Comments (28)
 MoFtZ
commented on June 2, 2024
MoFtZ
commented on June 2, 2024
hi @sunxiaotianmg. Two loops should work - are you able to provide example code?
from ilgpu.
 sunxiaotianmg
commented on June 2, 2024
sunxiaotianmg
commented on June 2, 2024
static void MyKernel(
Index1D index,
ArrayView<int> dataView,
int constant)
{
dataView[index] = index + constant;
var nRank = constant;
var contourNum = 9;
for (int k = 0; k <= contourNum; k++)
{
}
//大于二个for 循环编译不通过
for (int k = contourNum + 1; k < nRank - contourNum; k++)
{
}
for (int k = nRank - contourNum; k < nRank; k++)
{
}
}from ilgpu.
MoFtZ
commented on June 2, 2024
That works for me without issue.
What version of .NET are you using?
When the compilation fails, ILGPU should raise an exception/error.
What does the error message say?
What does the InnerException message say?
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
.NET7
Simple---->SimpleKernel
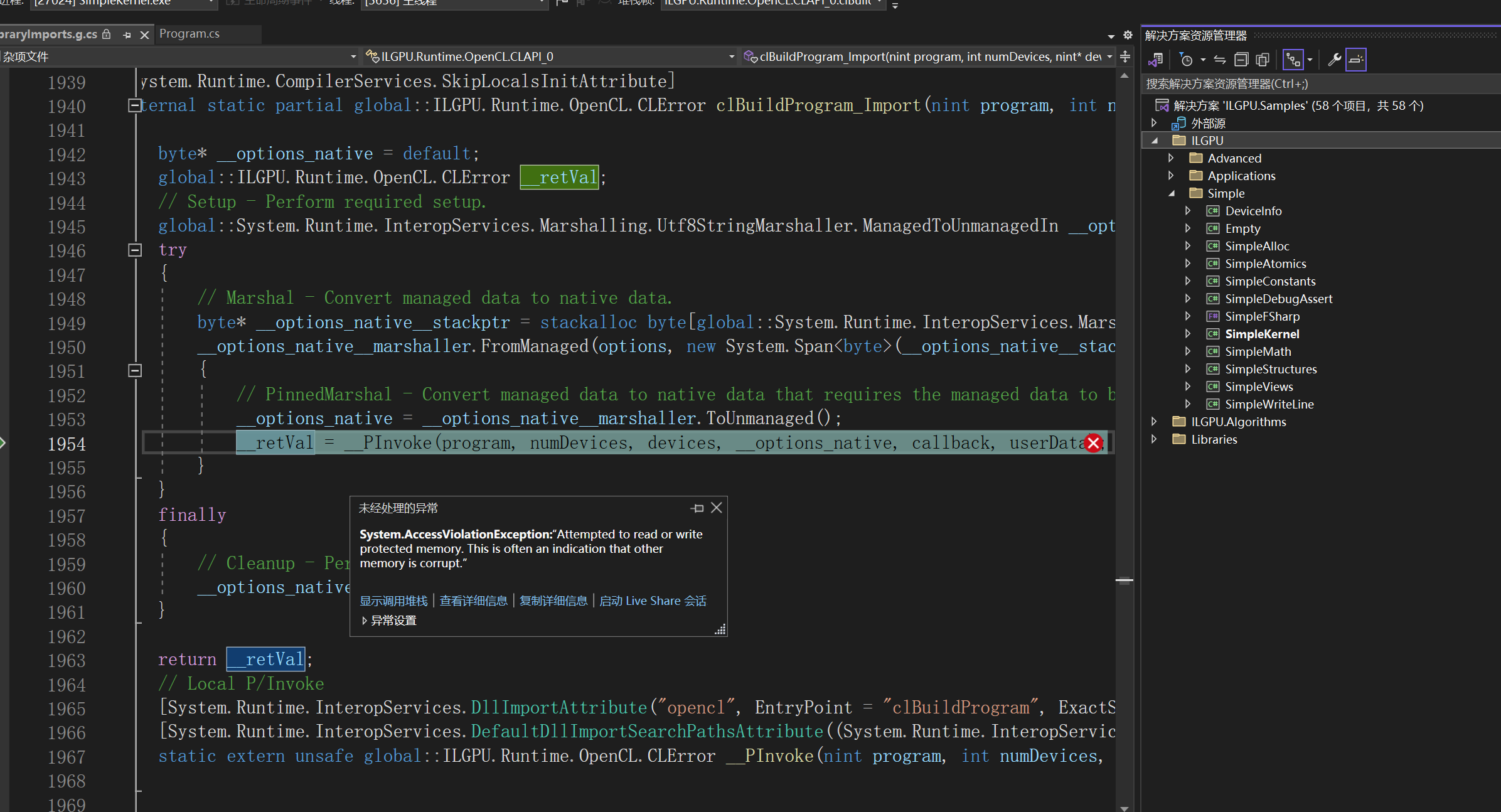
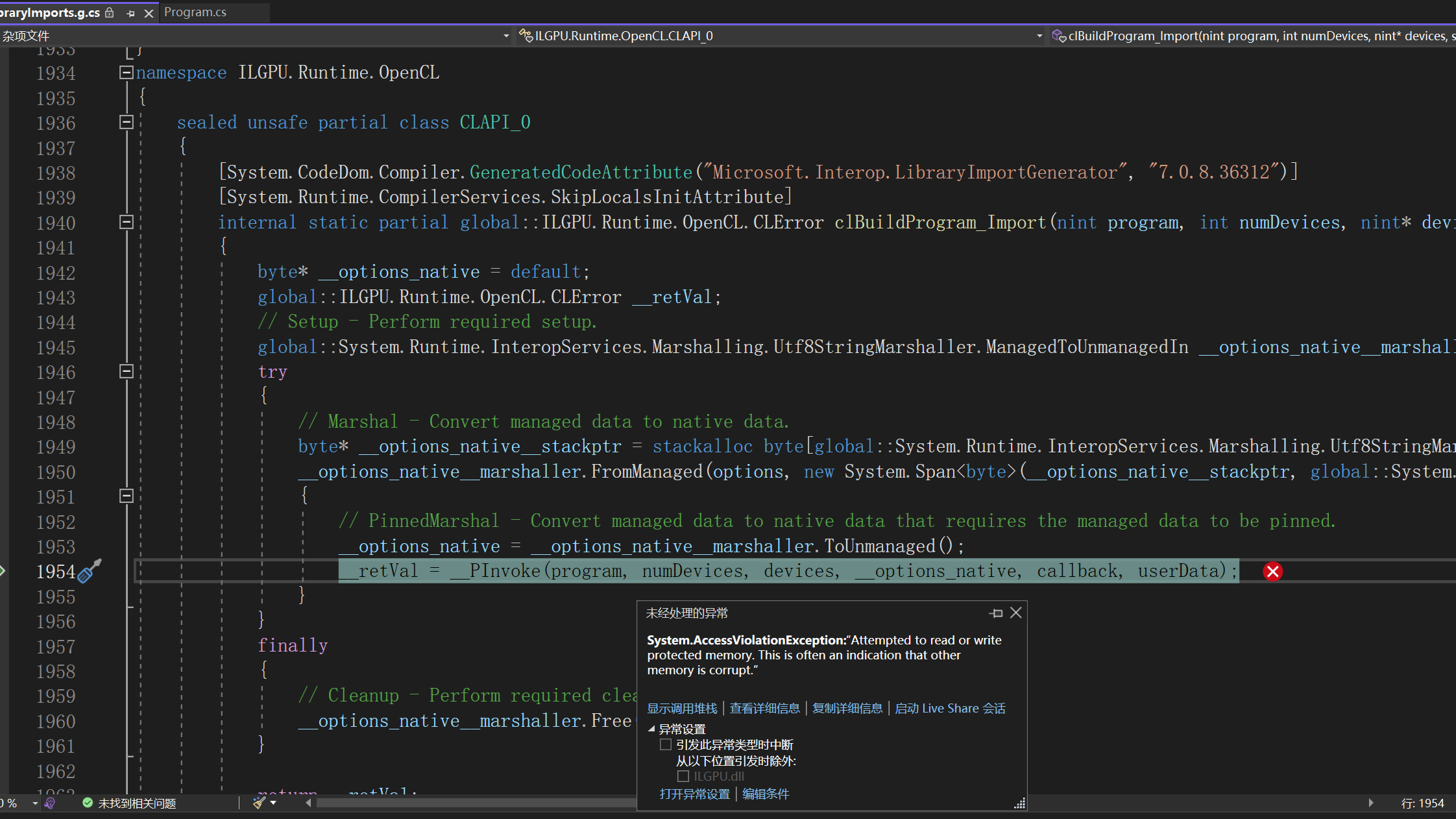
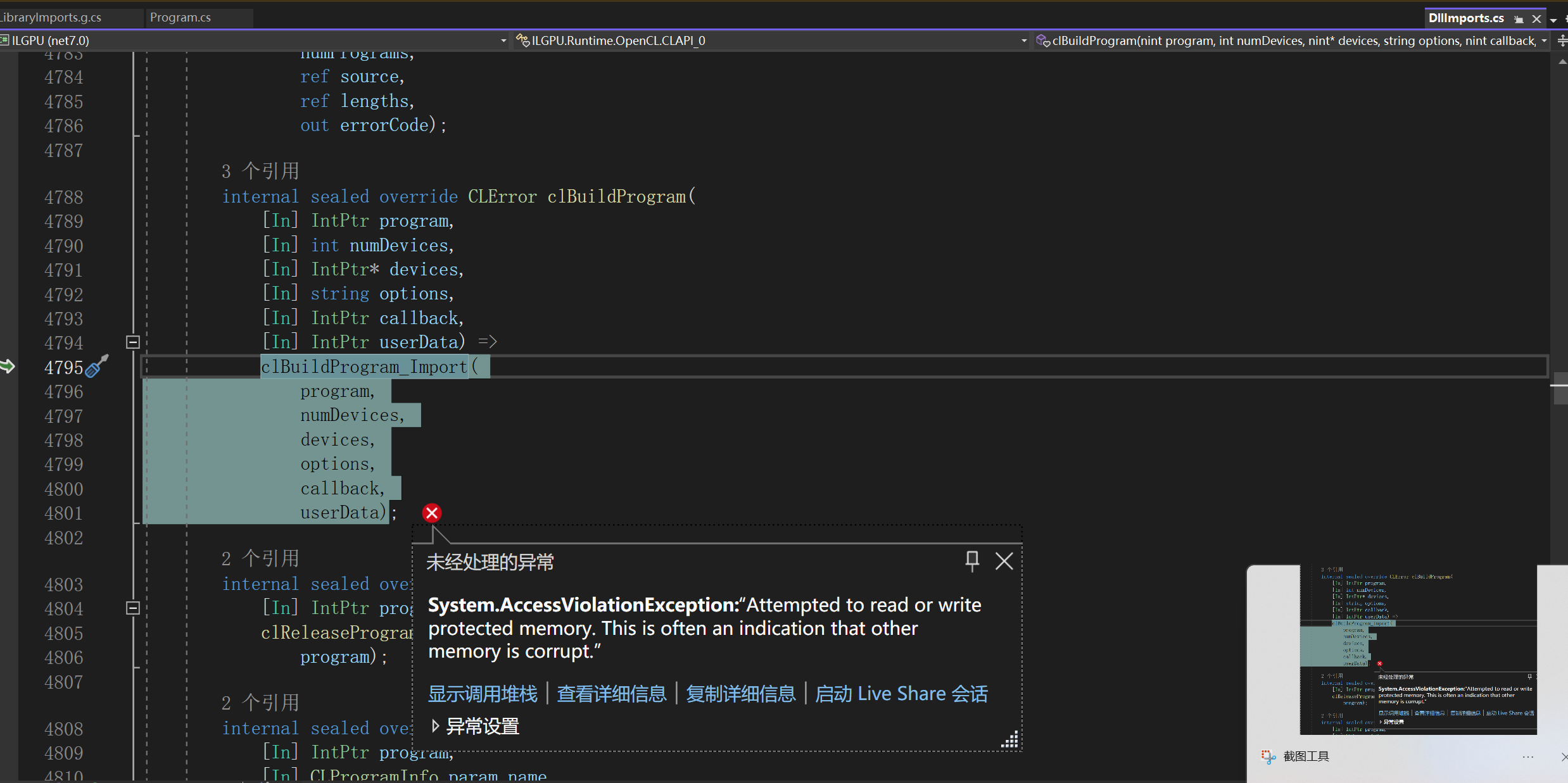
__retVal = __PInvoke(program, numDevices, devices, __options_native, callback, userData);
System.AccessViolationException:“Attempted to read or write protected memory. This is often an indication that other memory is corrupt.”
