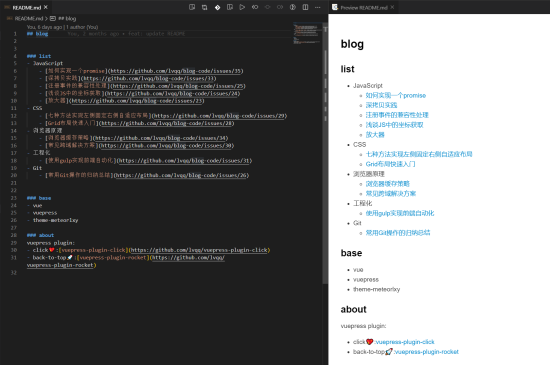
lvqq / blog Goto Github PK
View Code? Open in Web Editor NEWPersonal blog
Home Page: https://chlorine.site
Personal blog
Home Page: https://chlorine.site
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")








不论是开放的API接口,还是部署在不同服务器的项目,很多都绕不开跨域这个问题,那么跨域有哪些常见的解决方案呢?
jsonp主要依赖script标签的src属性可以实现跨域访问,在请求的url后拼上相应的回调函数字段,后端也需要对返回的数据外包一层函数名进行处理。
jsonp由两部分组成:回调函数和传入的数据,很重要的一点:jsonp 只支持
GET 方法,不支持POST
这里以豆瓣的API为例,实现一个跨域请求。url为:https://api.douban.com/v2/book/search?q=JavaScript高级程序设计&count=2
url中q表示查询图书时输入的信息,count表示查询结果的条目数。这里以查询JavaScript高级程序设计为例,结果为2条。
<script type="text/javascript">
//定义自己的回调函数
function handleResponse(data){
console.log(data);
}
</script>
<!-- 将自己的回调函数拼在url后的callback中 -->
<script type="text/javascript" src="https://api.douban.com/v2/book/search?q=JavaScript高级程序设计&count=2&callback=handleResponse"></script>通过这样的方法,将传入数据拼在url后,将自己的回调函数拼在url的callback中,再在回调函数中对获取到的数据进行处理,就实现了发起跨域请求。
这里设置一个button,点击后动态获取数据,代码如下:
<script type="text/javascript">
function handleResponse(data){
console.log(data.books[1]);
}
</script>
<script type="text/javascript">
window.onload = function() {
var btn = document.getElementById('btn');
btn.onclick = function() {
var script = document.createElement('script');
script.src = 'https://api.douban.com/v2/book/search?q=JavaScript高级程序设计&count=2&callback=handleResponse';
document.body.appendChild(script);
}
}
</script>点击后可以看到成功获取到了数据:
$.ajax({
type: "get",
url: "https://api.douban.com/v2/book/search?q=JavaScript高级程序设计&count=2",
dataType: "jsonp", // 将返回的数据类型设置为jsonp方式
jsonp: "callback", //请求php的参数名
jsonpCallback: "handleResponse", //要执行的回调函数
success: function(data) {
console.log(data);
}
});这里会先调用指定的 handleResponse ,然后再调用 success。其中 handleResponse 是随着参数传入的回调函数,success是该请求成功发送成功时一定会调用的回调函数,怎么使用就看你怎么写了。
使用$.getJSON()调用如下:
$.getJSON("https://api.douban.com/v2/book/search?q=JavaScript高级程序设计&count=2&callback=?", function(data){
console.log(data);
});将url作为第一个参数传入,其中令callback=?,将回调函数作为第二个参数传入,这样也可实现跨域,会得到和前面一样的请求结果。
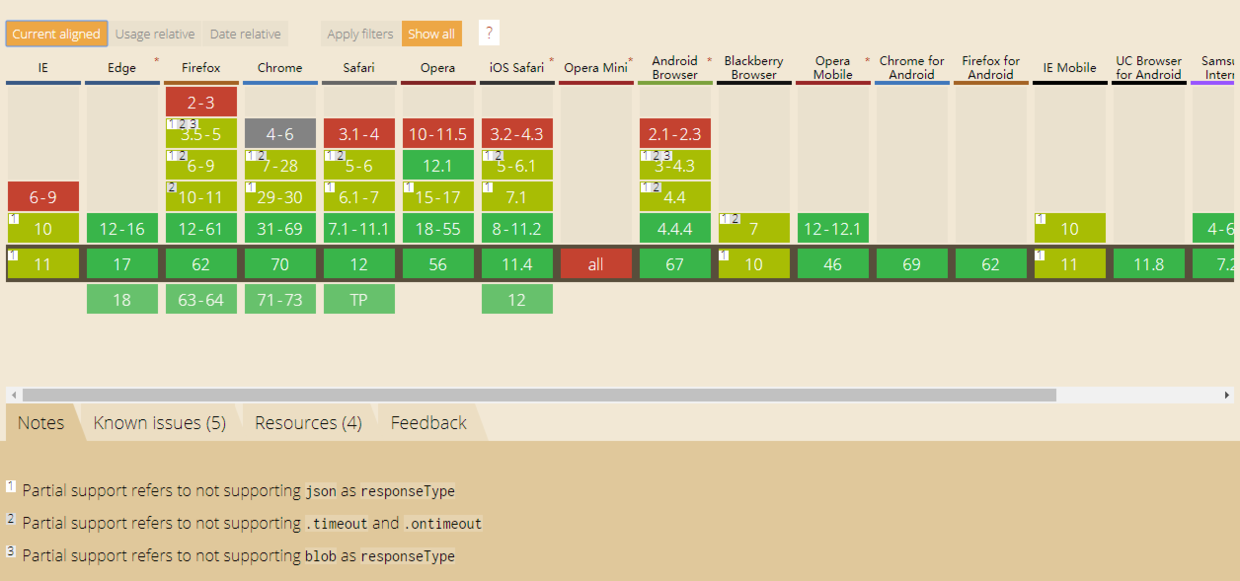
jsonp 的局限性CORS全称是“跨域资源共享”,允许向跨域服务器发送Ajax请求。对于开发者来说,和使用Ajax没有什么区别,关键在于服务器,只要服务器实现了CORS的支持,就能实现跨域访问。关于CORS的兼容性如下:
