Comments (17)
 meritzio
commented on July 22, 2024
meritzio
commented on July 22, 2024
A profile of a (roughly) 2.5 minute export - As can be seen, major time is currently spent on determining group baffles (isGroupBaffle, over a minute), and obtaining face nodes (GetElemFaceNodes) via the CORBA platform (_omnipy.invoke).
| ncalls | tottime | percall | cumtime | percall | filename:lineno(function) |
|---|---|---|---|---|---|
| 9 | 107.646 | 11.961 | 107.652 | 11.961 | salomeToOpenFOAM.py:613(isGroupBaffle) |
| 396726 | 7.148 | 0.000 | 47.238 | 0.000 | salomeToOpenFOAM.py:61(init) |
| 2049220 | 2.185 | 0.000 | 31.037 | 0.000 | smeshBuilder.py:2648(GetElemFaceNodes) |
| 2208669 | 29.839 | 0.000 | 29.839 | 0.000 | {_omnipy.invoke} |
| 2049220 | 1.821 | 0.000 | 28.853 | 0.000 | SMESH_Mesh_idl.py:1111(GetElemFaceNodes) |
| 1708820 | 4.686 | 0.000 | 8.333 | 0.000 | salomeToOpenFOAM.py:77(Key) |
| 1708820 | 3.647 | 0.000 | 3.647 | 0.000 | {sorted} |
| 6119826 | 3.015 | 0.000 | 3.015 | 0.000 | {method 'write' of 'file' objects} |
| 29 | 0.000 | 0.000 | 1.808 | 0.062 | SMESH_Mesh_idl.py:547(GetIDs) |
| 1 | 0.000 | 0.000 | 1.793 | 1.793 | smeshBuilder.py:2688(GetIdsFromFilter) |
| 4556153 | 1.141 | 0.000 | 1.141 | 0.000 | {method 'append' of 'list' objects} |
| 513478 | 0.822 | 0.000 | 0.822 | 0.000 | {map} |
| 103019 | 0.092 | 0.000 | 0.811 | 0.000 | smeshBuilder.py:2567(GetNodeXYZ) |
| 103019 | 0.089 | 0.000 | 0.719 | 0.000 | SMESH_Mesh_idl.py:1072(GetNodeXYZ) |
| 56326 | 0.049 | 0.000 | 0.409 | 0.000 | smeshBuilder.py:2620(GetElemNodes) |
| 56326 | 0.044 | 0.000 | 0.360 | 0.000 | SMESH_Mesh_idl.py:1093(GetElemNodes) |
| 1652584 | 0.350 | 0.000 | 0.350 | 0.000 | salomeToOpenFOAM.py:508(debugPrint) |
| 256739 | 0.345 | 0.000 | 0.345 | 0.000 | {method 'sort' of 'list' objects} |
| 396727 | 0.317 | 0.000 | 0.317 | 0.000 | salomeToOpenFOAM.py:442() |
| 6 | 0.185 | 0.031 | 0.185 | 0.031 | {method 'close' of 'file' objects} |
| 256739 | 0.159 | 0.000 | 0.159 | 0.000 | {range} |
| 854444 | 0.081 | 0.000 | 0.081 | 0.000 | {len} |
| 2 | 0.000 | 0.000 | 0.048 | 0.024 | smeshBuilder.py:2483(GetElementsByType) |
| 2 | 0.000 | 0.000 | 0.048 | 0.024 | SMESH_Mesh_idl.py:1033(GetElementsByType) |
| 6 | 0.017 | 0.003 | 0.017 | 0.003 | {open} |
| 3 | 0.000 | 0.000 | 0.002 | 0.001 | smeshBuilder.py:2065(GetGroups) |
| 3 | 0.000 | 0.000 | 0.002 | 0.001 | SMESH_Mesh_idl.py:826(GetGroups) |
| 1 | 0.000 | 0.000 | 0.001 | 0.001 | smeshBuilder.py:888(GetFilter) |
| 39 | 0.000 | 0.000 | 0.001 | 0.000 | SMESH_Group_idl.py:107(GetType) |
| 1 | 0.000 | 0.000 | 0.001 | 0.001 | smeshBuilder.py:1170(New) |
| 1 | 0.000 | 0.000 | 0.001 | 0.001 | smeshBuilder.py:394(init_smesh) |
| 1 | 0.000 | 0.000 | 0.001 | 0.001 | smeshBuilder.py:525(SetCurrentStudy) |
| 1 | 0.000 | 0.000 | 0.000 | 0.000 | smeshBuilder.py:702(GetCriterion) |
from salometoopenfoam.