from ilgpu.
MoFtZ
commented on June 2, 2024
I replaced your example kernel with the one used in the SimpleKernel sample project, and it was all fine for me.
What is __PInvoke?
Are you able to provide a full example program please?
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
// ---------------------------------------------------------------------------------------
// ILGPU Samples
// Copyright (c) 2021 ILGPU Project
// www.ilgpu.net
//
// File: Program.cs
//
// This file is part of ILGPU and is distributed under the University of Illinois Open
// Source License. See LICENSE.txt for details.
// ---------------------------------------------------------------------------------------
using ILGPU;
using ILGPU.Runtime;
using System;
namespace SimpleKernel
{
class Program
{
/// <summary>
/// A simple 1D kernel. Simple kernels also support other dimensions via Index2 and Index3.
/// Note that the first argument of a kernel method is always the current index. All other parameters
/// are optional. Furthermore, kernels can only receive structures as arguments; reference types are
/// not supported.
///
/// Memory buffers are accessed via ArrayViews (<see cref="ArrayView{T}"/>, <see cref="ArrayView{T, TIndex}"/>).
/// These views encapsulate all memory accesses and hide the underlying native pointer operations.
/// Similar to ArrayViews, a VariableView (<see cref="VariableView{T}"/>) points to a single variable in memory.
/// In other words, a VariableView is a special ArrayView with a length of 1.
/// </summary>
/// <param name="index">The current thread index.</param>
/// <param name="dataView">The view pointing to our memory buffer.</param>
/// <param name="constant">A uniform constant.</param>
static void MyKernel(
Index1D index, // The global thread index (1D in this case)
ArrayView<int> dataView, // A view to a chunk of memory (1D in this case)
int constant) // A sample uniform constant
{
dataView[index] = index + constant;
var nRank = constant;
var contourNum = 9;
for (int k = 0; k <= contourNum; k++)
{
}
//大于二个for 循环编译不通过
for (int k = contourNum + 1; k < nRank - contourNum; k++)
{
}
for (int k = nRank - contourNum; k < nRank; k++)
{
}
}
public static void GaussianKeneral(Index1D i, int nRank, int contourNum, ArrayView<double> matrixArray, ArrayView<double> kernelWeightCoefficientArray, ArrayView<double> tempDataMatrixArray)
{
int num2 = i * nRank;
double num3 = 0.0;
int num4 = 0;
int num5 = 0;
int num6 = 0;
int num7 = 0;
for (int k = 0; k <= contourNum; k++)
{
num3 = 0.0;
num4 = 0;
num6 = k + contourNum;
for (int l = 0; l <= num6; l++)
{
num4 = contourNum + l - k;
num3 += matrixArray[num2 + l] * kernelWeightCoefficientArray[num4];
}
tempDataMatrixArray[num2 + k] = num3;
}
//大于二个for 循环编译不通过
for (int k = contourNum + 1; k < nRank - contourNum; k++)
{
num3 = 0.0;
num4 = 0;
num6 = k + contourNum;
num7 = k - contourNum;
for (int l = num7; l <= num6; l++)
{
num4 = l - num7;
num3 += matrixArray[num2 + l] * kernelWeightCoefficientArray[num4];
}
tempDataMatrixArray[num2 + k] = num3;
}
for (int k = nRank - contourNum; k < nRank; k++)
{
num3 = 0.0;
num4 = 0;
num5 = k - contourNum;
for (int l = k - contourNum; l < nRank; l++)
{
num4 = contourNum + l - k;
num3 += matrixArray[num2 + num5] * kernelWeightCoefficientArray[num4];
num5++;
}
tempDataMatrixArray[num2 + k] = num3;
}
}
/// <summary>
/// Launches a simple 1D kernel.