可以看到绝大多数浏览器都支持CORS,而IE则必须在IE10及以上。IE10以下的则使用的是XDomainRequest对象,这里就不展开了。
CORS请求可以分为简单请求和非简单请求两种,浏览器对这两种请求的处理方式有所不同。
若请求满足以下所有条件,则该请求视为“简单请求”:
使用以下方法之一:
GETPOSTHEADHTTP首部不得设置以下集合之外的字段:
AcceptAccept-LanguageContent-LanguageContent-TypeDPRDownlinkSave-DataViewport-WidthWidthContent-Type 的值仅限于下列三者之一:
text/plainmultipart/form-dataapplication/x-www-form-urlencoded对于简单请求,浏览器会直接发送CORS请求,在请求报文的头部信息中自动添加一个Origin字段,表示发起请求的源。例如:
Origin: http://foo.example
而服务端返回的响应首部中则有Access-Control-Allow-Origin字段:
Access-Control-Allow-Origin: http://foo.example
表示允许域名为http://foo.example的外域向自己发起跨域的CORS请求,如果想让任意域名都能发起请求,可以将它的值设置为*
如果是非简单请求,那么在发起CORS请求前,必须使用OPTIONS方法发起一个预检请求。
该预检请求中也会自动添加一个Origin字段表示请求源,还会携带以下两个字段:
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-PINGOTHER分别表示此次请求使用的方法和额外的自定义请求首部(若有多个则用逗号隔开)。
如果服务器通过了预检请求,那么返回的响应首部中会有如下几个字段:
Access-Control-Allow-Origin: http://foo.example
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400Access-Control-Allow-Origin与简单请求中的一致。Access-Control-Allow-Methods表示服务端允许客户端发起请求时使用的所有方法。Access-Control-Allow-Headers表示客户端发起请求时允许携带的请求首部。Access-Control-Max-Age则表示预检请求过期的时间,单位为秒,这里是86400秒,也就是24小时。关于CORS更为详细的介绍可以参考:
在存在iframe的页面中,要想发起跨域访问,可以采用降域或者postMessage的方式实现。
降域的前提是二者的主域名要一致,例如a.example.com和b.example.com。在当前页面和iframe源页面均需要设置document.domain属性才能实现降域,这样二者可以跨域访问:
document.domain = "example.com";
包含iframe的页面中还可以使用postMessage进行消息传递来进行跨域访问。
<!-- index.html 父页面 -->
<h1>this is index</h1>
<iframe src="./iframe.html" id="myiframe"></iframe><!-- iframe.html 子页面 -->
<h1>this is iframe</h1>这里有两个不同源的页面index.html和其中包含的iframe的源页面iframe.html。
//index.js
var myiframe = document.getElementById('myiframe');
myiframe.onload = function () {
myiframe.contentWindow.postMessage('data from index', '*');
}首先获取iframe元素,然后当它加载完成后向它发送一条消息,这里的contentWindow表示获取的iframe页面的window对象,postMessage方法挂载在window对象上。
postMessage方法接受的第一个参数是发送的数据,可以是任何原始类型的数据。第二个参数表示发送到的url,这里设置为*表示所有url都允许。还有更高级的第三个可选参数,这里就不展开了。
//iframe.js
window.onmessage = function (event) {
console.log(event.data);
}然后在iframe页面中监听message事件即可,event.data即为发送的数据。
//iframe.js