meritzio
commented on July 22, 2024
From the above we can see that the hashing and sorting is somewhat inefficient, but is second to the determining baffles and obtaining face nodes. Call counts to _omnipy.invoke are almost exclusive to obtaining face nodes (2049220 out of 2208669), some way of obtaining the data in fewer calls would be ideal.
from salometoopenfoam.
 nicolasedh
commented on July 22, 2024
nicolasedh
commented on July 22, 2024
Nicely done!
Did I do something really stupid here? isGroupBaffle doesn't really do
much. It basically checks if all the face IDs in all groups of faces aren't
in among the external faces.
A dirty workaround would be to skip the test unless it's activated. Does it
improve speed?
Instead of checking all IDs in python maybe we could apply a filter based
on external faces but only inte that particular group. Now if the length of
the filtered group is the same as the original then we are good.
What do you think?
Den 15 dec. 2017 19:03 skrev "Samuel Woodhead" <[email protected]>:
From the above we can see that the hashing and sorting is somewhat
inefficient, but is second to the determining baffles and obtaining face
nodes. Call counts to _omnipy.invoke are almost exclusive to obtaining face
nodes (2049220 out of 2208669), some way of obtaining the data in fewer
calls would be ideal.
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#2 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ADXI5LJzOdebNMFPxT3x7VVP1p9gQvLcks5tArR8gaJpZM4Q8rkf>
.
from salometoopenfoam.
meritzio
commented on July 22, 2024
No need to drop the functionality! The problem was with the use of data structure - Lists:
If I had a list of faces [1, 2, 3, 4, 5] and I wanted to check the id 5 was in there, I would have to iterate linearly - 1, 2, 3, 4, 5 - and then I've found this id - so it's a group baffle. That was happening with the isGroupBaffle function. By converting it to the data type set - we have the same speed as a dictionary looking for a unique item - it's hashed in like a key, but without a returning value - so we know immediately whether it's in the set or not. For more info : https://wiki.python.org/moin/TimeComplexity
I've sent a pull request with this implementation - I've compared the changes in times and it seems to drop the baffle check from being a time issue - I've checked the exports myself but if you have time a second check would be appreciated :)
You made a good suggestion about comparing the length - but I think this change means we shouldn't have to do that.
from salometoopenfoam.
nicolasedh
commented on July 22, 2024
Very nice work!
I'll merge tonight when I get home!
Best regards
Nicolas
Den 16 dec. 2017 18:59 skrev "Samuel Woodhead" <[email protected]>:
… No need to drop the functionality! The problem was with the use of data
structure - Lists:
If I had a list of faces [1, 2, 3, 4, 5] and I wanted to check the id 5
was in there, I would have to iterate linearly - 1, 2, 3, 4, 5 - and then
I've found this id - so it's a group baffle. That was happening with the
isGroupBaffle function. By converting it to the data type set - we have the
same speed as a dictionary looking for a unique item - it's hashed in like
a key, but without a returning value - so we know immediately whether it's
in the set or not. For more info : https://wiki.python.org/moin/
TimeComplexity
I've sent a pull request with this implementation - I've compared the
changes in times and it seems to drop the baffle check from being a time
issue - I've checked the exports myself but if you have time a second check
would be appreciated :)
You made a good suggestion about comparing the length - but I think this
change means we shouldn't have to do that.
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#2 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ADXI5CjNn8gHUmHCU87bJvLgW53ggi0Vks5tBATogaJpZM4Q8rkf>
.
from salometoopenfoam.
nicolasedh
commented on July 22, 2024
It's merged. Again really nice work!
Welcome as a contributor! I've should have added you in your last pull request. Sorry about that.
I'm still having trouble with installing salome on the new os. But then again I manage about 5 minutes i front of the machine per day so it will take time =).
/Nicolas
from salometoopenfoam.
meritzio
commented on July 22, 2024
From some further profiling it seems that the remaining bottleneck of the exporter lies within the MeshBuffer class constructor - specifically making calls to obtain the faces.
