Comments (12)
 arash-vahdat
commented on July 19, 2024
2
arash-vahdat
commented on July 19, 2024
2
Hi Luke,
I remember your batch size is very small. We anneal the learning to 1e-2 in 5 epochs. There is a good chance that you are seeing NaN because of the high learning rate for small batch size. I would recommend reducing the learning rate to smaller values such as 5e-3 or even 1e-3.
You can increase the frequency of saving checkpoint by modifying this like:
Line 120 in feb9937
If you change save_freq to 1, it will save every epoch.
from nvae.
 Lukelluke
commented on July 19, 2024
1
Lukelluke
commented on July 19, 2024
1
Hi, @kaushik333 ,when i ran into epoch 5, i countered the same problem of present 'nan' result.

and, i remembered one detail on preprocessing Celeba64:
i mentioned that i download the dataset separately, and then, to overcome the problem of data = dset.celeba.CelebA(root="/NVAE/data/root", split=split, target_type='attr', transform=None, download=False) in create_celeba64_lmdb.py file, i tried to modify function (CelebA), where there is a check func:
def _check_integrity(self): return True # for (_, md5, filename) in self.file_list: # fpath = os.path.join(self.root, self.base_folder, filename) # _, ext = os.path.splitext(filename) # # Allow original archive to be deleted (zip and 7z) # # Only need the extracted images # if ext not in [".zip", ".7z"] and not check_integrity(fpath, md5): # return False # # # Should check a hash of the images # return os.path.isdir(os.path.join(self.root, self.base_folder, "img_align_celeba"))
As you can see, i tried to over across this original check.
I'm afraid that this is the source of the problem.
I wanna ask for your help, and wanna know how you solve the problem of data preprocessing.
Ps. When I tried to retrain from stored ckpt model, with the command of --cont_training, and noticed that the training return from epoch 1, not the latest epoch of 5, what a pity of days waiting.
Sincerely,
Luke Huang
from nvae.
Lukelluke
commented on July 19, 2024
Do you get NAN result from the beginning?
In my personal operation, due to the GoogleDrive downloading problem, i get the CelebaA-64 separately, and put them in the same folder(./script/celeba_org/celeba), which contains (identity_CelebA.txt
img_align_celeba.zip
list_attr_celeba.txt
list_bbox_celeba.txt
list_eval_partition.txt
list_landmarks_align_celeba.txt
list_landmarks_celeba.txt)
then do as the instruction of README about preprocessing process
`
-
python create_celeba64_lmdb.py --split train --img_path ./data1/datasets/celeba_org/celeba --lmdb_path ./data1/datasets/celeba_org/celeba64_lmdb
-
python create_celeba64_lmdb.py --split valid --img_path ./data1/datasets/celeba_org/celeba --lmdb_path ./data1/datasets/celeba_org/celeba64_lmdb
-
python create_celeba64_lmdb.py --split test --img_path ./data1/datasets/celeba_org/celeba --lmdb_path ./data1/datasets/celeba_org/celeba64_lmdb
`
No any other change.
And at training process:
`
- python train.py --data ./scripts/data1/datasets/celeba_org/celeba64_lmdb --root ./CHECKPOINT_DIR --save ./EXPR_ID --dataset celeba_64 \
--num_channels_enc 64 --num_channels_dec 64 --epochs 1000 --num_postprocess_cells 2 --num_preprocess_cells 2 \
--num_latent_scales 3 --num_latent_per_group 20 --num_cell_per_cond_enc 2 --num_cell_per_cond_dec 2 \
--num_preprocess_blocks 1 --num_postprocess_blocks 1 --weight_decay_norm 1e-1 --num_groups_per_scale 20 \
--batch_size 4 --num_nf 1 --ada_groups --num_process_per_node 1 --use_se --res_dist --fast_adamax
`
Besides of the address of the data that I put change to the corresponding address, the only wrong I countered was the parameter --num_process_per_node 1 means the GPU number that available.