/// </summary>
static void Main()
{
// Create main context
using var context = Context.CreateDefault();
// For each available device...
foreach (var device in context)
{
// Create accelerator for the given device
using var accelerator = device.CreateAccelerator(context);
Console.WriteLine($"Performing operations on {accelerator}");
// Compiles and loads the implicitly grouped kernel with an automatically determined
// group size and an associated default stream.
// This function automatically compiles the kernel (or loads the kernel from cache)
// and returns a specialized high-performance kernel launcher.
// Use LoadAutoGroupedKernel to create a launcher that requires an additional accelerator-stream
// parameter. In this case the corresponding call will look like this:
// var kernel = accelerator.LoadautoGroupedKernel<Index, ArrayView<int>, int>(MyKernel);
// For more detail refer to the ImplicitlyGroupedKernels or ExplicitlyGroupedKernels sample.
var kernel = accelerator.LoadAutoGroupedStreamKernel<
Index1D, ArrayView<int>, int>(MyKernel);
//var kernel2 = accelerator.LoadAutoGroupedStreamKernel<
// Index1D, int, int ,ArrayView<double>, ArrayView<double>, ArrayView<double>>(GaussianKeneral);
using var buffer = accelerator.Allocate1D<int>(1024);
// Launch buffer.Length many threads and pass a view to buffer
// Note that the kernel launch does not involve any boxing
kernel((int)buffer.Length, buffer.View, 42);
// Reads data from the GPU buffer into a new CPU array.
// Implicitly calls accelerator.DefaultStream.Synchronize() to ensure
// that the kernel and memory copy are completed first.
var data = buffer.GetAsArray1D();
for (int i = 0, e = data.Length; i < e; ++i)
{
if (data[i] != 42 + i)
Console.WriteLine($"Error at element location {i}: {data[i]} found");
}
}
}
}
}from ilgpu.
MoFtZ
commented on June 2, 2024
Thank you very much for that @sunxiaotianmg.
I was able to compile and run that code without issue.
Have you tried updating your Cuda drivers?
What version of .NET 7 are you using? v7.0.10?
https://dotnet.microsoft.com/en-us/download/dotnet/7.0
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
AMD drivers
from ilgpu.
MoFtZ
commented on June 2, 2024
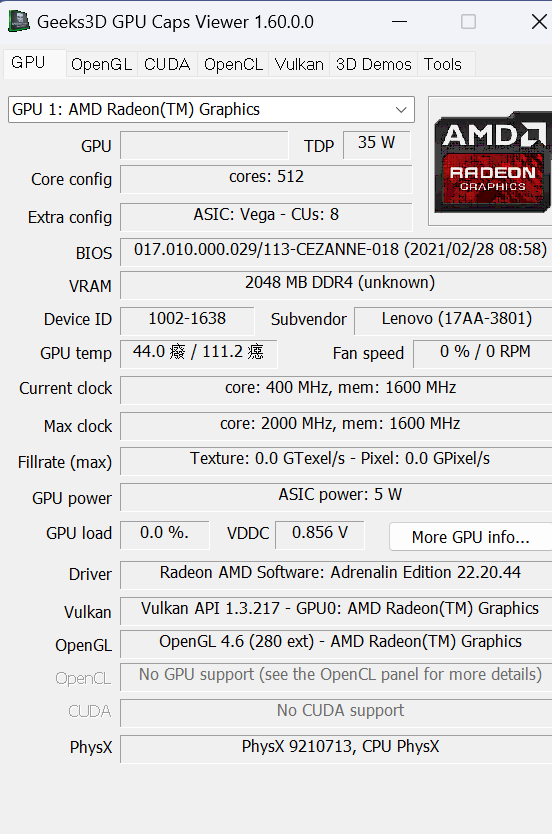
I would suggest you try updating your AMD/Display/OpenCL drivers.
