Comments (6)
 dopc
commented on May 18, 2024
dopc
commented on May 18, 2024
I think it is related with HDBSCAN. You can check here, original docs.
from bertopic.
 MaartenGr
commented on May 18, 2024
MaartenGr
commented on May 18, 2024
Unfortunately, the soft clustering is still an experimental feature that does have its fair share of open issues if you look through the HDBSCAN repo. As of this moment, it does seem that the probabilities for some documents do not represent the topics they were assigned to. Having said that, after some testing, it does seem that 98,9% of the probabilities are correctly assigned. The ones that aren't do match with their second highest probability. Fortunately, this means that the probabilities itself still can be interpreted although you should be careful indeed when blindly taking the highest probability.
from bertopic.
 arielibaba
commented on May 18, 2024
arielibaba
commented on May 18, 2024
Thanks you guys for being responsive.
Indeed, it seems that the soft clustering for HDBSCAN still has to be improved.
Anyway, I will leverage the concept of exemplar points that they use in the documentation as it seems to be more reliable.
from bertopic.
 firmai
commented on May 18, 2024
firmai
commented on May 18, 2024
Hey, not entirely sure how to proceed, what is the best way to get probabilities over documents: currently I have a 100% disconnect, is this normal.
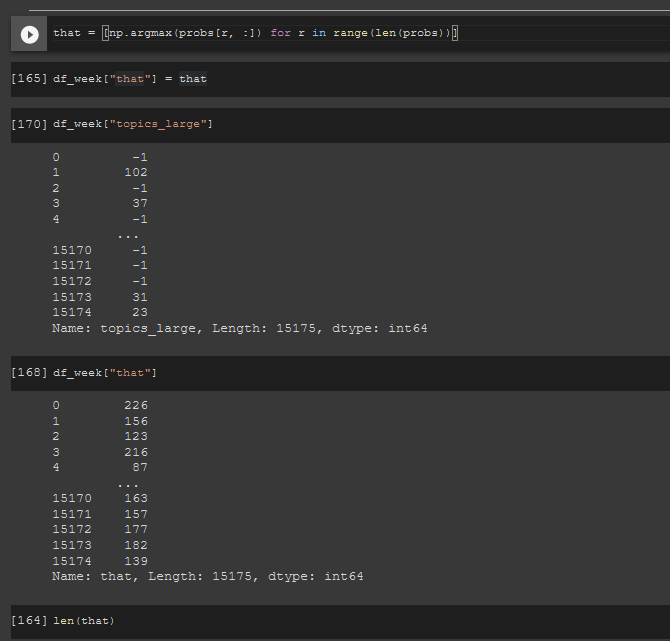
from bertopic.
 daviddiazsolis
commented on May 18, 2024
daviddiazsolis
commented on May 18, 2024
Hello everyone, I faced the same issue, and did some further research on the HDBSCAN repo and found there are some new commits that propose a way around the problem. It is not a perfect solution but the new probabilities are a much closer match than before.