I've tried a couple of methods to try and reduce the CORBA overhead:
- Parallel loops (running 2 or more threads, running GetElemFaceNodes across these threads) but this ended up slowing the script down with each additional core. So it seems that this CORBA implementation is not parallel, or there is some sort of settings that must be invoked to enable the calls to be parallel - it may be that I post a query on the forums.
- Attempting to call the method omnipy.invoke directly - but I couldn't get this to work, and it would probably introduce a version dependency that defeats the point of using Python :)
It may be that we make some sort of c++ binding option that can be compiled to obtain the SMESH pointer to get the faces in a single call - then provide the user with an option to run the native built binding if better performance is necessary.
Any ideas that could assist?
Happy holidays!
Sam.
from salometoopenfoam.
nicolasedh
commented on July 22, 2024
Hi!
Thanks for your effort in this!
The only thing I can think of would be to study how for example unvToFoam
to things. Mesh conversion should not take this long so it's probably
something bad at a fundamental level.
I'll let this "problem" simmer in the back of my mind. Maybe I'll come up
with someting =)
And happy holidays to you to!
/N
2017-12-24 15:18 GMT+01:00 Samuel Woodhead <[email protected]>:
… From some further profiling it seems that the remaining bottleneck of the
exporter lies within the MeshBuffer class constructor - specifically making
calls to obtain the faces.
I've tried a couple of methods to try and reduce the CORBA overhead:
- Parallel loops (running 2 or more threads, running GetElemFaceNodes
across these threads) but this ended up slowing the script down with each
additional core. So it seems that this CORBA implementation is not
parallel, or there is some sort of settings that must be invoked to enable
the calls to be parallel - it may be that I post a query on the forums.
- Attempting to call the method omnipy.invoke directly - but I
couldn't get this to work, and it would probably introduce a version
dependency that defeats the point of using Python :)
It may be that we make some sort of c++ binding option that can be
compiled to obtain the SMESH pointer to get the faces in a single call -
then provide the user with an option to run the native built binding if
better performance is necessary.
Any ideas that could assist?
Happy holidays!
Sam.
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#2 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ADXI5HZCbxMHItCL94M0lBawiiop6Pt-ks5tDl0xgaJpZM4Q8rkf>
.
from salometoopenfoam.
meritzio
commented on July 22, 2024
Just so you know. I haven't forgot about this! I keep taking a look from time to time to see if anything sticks out. I've also posted on the salome forum so with any luck i'll get a response.
The speed has become more convenient for my use, it's taken hour long macro meshes exports down to about 10 minutes. Especially ones with many boundary conditions. But even so that's quite a lot so I'm interested to bring the speed down more!
from salometoopenfoam.
nicolasedh
commented on July 22, 2024
Great thanks for the update!
In the mean time I solved one of the problems I had while reinstall Salome.
Turns out one of my RAM modules began to fail.
The during the debugging I switched to Ubuntu 17.10. and I can't install
Salome. All the precompiled versions complain about wrong protobuf version.
Is it anything you've encountered?
I had the same issue with paraview and there was a cmakr option
VTK_USE_SYSTEM_PROTBUF=ON . I tried compilation of Salome to se if I
could use the same option.
Anything you've come across?
Best regards
Nicolas
Den 16 feb. 2018 21:44 skrev "Samuel Woodhead" <[email protected]>:
… Just so you know. I haven't forgot about this! I keep taking a look from
time to time to see if anything sticks out. (I've also posted on the salome
forum)[http://www.salome-platform.org/forum/forum_12/683928624] so with
any luck i'll get a response.
The speed has become more convenient for my use, it's taken hour long
macro meshes exports down to about 10 minutes. Especially ones with many
boundary conditions. But even so that's quite a lot so I'm interested to
bring the speed down more!
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#2 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ADXI5F7x63nAf6Q5rYlhiiroOhJMFQzwks5tVeingaJpZM4Q8rkf>
.
from salometoopenfoam.
meritzio
commented on July 22, 2024
It's not something I've had a problem with because I'm using Fedora and Windows to test my code. Perhaps you need to update (apt-get) the global protobuf package? It seems to be a compiler related package.
from salometoopenfoam.
nicolasedh
commented on July 22, 2024
That was my thought but it seems Salome uses the system Qt which is
compiled with version 3 but some (one?) of the Salome packages where built
an older version of protobuf. When that package tries to load the system Qt
I get the error.