parent.postMessage('data from iframe', '*')在iframe的源页面中,直接使用parent关键字即可获得父页面的window对象,然后调用postMessage发送数据。
//index.js
window.onmessage = function (event) {
console.log(event.data);
}同样的,在父页面中监听message事件来捕获子页面的消息传递。
参考:
对于目前的个人开发者而言,使用云服务器是十分方便快捷的,在兴冲冲地写好了项目代码后,会有一种想要快速部署到服务器上的冲动,今天我们就来实践一下 0 到 1 的简单服务器部署。
首先你需要有一台云服务器,这里以我的阿里云服务器为例,系统是CentOS 7.3
想要在服务器上进行部署,首先得连接上服务器,可以通过阿里云官网控制的 浏览器远程连接 登录服务器,但是比较麻烦,每隔一段时间都需要重新登录。除此之外,还可以利用 ssh 通过账号密码或者密钥进行连接,如下:
# 通过账号密码进行连接,一般为 root,连接成功后需要输入密码
ssh root@yourIp
# 通过密钥进行连接,yourKey 为密钥的本地路径
ssh root@yourIp -i yourKey另外近期试用了下腾讯云,发现配置密钥之后居然默认不允许通过密码进行 ssh 登录了,不太方便,需要手动修改相关配置以支持 root 账号密码登录:
/etc/ssh/sshd_config 文件,将 PermitRootLogin 和 PasswordAuthentication 配置更改为 yessystemctl restart sshd现在的服务器部署,基本上离不开 nginx,配置简单易用,对于个人开发者十分友好。
yum install -y nginx安装成功后可以使用 -v 查看版本,我这里是 1.16.1
nginx -v可以使用 Linux 的系统工具 Systemd 来启动 nginx,也可以使用 nginx 自带的命令:
systemctl start nginx
# 或
nginx
# 设置开机自动启动
systemctl enable nginx当你想停止 nginx 时,可以使用 stop 命令:
systemctl stop nginx
# 或
nginx -s stop当你更改了 nginx 的配置时,这个时候往往需要重启 nginx 服务配置才能生效:
systemctl restart nginx
# 或
nginx -s reloadnginx 安装好了之后,默认路径一般是 /etc/nginx/,如果在该路径下没有找到,可以使用 nginx -t 命令查看安装路径:
nginx -t
# nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
# nginx: configuration file /etc/nginx/nginx.conf test is successful这里验证的 nginx.conf 就是 nginx 的主配置文件,默认内容如下:
# 部分配置已省略
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name _;
root /usr/share/nginx/html;
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}这里我们主要关注一下 server 的配置,以 http 协议的 server 为例,逐行解析一下:
对于前端项目,本质上打包之后是一堆静态文件,配置对应的 server_name 和 root 就可以了,这里以配置域名为 www.example.com,打包后 dist 下的文件存放服务器目录为 /home/admin/www 为例:
# 部分配置已省略
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name www.example.com;
root /home/admin/www;
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}对于服务端项目,会在本地监听一个端口来运行相关的服务,可以利用 nginx 配置反向代理,使被访问服务反向代理到对应的端口,这里以 3000 端口为例:
# 部分配置已省略
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name www.example.com;
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
location / {
proxy_pass http://127.0.0.1:3000;
}
}配置更改之后需要重启一下
nginx服务才能生效
上传文件的方式也比较多,这里主要介绍 scp 命令,以远程服务器用户为 [email protected] 为例:
# 将远程服务器的 /remote/index.html 文件,下载到本地 /local 目录下
scp [email protected]:/remote/index.html /local
# 将远程服务器的整个 remote 目录,下载到本地 /local 目录下
scp -r [email protected]:/remote/ /local
# 将本地 /local/index.html 文件,上传到远程服务器的 /remote 目录下
scp /local/index.html [email protected]:/remote
# 将本地的整个 /local 目录,上传到远程服务器的 /remote 目录下
scp -r /local [email protected]:/remote对于前端项目而言,若是想上传 dist 目录下的所有文件,但又不想上传 dist 目录,这个时候可以使用 通配符 来上传所有文件:
# 将本地的整个 /local 目录下的所有文件,上传到远程服务器的 /remote 目录下
scp -r /local/* [email protected]:/remote在上传前需要确保服务器的目录具有正确的读写权限,否则会出现 SCP Permission denied 错误,具体的文件权限可以通过 ls -l 查看:
ls -l
# -rw-r--r-- 1 root root 2376 Feb 17 20:37 404.html
# drwxr-xr-x 2 root root 4096 Feb 17 00:43 about
# drwxr-xr-x 4 root root 4096 Feb 17 00:43 assets
# drwxr-xr-x 2 root root 4096 Feb 17 00:43 atlas
# -rw-r--r-- 1 root root 51022 Feb 17 20:37 head.png
# -rw-r--r-- 1 root root 13927 Feb 17 20:37 index.html
# drwxr-xr-x 8 root root 4096 Feb 17 00:43 posts其中第二列表示文件权限,首字母为文件类型,d 表示目录文件,- 表示普通文件,后面的 rwx 表示 读/写/执行 权限,每三个一组,分别对应 拥有者/群组/其他组
如若没有权限,可以通过下面的命令来设置所有人可读写以及执行:
chmod 777 yourDir将你的站点配置为 https 需要下面几个步骤:
ssl_certificate 和 ssl_certificate_key 分别表示证书文件和私钥的存放路径,示例如下:
# 部分配置已省略
server {
listen 443 ssl http2 default_server;
listen [::]:443 ssl http2 default_server;
server_name www.example.com;
root /home/admin/www;
ssl_certificate "/etc/pki/nginx/www.example.com.pem";
ssl_certificate_key "/etc/pki/nginx/private/www.example.com.key";
ssl_session_cache shared:SSL:1m;
ssl_session_timeout 10m;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /404.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}当部署 https 站点时,常见的需求是将 http 站点自动跳转到 https,nginx 配置如下:
server {
listen 80;
server_name example.com www.example.com;
return 301 https://$server_name$request_uri;
}以上就是本篇的全部内容,如有错误,欢迎指正~
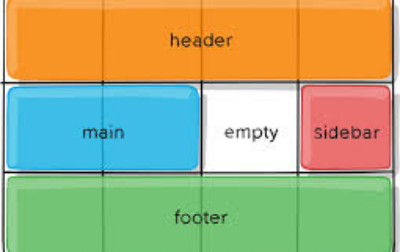
在编写JavaScript代码时,经常会需要获得鼠标或者某个盒子的相对坐标,这里我们就简要介绍一下几种获取方法的不同
鼠标坐标一般是用event事件获取,其中有以下几个方法:
其中以 pageX , pageY 方法使用得较多,其他的方法则不太常使用(*标明)。
一张图说明三者的区别:
如图☝
pageX 是指光标相对于该网页的水平位置(网页实际大小),以当前文档的左上角为基准点。screenX 是指光标相对于该屏幕的水平位置(电脑屏幕),当前屏幕的左上角为基准点。clientX 是指光标相对于浏览器的水平位置 (当前可见区域),当前窗口的左上角为基准点。所以我们如何获取鼠标坐标?根据自己的需求来调用这些方法就行了~
//...