Do you know which accelerator it is failing on?
The integrated GPU on your CPU might also need its display drivers updated, if that is the one that is running.
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
CL2.0
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
from ilgpu.
MoFtZ
commented on June 2, 2024
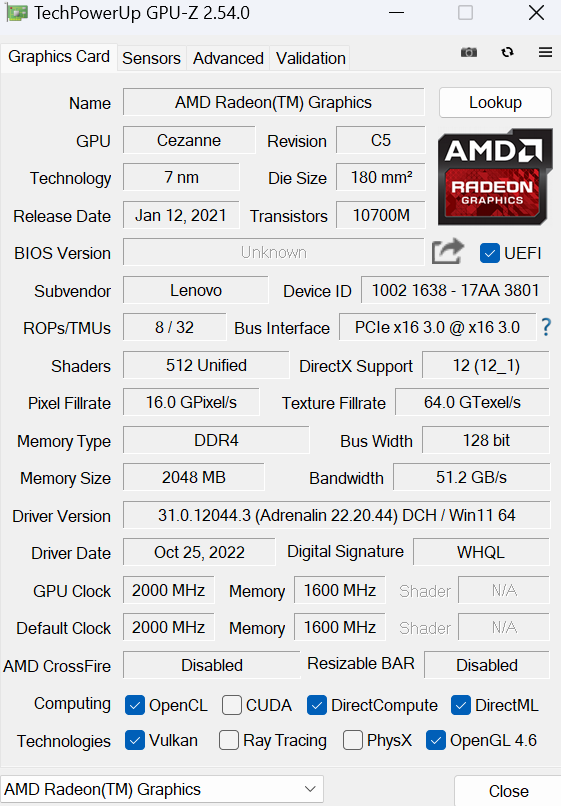
OpenCL 2.0 is supported.
Nothing seems out of the ordinary.
The latest AMD drivers are Adrenalin 23.8.1.
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
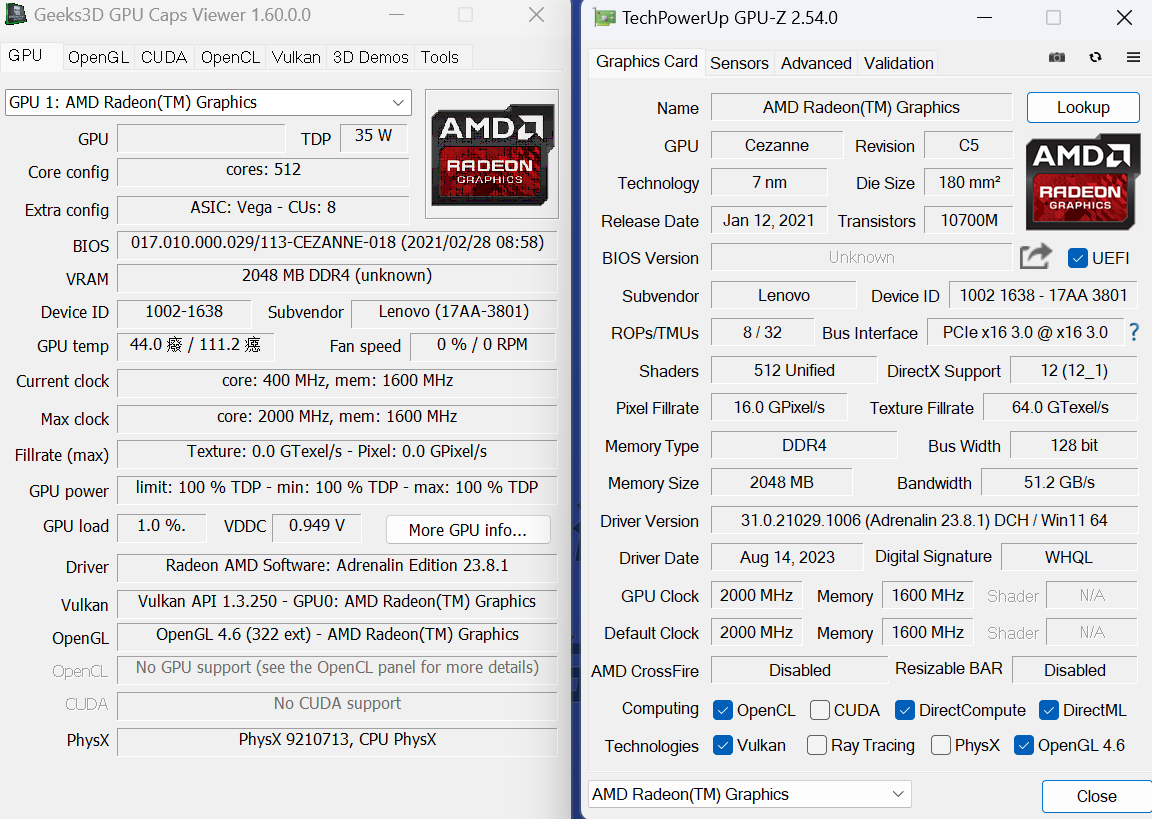
Adrenalin 23.8.1 ,still can't do it
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
somtimes,while(){} ,exception occurred ,System.AccessViolationException:“Attempted to read or write protected memory. This is often an indication that other memory is corrupt.”
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
Is it caused by a program judgment endless loop ???
from ilgpu.
MoFtZ
commented on June 2, 2024
Unfortunately, I am unable to reproduce the issue.
My guess is that this is a driver issue.
Perhaps someone else can help.
@m4rs-mt any ideas?
from ilgpu.
MoFtZ
commented on June 2, 2024
@sunxiaotianmg I forgot to ask, what version of ILGPU are you using?