Here is some provisional result:

And for 1024*1024 pic:
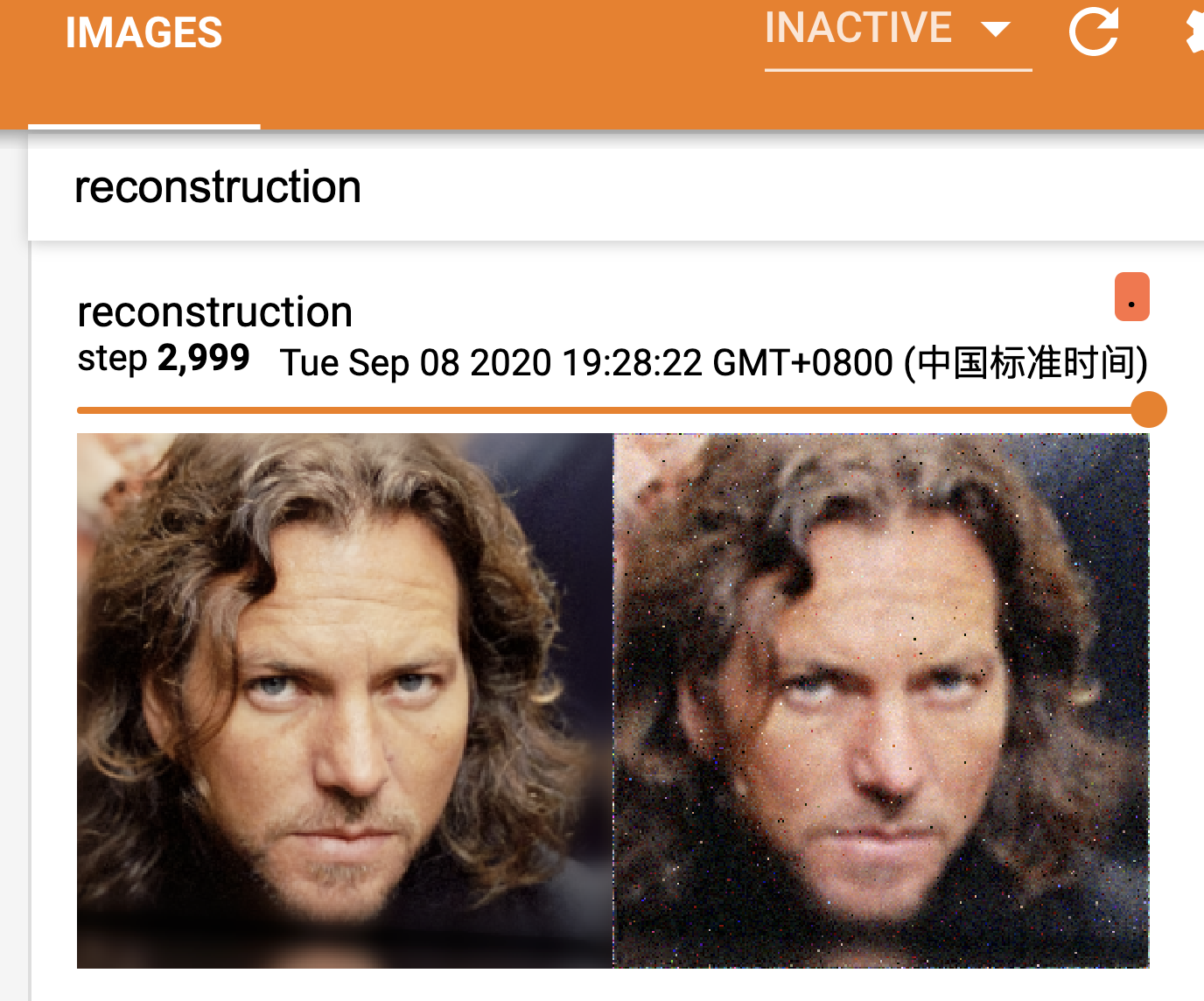

🌟 Hoping that my expression can do any help for you and any other counter problems!
from nvae.
arash-vahdat
commented on July 19, 2024
Thanks @Lukelluke! I am glad that everything worked fine for you.
@kaushik333, do you get NaN from the very beginning of the training? Or does it happen after a few epochs? We haven't done anything beyond running that command to generate the LMDB datasets.
from nvae.
 kaushik333
commented on July 19, 2024
kaushik333
commented on July 19, 2024
Hello @arash-vahdat and @Lukelluke .
I get NaN right from the beginning which is very strange.