var x = event.pageX;
var y = event.pageY;
//...说到兼容性,有两点要注意的是:
event (任意参数)ie 678 支持 window.event (内置,无参)
关于第一点,要想在ie和其他浏览器中都支持 event 事件,就要使用兼容性写法。代码如下:
document.onclick() = function (event) {
event = event || window.event;
}关于第二点,ie 6、7、8中不支持 pageX ,那么可以用以下方法代替 pageX 获取鼠标坐标
首先要获得 scrollLeft
document.documentElement.scrollLeft 获取document.body.scrollLeft 获取window.pageXOffset 其中DTD是文档类型声明,用 !DOCTYPE 在文件中进行声明,对于html文件一般位于文件首部,用于声明该文档是html文档,如下:
<!DOCTYPE html>
<html>
<!- ->
</html>因此scrollLeft 兼容性写法如下,然后将页面卷曲的距离和鼠标距离浏览器的距离相加即可:
var scrollLeft = document.documentElement.scrollLeft || window.pageXOffset || document.body.scrollLeft;
var pageX = scrollLeft + event.clientX;总的兼容性写法:
document.onclick = function(event) {
var event = event || window.event;
var scrollLeft = document.documentElement.scrollLeft || window.pageXOffset || document.body.scrollLeft;
var scrollTop = document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop;
var pageX = event.pageX || scrollLeft + event.clientX;
var pageY = event.pageY || screenTop + event.clientY;
}这里介绍两种常用的获取盒子坐标的方法:
offsetLeft style.left 看起来它们都是获取当前盒子的 left 值,但是却有很大不同:
offsetLeft 可以返回没有定位盒子的距离左侧的位置,而 style.left 不可以offsetTop 返回的是数字,而 style.top 返回的是字符串,除了数字外还带有单位:pxoffsetTop 只读,而 style.top 可读写(只读是获取值,可写是赋值)style.top 返回的是空字符串offsetLeft ,是从父盒子的 padding 开始算, border 不算,父亲没有定位则以 body 为准最近在业务开发过程中,遇到需要执行用户自定义 nodejs 脚本的场景,那么该如何安全地执行用户的神秘代码呢?
用户脚本具有不可预测性的特点。
因此我们默认认为用户提供的脚本内容是不可信任的。那么应该如何执行这样一段无法信任的脚本呢?
以 node 环境为例,在不考虑安全的情况下,我们简单执行一段脚本一般有两种方式:
// node v14.16.0
eval('process.exit()');
console.log('process has exit by eval')
new Function('process.exit()')()
console.log('process has exit by new Function')在这里 eval 和 new Function 函数都会在当前上下文执行,并能执行一些危险操作进而影响到当前运行环境。因此需要将用户脚本执行的环境与当前环境隔离开,使用 sandbox 沙盒去执行用户脚本,这样可以避免用户脚本对当前执行上下文造成影响。
这里我们仅从执行环境的角度来考虑,脚本的语法分析与过滤则不在本文的讨论范围内。
提到沙盒,我最先想到的就是 worker,那么在 worker 中去执行用户代码是否可行呢?看下面这个示例:
const { Worker, isMainThread, parentPort } = require('worker_threads');
if (isMainThread) {
console.log('in main thread');
const worker = new Worker(__filename);
// user script
const script = `
const fs = require('fs');
fs.unlink('./test.txt', (e) => {
if (e) throw e;
console.log('file was deleted')
})
`;
worker.postMessage(script);
} else {
console.log('in worker thread');
parentPort.on('message', (message) => {