from ilgpu.
MoFtZ
commented on June 2, 2024
@sunxiaotianmg If you are able, please join our Discord server. It might be easier for us to provide support there.
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
1.4 and 1.5 ,all not work
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
seems that this problem often occurs
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
static void MyKernel(
Index1D index,
ArrayView dataView,
int constant)
{
dataView[index] = index + constant;
var nRank = constant;
var contourNum = 9;
for (int k = 0; k <= 9; k++)
{
}
//大于二个for 循环编译不通过
for (int k = 9 + 1; k < 9; k++)
{
}
for (int k = 9; k < 9; k++)
{
}
}
static void MyKernel(
Index1D index,
ArrayView dataView,
int constant)
{
dataView[index] = index + constant;
var nRank = constant;
var contourNum = 9;
for (int k = 0; k <= 9; k++)
{
}
//大于二个for 循环编译不通过
for (int k = contourNum + 1; k < nRank - contourNum; k++)
{
}
for (int k = nRank - contourNum; k < nRank; k++)
{
}
}
The first one can pass, but the second one cannot execute normally
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
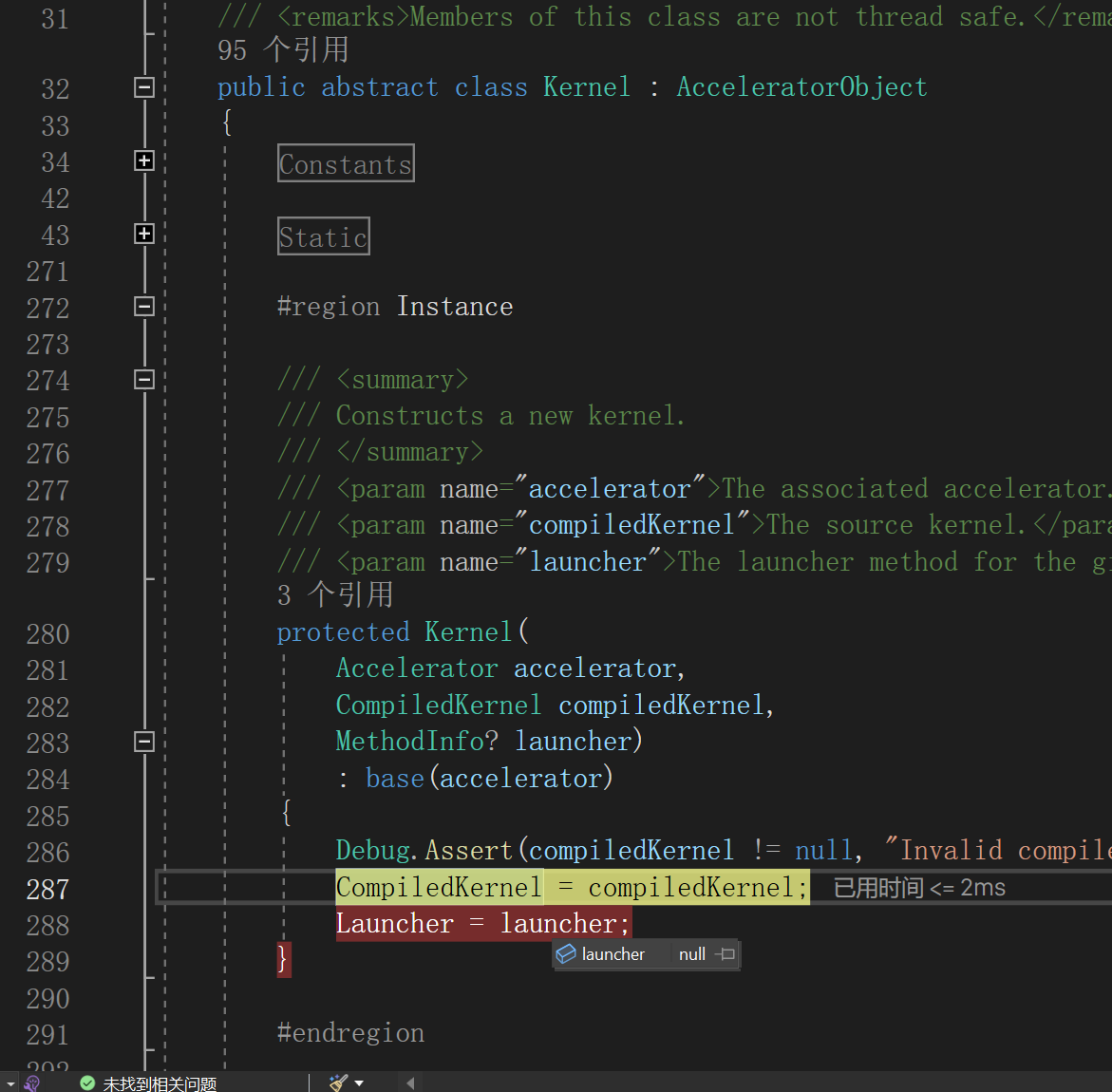
why launcher = null ???
from ilgpu.
sunxiaotianmg
commented on June 2, 2024
