will move those big arrays to local memory for each node. Whether it makes a big difference or not, it cannot hurt.
from tb.
noobpwnftw
commented on August 22, 2024
I can set them to LOW threads while LOW can use a bit more than 64 threads without slowdowns, that's good enough since those steps won't take a long time anyway.
This is just from a poor/unbalanced configuration of hardware with awful backfires.
If there is no backfire, the OS is capable of migrating threads and/or memory across nodes to reduce NUMA latency as it should be.
from tb.
noobpwnftw
commented on August 22, 2024
KQRRvKRN still has some showdowns with 384 threads in black WDL permutation, but it takes only 2 minutes if I use 64 threads.
from tb.
syzygy1
commented on August 22, 2024
Do you detect the slowdown by looking at the time it takes or with a monitoring tool?
Maybe we could let the generator dynamically adjust the number of threads it uses...
from tb.
noobpwnftw
commented on August 22, 2024
When it is causing slowdowns, the entire OS become unresponsive, easy to tell.
from tb.
syzygy1
commented on August 22, 2024
Ah, I see. Do you know if the cpus throttle down when this happens? Do they get hot and reduce their clock frequency? (Probably not if the problem lies with the memory subsystem.)
from tb.
noobpwnftw
commented on August 22, 2024
Nope, it just seemed like(or actually) taking a few hundred cycles for per memory operation instructions.
Kernel software watchdogs keep triggering and such.
from tb.
syzygy1
commented on August 22, 2024
Do you mean the [watchdog/xx] threads? What happens when they trigger?
I also wonder a bit if it might be the barriers or perhaps the atomic queue counter that cannot handle so many threads. (Doesn't seem very likely but who knows.)
from tb.
syzygy1
commented on August 22, 2024
There is a potential overflow in the compression code. I don't think it can affect correctness, but it probably can affect compression ratio.
It is difficult to say if the overflow has occurred.
I have updated both numa (for rtbgen) and master (for rtbgenp).
from tb.
noobpwnftw
commented on August 22, 2024
Just a bunch of "soft lockup" warnings.
Whenever it happens, I use "perf top" to catch problem, reducing threads on that procedure helps every time, always some abnormally high latency on memory operation instructions.
Ok, I will update both generators.
from tb.
noobpwnftw
commented on August 22, 2024
Starting from KQQNPvKQ and KQRBvKRB, will use new generator.
I have restored with default threads for compression, going to take a while to see what will happen.
from tb.
noobpwnftw
commented on August 22, 2024
New compression code works like a charm, now it can run with many threads.
from tb.
syzygy1
commented on August 22, 2024
Nice!
I read a bit about soft lockups. Do the warnings come with call traces? It seems the call trace will be empty if the thread got locked up in user space.
http://damntechnology.blogspot.de/2010/04/linux-crash-debug-tips-i-have-soft.html
If it happens in user space, then it's probably the hardware and not a kernel problem. Apparently some (or most) threads never (or at least not for many seconds) get their memory requests served. Strangely I can't seem to find any other reports on this problem.
from tb.
syzygy1
commented on August 22, 2024
I just did a test to see what happens if I let the countfirst[] and countsecond[] counters overflow by making them 16 bit. This results in KQRvKQ.rtbw/z of 5610320 and 11540176 bytes instead of 3095888 and 9245968 bytes. As expected, the tables are still correct.
But it seems not too likely that an overflow has happened. The countfirst and countsecond counters are used to update the pairfreq[][] array after each round of replace_pairs(). pairfreq[a][b] counts the number of times ab occurs in the table. If ab is replaced with c, then xaby becoming xcy means that pairfreq[x][a] and pairfreq[b][y] must be decreased by 1 and pairfreq[x][c] and pairfreq[c][y] must be increased. So countfirst[pair#][x] counts the number of times that xab occurs in the table and countsecond[pair#][y] counts the number of times that aby occurs (where pair# identifies ab).
With 64 threads, each thread processes, for the largest tables, on average about 6 billion values (in the first round of replace_pairs()). Each pair is two values, so on average no pair will be replaced more than 3 billion times. Although there is probably some variation between threads, exceeding 2^32 seems to need very special circumstances. Most "vulnerable" seems to be an almost constant table like 6v1 WDL, but the pieceless 5v1 tables all have a smaller index range due to duplicate pieces...
I think you have generated KRBNvKQN.rtbw several times now, each time with an identical result.
So all seems fine for now.
from tb.
noobpwnftw
commented on August 22, 2024
Yes, I have built KRBNvKQN multiple times, and WDL file is identical, and I have not used any thread number lower than 64 to build the tables.
Also, there is an unfortunate disk failure(second time now, bummer) in the pawnful building machine, resuming when the replacement arrives.
from tb.
syzygy1
commented on August 22, 2024
Master can now use libzstd to compress temporary files in parallel. The number of threads can be set in the Makefile. It should be set to a value that makes writing and reading temporary files I/O bound. I have now set it to 6 which is probably higher than necessary with the current compression-level setting.
The compression level is now set to 1:
Lines 282 to 286 in 99256be
Increasing it doesn't seem to gain a lot in compression ratio but does make compression slower. But feel free to experiment. Each compression thread will take about 20 MB of RAM (two buffers of approximately COPYSIZE bytes).