eval(message);
})
}
// 执行结果:
// file was deleted在上面的例子中,可以看到虽然将用户代码的安全风险转嫁给了 worker 线程,但是在 node 端也无法阻止用户脚本调用 fs 模块进行文件相关的危险操作
浏览器中也可以使用 web worker,虽然在 worker 线程中无法直接获取到 cookie, localStorage, DOM 等数据,但由于 postMessage 能够接收任务来源的信息,这会成为 XSS 攻击的潜在风险点。因此在浏览器端使用时需要在服务端对信息进行相应的输入过滤和清洗
child_process 是 Nodejs 中创建的子进程,能够直接执行 shell 命令,使用 child_process 遇到的问题与 web worker 类似,就不展开了
vm 是 Node 中的一个模块,可以在 v8 的虚拟机中运行你的代码,是一个沙箱隔离的环境,并且默认屏蔽了process, console, fs 等全局对象,有一定的安全性保障:
const vm = require('vm');
// ReferenceError: process is not defined
vm.runInNewContext('process.exit()');
vm 中还可以选择脚本的执行上下文环境:
vm.runInThisContext // 在当前上下文执行
vm.runInContext // 在指定的上下文中运行脚本,上下文是 vm.createContext 中返回的结果
vm.runInNewContext // 创建一个新的上下文执行,会默认执行 vm.createContext 方法
vm.runInNewContext 和 vm.createContext 中还支持为上下文传入一些全局对象供脚本使用
const vm = require('vm');
// 将当前上下文的 process 传入新的上下文中,此时进程退出成功
vm.runInNewContext('process.exit()', {
process,
});表面上看比较完美,但其实 vm 模块存在一些已知的安全问题,正如 Node 的官方文档中写道:
The vm module is not a security mechanism. Do not use it to run untrusted code.
以下面的代码为例,通过访问上层的构造函数,则可以逃逸 vm 构造的沙盒环境,“呼吸到沙盒外的空气”:
const vm = require('vm');
// sandbox 的 constructor 是外层的 Object 类
// Object 类的 constructor 是外层的 Function 类
// func = this.constructor.constructor
// 于是, 利用外层的 Function 构造一个函数就可以得到外层的全局环境的上下文
// process = (func('return this;'))().process;
vm.runInNewContext('this.constructor.constructor("return process")().exit()');
console.log('Never gets executed.');在社区中有许多解决方案用于隔离运行用户脚本,如 sandbox、 vm2、 jailed 等。相比较而言 vm2 在安全方面做了更多的工作,相对可靠些。vm2 主要利用 Proxy 进行了上下文同步,防止代码逃逸,实现了对于全局对象、内置模块的访问限制,并重写了 require 方法实现对于模块的访问管理。
上面逃逸的例子在 vm2 中则被拦截了:
const { VM } = require('vm2');
new VM().run('this.constructor.constructor("return process")().exit()');
// Throws ReferenceError: process is not defined在 vm2中还新增了 NodeVM 类来实现 node 中的模块化调用,因此你可以方便的在脚本中去 exports 一些内容:
const { NodeVM } = require('vm2');
const script = `
module.exports = async () => {
return 1
}
`;
const fn = new NodeVM().run(script);
fn();
// Result: 1
// fn 就是 module.exports 返回的函数但 vm2 也没有解决 vm 中已知的一些问题:
NodeVM 模块,不支持 timeout 配置,无法处理例如 while(true){} 等死循环从而导致进程卡住,无法退出VM 模块,timeout 超时只能针对同步代码生效,无法处理异步超时处理同步代码不支持 timeout 的情况,可以利用 vm2 的 VM 模块或者原生的 vm 模块来手动实现,支持 timeout 参数处理同步场景下的超时配置,伪代码如下:
// vm2
function fnSyncTimeout(fn, timeout) {
// ...