Does AMD integrated graphics card have this problem?
from ilgpu.
Related Issues (20)
- Cuda support not working on WSL2 HOT 6
- Triton like optimisations? HOT 3
- Support for OpenCL 1.2 HOT 2
- Question about hardware memory alignments HOT 3
- ArrayView.Cast should support unaligned byte offsets HOT 3
- RNG<XorShift64Star> corrupts data in ArrayView HOT 4
- CUDA tests are broken on .NET 7.0.400 HOT 1
- Debug.Assert is not take effect on opencl HOT 4
- System.AccessViolationException when adding useless if statement in kernel HOT 8
- Intel GPUs ,float64 type is not supported on this device HOT 5
- Are vector data types supported? HOT 3
- ILGPU throw error if variable in generic struct use Atomic operation HOT 2
- Website failing to deploy on new Releases HOT 1
- What is the difference between Stride2D.Infinite, Stride2D.DenseX, and Stride2D.General HOT 1
- Access violation exception caused by the OpenCL module, while using default context builder. HOT 2
- Is there a similar function to thrust::fill(stream, arrayStart, arrayEnd, -1) HOT 2
- Integration with current app HOT 2
- Can CuFFT or CuFFTW be used internally in the kernel? HOT 5
- Tensor Cores HOT 1
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from ilgpu.