I am now trying what @Lukelluke did i.e. download celebA myself and follow the same instructions (not sure if this will help, but still giving it a shot).
from nvae.
arash-vahdat
commented on July 19, 2024
I haven't seen NaN at the beginning of training, especially given that the learning rate is linearly increased from a very small value, this is unlikely to happen. Most training instability happens after we anneal the learning rate which happens in --warmup_epochs epochs.
from nvae.
kaushik333
commented on July 19, 2024
@arash-vahdat @Lukelluke I seemed to have solved the issue. The training now proceeds as expected. Downloading the dataset myself somehow seemed to do the trick (Strange, I know).
But anyways thank you very much :)
from nvae.
arash-vahdat
commented on July 19, 2024
I am very glad that it worked. Thanks @Lukelluke for the hint. I will add a link to this issue to help other folks that may run into the same issue.
from nvae.
Lukelluke
commented on July 19, 2024
It a great pleasure that i can do any help to this great job.
Thank you Dr.Vahdat again for your kindness of releasing this official implement !
Hoping that we can get more inspirations from this work which make VAE great again !
from nvae.
kaushik333
commented on July 19, 2024
@Lukelluke are you sure its epoch 5 and not 50? I run it with batch_size 8 and ~5000 iterations is 1 epoch (I know because train_nelbo gets printed only once per epoch). If youre using batch_size 4, I guess you're at 25th epoch?
Also, I had to stop my training ~20th epoch. But I never faced this issue.
from nvae.
kaushik333
commented on July 19, 2024
Dr. @arash-vahdat :
In order to train it on 256x256 images, are there any additional architectural changes or do I need to just alter the flags according to info provided in the paper?
from nvae.
Lukelluke
commented on July 19, 2024
Thank you so much! Dr.@arash-vahdat , I changed the frequency as you taught, and modify the '--learning_rate 1e-3' , hoping that everything will be ok.
Ps. I'm now trying to apply NVAE in audio field, however i countered some special problem:
- We know that in image field, we usually cut one pic to [n, n] shape, like 256256 / 6464, and i wanna try to feed audio feature in the shape of [batch, channel=1, frame, dimension of feature], and after looking into your implement, i feel that would be a hard job of make it adaptive to any dimension of pic, like [channel=3, m, n], where m != n can also work. Could you give me any suggestion or trick, that would be nice.
Hello, @kaushik333 , I reconfirmed that that 'nan' error happened during epoch 5, and i take the advice of Dr.arash-vahdat , modify the init learning rate to 1e-3, hoping that can run successfully after 5 epoch.
And congratulate you that run successfully, pity that my GPU can only support 4 batch size, lol
As for 256*256, as i mentioned that i tried to run successfully, and i just follow the README, download tfrecord files and preprocess to lmdb data format.
and as for command, all due to my gpu limitation, i reduced the --num_channels_enc 32 --num_channels_dec 32 and with --batch_size 1, it's pretty slow, but got unbelievable reconstruction result. But maybe the training epoch is not enough, the sampled result still not present human face, i will run ahead later.
And if you need, my pleasure to share pretrained ckpt model.
from nvae.
Related Issues (20)
- FID score of CelebA-HQ 256x256 HOT 1
- NomalDecoder & num_bits
- TypeError: batch_norm_backward_elemt() missing 1 required positional arguments: "count" HOT 1
- How to run without using parallelization? HOT 1
- Can you provide pretrained models? HOT 1
- why is there self.prior_ftr0 in the decoder model?
- Why some of the generate images by the official checkpoint of CelebA64 are NaN-value? HOT 2
- Query: CelebA HQ 256
- Query: Dataset CelebA-HQ 256x256 issue
- Query: FFHQ Pre-Processing HOT 3
- FFHQ Training
- CelebA-HQ 256x256 Data Pre-processing HOT 1
- Possible typo in the log_p() function
- ImageNet Checkpoint
- Question regarding traversing the latent space
- Why output for 3-rd channel is unused in Logistic mixture? HOT 1
- how can i use the code on my own dataset. if it's necessary to modify the code carefully myself? HOT 1
- "arch_instance" argument
- Problem while converting tfrecord to lmdb data AttributeError: 'bytes' object has no attribute 'cpu' HOT 4
- Question about KL computation HOT 1
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from nvae.