I did try to compile Salome but man it's such a mess. Lots of third party
dependencies which has to be compiled. And you have to find the exact
version.
I think I'll just wait for Ubuntu 18.04 which is LTS and hope that any of
the prebuilt packages works by then. :-(
Den 17 feb. 2018 17:09 skrev "Samuel Woodhead" <[email protected]>:
… It's not something I've had a problem with because I'm using Fedora and
Windows to test my code. Perhaps you need to update (apt-get) the global
protobuf package? It seems to be a compiler related package
<https://packages.ubuntu.com/en/trusty/protobuf-compiler>.
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#2 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ADXI5DY8VqnXLNBAdrdW_Jp4HW8UYD17ks5tVvmsgaJpZM4Q8rkf>
.
from salometoopenfoam.
meritzio
commented on July 22, 2024
Ah! That's a shame! I think it is quite hard to compile it all by source, that's something that really needs to be improved upon because it's not well explained. It makes writing compiled extensions quite tough going too.
I think the way I'm going to try tackle this is by getting back to parallel calls using multithreaded corba. The plan is to give the option of the user choosing the amount of threads they want to use, and then splitting the face integer collection task across these. From the linked diagram it seems that we need to start multiple client sockets to the corba 'naming service', once we have the IOR of the mesh I think we might be able to do some light parallelisation to save time. I'm not sure if the plan is feasible yet but it's worth looking into.
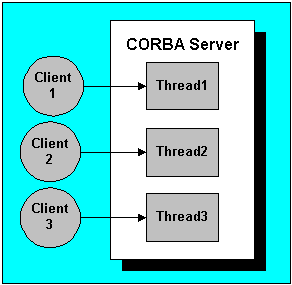{kind=link}
--update-- using omniorb we can get our path to the configuration file
import os
os.environ['OMNIORB_CONFIG']we can see that there are not many properties set if the user is using an automatically generated configuration file. In the omniORB configuration documentation we can see the following information about threads per CORBA connection:
threadPerConnectionPolicy default = 1
If true (the default), the ORB dedicates one server thread to each incoming connection. Setting it false means the server should use a thread pool.
So, it's currently set to one server thread per connection by default. I think I might try to configure this to be a greater number, and see if that will bring the time down. However, this means having to modify a users config file, so it may be a better option to make multiple connections to get the object reference.
from salometoopenfoam.
nicolasedh
commented on July 22, 2024
Hi, good news version 8.4 was released and it works with Ubuntu 17.10.
I might now have time to look at some of the issues again.
Yes multithreaded sounds good. But maybe we might somehow reduce the number
of calls. I'll think about it. Maybe the facepoints are given implicitly by
the order of points in the cell?
Den 24 feb. 2018 13:24 skrev "Samuel Woodhead" <[email protected]>:
Ah! That's a shame! I think it is quite hard to compile it all by source,
that's something that really needs to be improved upon because it's not
well explained. It makes writing compiled extensions quite tough going too.
I think the way I'm going to try tackle this is by getting back to parallel
calls using multithreaded corba
<https://docs.oracle.com/cd/E12531_01/tuxedo100/cservers/wwimages/Thrd_blk.gif>.
The plan is to give the option of the user choosing the amount of threads
they want to use, and then splitting the face integer collection task
across these. From the linked diagram it seems that we need to start
multiple client sockets to the corba 'naming service', once we have the
[IOR] (http://docs.salome-platform.org/5/kernel/user/kernel_salome.html) of
the mesh I think we might be able to do some light parallelisation to save
time. I'm not sure if the plan is feasible yet but it's worth looking into.
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#2 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ADXI5CjP0ogHkG_QQfwRdMIFfTLLUuMXks5tX_-XgaJpZM4Q8rkf>
.
from salometoopenfoam.
nicolasedh
commented on July 22, 2024
I did have time to try out your recent changes on salome 8.4.
Looks really good!
With your changed it seems like the time to convert is linear with the
number of cells! While before it was almost quadratic. Great work!
2018-03-01 20:34 GMT+01:00 Nicolas Edh <[email protected]>:
… Hi, good news version 8.4 was released and it works with Ubuntu 17.10.
I might now have time to look at some of the issues again.