return new VM({
timeout,
sandbox: { fn }
}).run('fn()')
}处理线程不阻塞时,类似接口调用场景下的异步超时的处理,我们可以通过 Promise.race 来实现:
function fnAsyncTimeout(fn, timeout) {
let timer;
return Promise.race([fn(), new Promise((res, rej) => {
timer = setTimeout(() => {
rej('script timeout error')
}, timeout)
})]).finally(() => {
clearTimeout(timer);
});;
}上面的方法虽然可以解决单个场景,但是介于 nodejs 单线程的特性,对于无法返回的异步脚本的处理无能为力。例如异步脚本中包含死循环,会使当前线程受到阻塞,即使有异步回调也无法继续执行。而且 vm 模块在创建后无法手动关闭,自带的超时配置仅支持同步脚本。
基于以上问题,我想到结合 web worker 来优化处理,主要思路是将用户脚本放在 worker 线程中执行,避免阻塞主线程,并且通过在主线程中配置定时器,超过超时时间则手动退出 worker 线程。主要实现如下:
const { isMainThread, Worker, parentPort } = require("worker_threads");
// 超时时间
const timeout = 60000;
if (isMainThread) {
const w = new Worker(__filename);
let checkEndTimer;
w.on("online", () => {
checkEndTimer = setTimeout(() => {
w.terminate();
}, timeout);
console.log('script start')
});
w.on("exit", () => {
clearTimeout(checkEndTimer);
console.log('script end');
});
w.on('message', (msg) => {
// handle script result
});
} else {
const { NodeVM, VMScript } = require("vm2");
const vm = new NodeVM();
// 用户脚本
const code = `
module.exports = async () => {
await new Promise(res => setTimeout(res, 2000))
// 死循环
while(true) {}
return 1;
}
`;
try {
new VMScript(code).compile();
} catch (err) {
console.error('Failed to compile script.', err);
}
const fn = vm.run(code);
(async () => {
const data = await fn();
parentPort.postMessage(data);
})()
}目前采用 worker 线程 + vm2 作为执行用户脚本的方案并加以优化,相较于其他方式来说似乎提供了一个更坚固的沙箱,但也不排除有未发现的新的安全隐患。总之,代码安全无小事,考虑再多也不为过~

在日常的开发过程中离不开git 的接触和使用,这里我总结归纳一下比较常见的以及实际开发过程中常用的 git 命令,持续更新中
因为远程主机默认的主机名是 origin ,这里的例子均以 origin 为例
# 获取线上该分支最新的代码
$ git pull origin <分支名>
# 将本地该分支的代码上传到远程仓库
$ git push origin <分支名>
# 强制上传代码到远程仓库
$ git push origin <分支名> -f
# 建立当期分支与远程分支的联系并上传到远程仓库,--set-upstream 可以使用缩写 -u
$ git push --set-upstream origin <分支名>
# 删除远程分支,等同于 git push origin --delete <分支名>,也可以使用缩写 -d
$ git push origin :<分支名>
# 使用目标分支覆盖远程分支,一般适用于分支同步,目标分支既可以是本地分支,也可以是远程分支(加 origin/)
$ git push origin <分支名>:<分支名>
# 列出所有远程主机
$ git remote
# 查看主机的详细信息
$ git remote show <主机名>
# 将远程仓库该分支的最新代码取回本地
$ git fetch origin <分支名>
# 克隆地址所对应的远程仓库的代码到本地
$ git clone <地址># 将更改保存到暂存区
$ git add .
# 提交commit
$ git commit -m "<备注>"
# 添加并提交,相当于 git add . + git commit -m ""
$ git commit -a -m "<备注>"
# 合并本次修改到上次commit(不会产生新的commit记录)
$ git commit --amend
# 将已被git暂存的文件取消暂存,使 .gitignore 生效
$ git rm -r --cached . && git add .# 切换分支
$ git checkout <分支名>
# 创建并切换至该分支
$ git checkout -b <分支名>
# 创建一个分支关联到远程分支
$ git branch -t <分支名> <远程分支名>
# 修改当前分支的分支名
$ git branch -m "<分支名>"
# 列出各个分支最后提交的信息
$ git branch -v
# 列出本地分支和远程分支的映射关系
$ git branch -vv
# 列出所有本地分支
$ git branch
# 列出所有远程分支
$ git branch -r
# 列出所有分支
$ git branch -a