Following the flat.py hdbscan_flat functions, the solutions involve three steps:
- using your own hdbscan model, so first you need to define one
import hdbscan
clusterer = hdbscan.HDBSCAN(min_cluster_size=10, prediction_data=True,cluster_selection_method='eom')
- then, call bertopic using that hdbscan model
from bertopic import BERTopic
topic_model = BERTopic(language="multilingual", calculate_probabilities=True, verbose=True,
hdbscan_model=clusterer)
#we get the old topics, and probabilities with the issue
topics, probs = topic_model.fit_transform(docs)
that=[np.argmax(probs[r,:]) for r in range(len(probs))] #max probabilities don't match with the topics
- we get the embedings from the original model and then run the hdbscan_flat functions
cluster=topic_model.hdbscan_model
embs=topic_model.umap_model.embedding_
from hdbscan.flat import (HDBSCAN_flat,
approximate_predict_flat,
membership_vector_flat,
all_points_membership_vectors_flat)
def n_clusters_from_labels(labels_):
return np.amax(labels_) + 1
n_clusters = n_clusters_from_labels(cluster.labels_)
When we ask for flat clustering with same n_clusters,
clusterer_flat = HDBSCAN_flat(embs, n_clusters=n_clusters,
cluster_selection_method='eom')
#we get the new topics, and probabilities
topics2=clusterer_flat.labels_
probs2 = all_points_membership_vectors_flat(clusterer_flat)
that2=[np.argmax(probs2[r,:]) for r in range(len(probs2))]
now the prob2 match much closer to topics 2 and that2
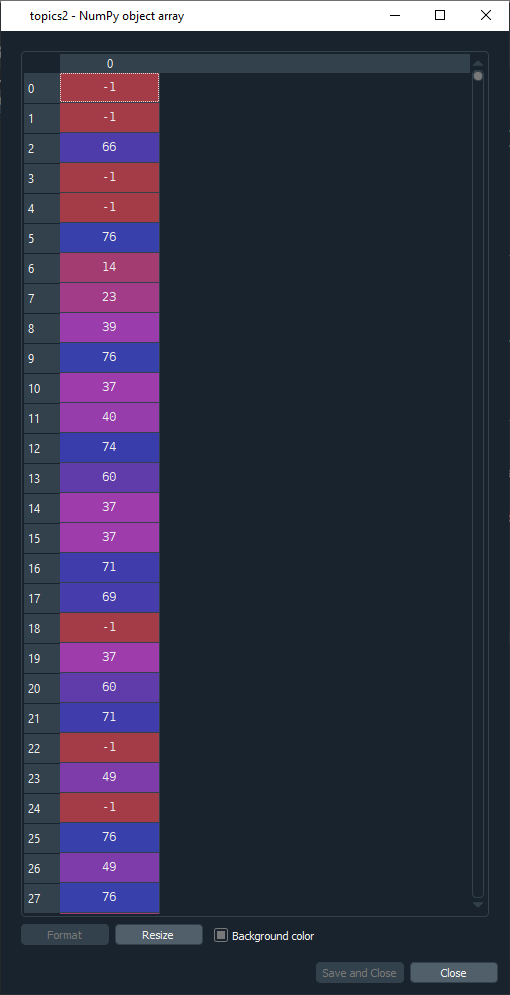

I hope this helps
from bertopic.
 wsosnowski
commented on May 18, 2024
wsosnowski
commented on May 18, 2024
Hi,
the problem with inconsistency during inference phase is caused by UMAP not HDBSCAN anymore and there is a very easy fix - just create custom umap model and fix the random_state:
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine', random_state=42)
topic_model = BERTopic(umap_model=umap_model, verbose=True, calculate_probabilities=True)
from bertopic.
Related Issues (20)
- list index out of range HOT 4
- AttributeError: 'BERTopic' object has no attribute 'c_tf_idf' HOT 3
- Dynamic Topic Modelling (Quantized Models / Vectorized DBs) HOT 3
- Assigning documents to multiple topics using zero-shot topic modeling HOT 1
- using representation model takes much longer HOT 1
- Best-performing embedding models? HOT 1
- Skip topic representation when reducing topics wiht nr_topic parameter HOT 1
- Issue with loading BERTopic model. 'NNDescent' object has no attribute '_bit_trees' HOT 3
- Problem with fitting and transforming model HOT 2
- Semantic Sentence Tokenization HOT 1
- self._c_tf_idf can make more efficient use of vectorizer model HOT 3
- Drop support for Python 3.7 HOT 3
- Issue when using topic representation HOT 1
- Reducing Outliers of Loaded Model HOT 1
- `IndexError: list index out of range` when using zeroshot_topic_list in 0.16.1 HOT 10
- Alternatively, you can pin your installation to the old version, e.g. `pip install openai==0.28`How to slove this problem?
- Alternatively, you can pin your installation to the old version, e.g. `pip install openai==0.28` HOT 1
- Add support for Python 3.10+ HOT 2
- [inhomogeneous shape unresolved] [Colab] ValueError: setting an array element with a sequence. The requested array has an inhomogeneous shape after 1 dimensions. The detected shape was (2,) + inhomogeneous part. HOT 1
- Huggingface transformer does not load as expected HOT 3
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from bertopic.