Yes multithreaded sounds good. But maybe we might somehow reduce the
number of calls. I'll think about it. Maybe the facepoints are given
implicitly by the order of points in the cell?
Den 24 feb. 2018 13:24 skrev "Samuel Woodhead" ***@***.***>:
> Hi, good news version 8.4 was released and it works with Ubuntu 17.10.
>
> I might now have time to look at some of the issues again.
>
> Yes multithreaded sounds good. But maybe we might somehow reduce the
> number of calls. I'll think about it. Maybe the facepoints are given
> implicitly by the order of points in the cell?
>
>
>
>
> Den 24 feb. 2018 13:24 skrev "Samuel Woodhead" ***@***.***
> >:
>
> Ah! That's a shame! I think it is quite hard to compile it all by source,
> that's something that really needs to be improved upon because it's not
> well explained. It makes writing compiled extensions quite tough going too.
>
> I think the way I'm going to try tackle this is by getting back to
> parallel calls using multithreaded corba
> <https://docs.oracle.com/cd/E12531_01/tuxedo100/cservers/wwimages/Thrd_blk.gif>.
> The plan is to give the option of the user choosing the amount of threads
> they want to use, and then splitting the face integer collection task
> across these. From the linked diagram it seems that we need to start
> multiple client sockets to the corba 'naming service', once we have the
> [IOR] (http://docs.salome-platform.org/5/kernel/user/kernel_salome.html)
> of the mesh I think we might be able to do some light parallelisation to
> save time. I'm not sure if the plan is feasible yet but it's worth looking
> into.
>
> —
> You are receiving this because you authored the thread.
> Reply to this email directly, view it on GitHub
> <#2 (comment)>,
> or mute the thread
> <https://github.com/notifications/unsubscribe-auth/ADXI5CjP0ogHkG_QQfwRdMIFfTLLUuMXks5tX_-XgaJpZM4Q8rkf>
> .
>
>
>
from salometoopenfoam.
meritzio
commented on July 22, 2024
Glad I can be of assistance!
I have uploaded a parallel script on the following branch source. Based on the thread count specified the array of volumes is partitioned by the thread count and handled across the threads, then rejoined once all work is complete.
If you try it out, you'll notice as you increase the number of threads - the process seems to take longer than just a single thread, call latency is introduced, so clearly the parallel calls are being blocked... I can't seem to find any CORBA configuration settings that will allow the server to multithread (I probably need more searching to crack it) - it may be that this script is adapted to make several client connections to the naming server across the threads to remain compliant with the 'one thread per connection' policy. This would mean setting up a client connection across each thread and getting the object reference using the IOR.
Unfortunately, it seems to be a lot of complexity to make the thing faster...
from salometoopenfoam.
nicolasedh
commented on July 22, 2024
Wow! I wish I could help but the only parallel experience I have is with
MPI. I've never done any threading except for android which is fairly easy.
To bad it's blocked! Would have been nice it it worked, but still nice
effort!
Bets regards
Nicolas
Den 11 mars 2018 11:46 skrev "Samuel Woodhead" <[email protected]>:
… Glad I can be of assistance!
I have uploaded a parallel script on the following branch source
<https://github.com/meritzio/salomeToOpenFOAM/blob/parallel/salomeToOpenFOAM.py>.
Based on the thread count specified
<https://github.com/meritzio/salomeToOpenFOAM/blob/parallel/salomeToOpenFOAM.py#L54>
the array of volumes is partitioned by the thread count and handled across
the threads, then rejoined once all work is complete.
If you try it out, you'll notice as you increase the number of threads -
the process seems to take longer than just a single thread, call latency is
introduced, so clearly the parallel calls are being blocked... I can't seem
to find any CORBA configuration settings that will allow the server to
multithread (I probably need more searching to crack it) - it may be that
this script is adapted to make several client connections to the naming
server across the threads to remain compliant with the 'one thread per
connection' policy. This would mean setting up a client connection across
each thread and getting the object reference using the IOR
<https://en.wikipedia.org/wiki/Interoperable_Object_Reference>.
Unfortunately, it seems to be a lot of complexity to make the thing
faster...
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#2 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/ADXI5LWJvEbTRLSlKB7hpoxagBJLxuLUks5tdQCDgaJpZM4Q8rkf>
.
from salometoopenfoam.
Related Issues (2)
- Prabal HOT 1
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from salometoopenfoam.