I will now merge this with numa.
from tb.
syzygy1
commented on August 22, 2024
Merged. Forgot to add that the compression ratio is much better with libzstd compared to LZ4. So this should speed up the reduction steps.
from tb.
noobpwnftw
commented on August 22, 2024
Starting from KQRNvKRN I will use the new version, the machine has a 16-disk RAID-0 array, so I can probably use some more threads.
from tb.
noobpwnftw
commented on August 22, 2024
Resuming pawnful table building, that machine runs fine using master branch on 176 threads.
from tb.
syzygy1
commented on August 22, 2024
In the meantime I am working on making the pawn generator NUMA aware.
from tb.
 Saugstrahler
commented on August 22, 2024
Saugstrahler
commented on August 22, 2024
The regenerated KQBNvKQB and KQBNvKQN are still missing on Lichess......
from tb.
syzygy1
commented on August 22, 2024
Since you meantioned on talkchess that you will be trying to verify the pawnless tables, are you planning to run tbver on them? (It would take a non-trivial amount of time to run tbver on all of them.)
At the moment rtbver won't work with the 16-bit compressed files.
It also doesn't fully check high DTZ values (they are capped during verification to fit in a byte), but it will still check that the WDL values are consistent.
Adding some NUMA awareness to the verification process would probably help.
I'm not sure how much memory rtbver needs at the moment (probably about as much as rtbgen without -d).
Since you're using ECC memory, I don't expect any errors in the pawnless tables. It seems unlikely that the pawnless generator generates incorrect results. The biggest danger is that there is still some internal limit that is exceeded by 7-men TBs but not by 6-men TBs. The good thing is that errors in DTZ tables cannot propagate to other tables.
from tb.
noobpwnftw
commented on August 22, 2024
Ok, the verification I intend to perform at this point is to at least check for known issues that we had earlier and make sure that I have regenerated every one of them correctly, using the correct generator.
Also I found that some 5v2 tables failed as following when generating KQRBNvKP:
May 18 02:52:03 localhost kernel: rtbgenp[47762]: segfault at 0 ip 000000000040bd53 sp 00007ed7e46aee00 error 6 in rtbgenp[400000+3a000] May 18 02:52:03 localhost kernel: rtbgenp[47895]: segfault at 12cff270 ip 000000000040bd53 sp 00007ed7a1e29e00 error 6 May 18 02:52:03 localhost kernel: rtbgenp[47875]: segfault at 1c37eba8 ip 000000000040bd53 sp 00007ed7abe3de00 error 6 May 18 02:52:03 localhost kernel: in rtbgenp[400000+3a000] May 18 02:52:03 localhost kernel:
Which points to this line
Line 142 in 99256be
from tb.
noobpwnftw
commented on August 22, 2024
I'm retrying to get more information. Maybe it is just takes more than 1TB memory without -d option.
As I observe they are all large tables in terms of piece combinations.
from tb.
noobpwnftw
commented on August 22, 2024
False alarm, it just ran out of memory on that 1TB RAM machine.
from tb.
syzygy1
commented on August 22, 2024
Yes, it needs just a bit more than 1TB.
I should make the generator quit with an error message if a malloc() fails.
from tb.
noobpwnftw
commented on August 22, 2024
I ran rtbgenp -2 -t 64 -z KRBBPvKQ with new master, it segfaulted.
segfault at 0 ip 000000000042a8b0 sp 00007fffc886a3c0 error 6
I guess somewhere in compress_data of the first permutation estimation, reconstruction and it's stats verification passed. Will retry without -z and see what happens.
from tb.
syzygy1
commented on August 22, 2024
I just tried and with -z it also crashes for me on e.g. KRPvKQ, but without -z it works.
from tb.
noobpwnftw
commented on August 22, 2024
Yes, without -z it works(now at file c).
from tb.
syzygy1
commented on August 22, 2024
Great. Hopefully the generated tables will be free of the problems we had with the earlier 16-bit pawnless tables.
from tb.
 sf-x
commented on August 22, 2024
sf-x
commented on August 22, 2024
Was generation of KQPPvKPP deferred, or did it fail?
from tb.
noobpwnftw
commented on August 22, 2024
@sf-x Deferred, due to it needs reduction(thus no ppppp branch) and it would be too slow to build for now.
from tb.
Related Issues (20)
- Fast 1TB swap file for generation HOT 5
- Finding max_ply and reduce_ply HOT 109
- Required header has been removed HOT 2
- download
- PicoChess Error 6 Man Syzygy, 32 Bit HOT 5
- Memory leak in interface/tbcore.c HOT 3
- Could not allocate sufficient memory. HOT 3
- TB probing code for 7men
- 7 men TB checksum MD5 does not match HOT 2
- Wish to re-establish email contact with RdM
- memory issues HOT 1
- Using context mixing instead of huffman encoding or LZP HOT 1
- util.c 303 HOT 1
- UBSAN overflow in the Binomial calculation HOT 1
- pawn generator rtbgenp
- Not able to compile on windows HOT 1
- Probably a probing error for the cloud interface HOT 2
- Remove memory mapping of DTZ files. HOT 7
- windows MSYS / WSL compilation HOT 1
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from tb.