# 设置当前分支追踪目标分支
$ git brance --set-upstream <分支名># 查看commit记录
$ git log
# 查看所有历史操作记录,包括commit和reset的操作和已经被删除的commit记录
$ git reflog / git log -g
# 将commit压缩到一行展示
$ git log --oneline
# 显示每次提交文件的增删数
$ git log --stat
# 显示每次提交具体修改的内容
$ git log -p
# 查看当前仓库状态
$ git status# 撤销指定文件在工作区和暂存区的修改
$ git checkout <文件路径>
# 删除所有工作区和暂存区的修改,回到最近一次commit的状态
$ git reset --hard
# 将指针回退三个commit,并改变暂存区
$ git reset HEAD~3
# 将指针回退三个commit,但不改变暂存区,即删除commit记录,但保留工作区的本次修改
$ git reset --soft HEAD~3
# 将指针回退三个commit,改变工作区,即删除commit记录并回退工作区的修改。
$ git reset --hard HEAD~3# 暂时保存没有提交的工作
$ git stash
# 列出所有暂时保存的工作
$ git stash list
# 恢复最近一次stash的文件并删除list中的记录
$ git stash pop
# 恢复最近一次stash的文件但不删除list中的记录
$ git stash apply
# 恢复指定的暂时保存的工作
$ git stash apply stash@{1}
# 丢弃最近一次stash的文件
$ git stash drop
# 删除所有的stash
$ git stash clear# 打印所有版本号
$ git tag
# 标记一个本地 tag
$ git tag <版本号>
# 删除一个本地 tag
$ git tag -d <版本号>
# 切换到一个 tag
$ git checkout <版本号>
# 推送单个 tag 到远端
$ git push origin <版本号>
# 删除远程仓库的 tag
$ git push origin --delete <版本号>
# 推送本地所有 tag 到远端
$ git push origin --tags# 将指定分支与当前分支合并
$ git merge <分支名> / git rebase <分支名>有关git merge和git rebase的区别,可以参考merge和rebase的选择
以下命令操作的均为当前仓库git配置,如需操作全局git配置,增加 --global 参数即可
# 配置快捷键,输入git s就代表git status
$ git config alias.s status
# 获得git提交的用户名
$ git config user.name
# 获得git提交的邮箱
$ git config user.email
# 更改git提交的用户名
$ git config user.name <用户名>
# 更改git提交的邮箱
$ git config user.email <邮箱>pnpm 作为当前比较流行的包管理器之一,主要特点是速度快、节省磁盘空间,本文将介绍 pnpm 的底层实现,帮助你理解 pnpm 的原理
pnpm 的含义是 performant npm,意味着高性能 npm,从官网中提供的 benchmarks 也可以看出在 intall、update 等场景时对于 npm、yarn、yarn_pnp 有不错的性能优势:
在 npm@2 的早期版本中,对应 Node.js 4.x 及以前的版本,node_modules 在安装时是嵌套结构
一个简单的例子,demo-foo 和 demo-baz 中均依赖 demo-bar,在同时安装 demo-foo 和 demo-baz 时会生成如下的 node_modules 结构:
node_modules
└─ demo-foo
├─ index.js
├─ package.json
└─ node_modules
└─ demo-bar
├─ index.js
└─ package.json
└─ demo-baz
├─ index.js
├─ package.json
└─ node_modules
└─ demo-bar
├─ index.js
└─ package.json
这个时候的目录结构虽然比较清晰,但是每个依赖包都会有自己的 node_modules,相同的依赖并没有复用,例如上面的相同依赖 demo-bar 就被安装了两次
另外一个问题是 windows 的最长路径限制,在复杂项目场景依赖层级较深时,依赖的路径往往会超出长度限制
为了解决上述问题,yarn 提出了扁平结构的设计,将所有的依赖在 node_modules 中平铺,后来的 npm v3版本的实现也与之类似,因此使用 yarn 或者 npm@3+ 安装上述的例子,将会得到如下扁平式的目录结构:
node_modules
└─ demo-bar
├─ index.js
└─ package.json
└─ demo-baz
├─ index.js
└─ package.json
└─ demo-foo
├─ index.js
└─ package.json
另外这种方式对于相同依赖的不同版本,则只会将其中一个进行提升,剩余的版本则还是嵌套在对应的包中,例如我们上面的 demo-foo 中对于 demo-bar 的依赖升级到 v1.0.1 版本,则会得到下面的结构,具体哪个版本会提升到最顶层则取决于安装时的顺序(示例):
node_modules
└─ demo-bar
├─ index.js
└─ package.json
└─ demo-baz
├─ index.js
├─ package.json
└─ node_modules
└─ demo-bar
├─ index.js
└─ package.json
└─ demo-foo
├─ index.js
├─ package.json
└─ node_modules
└─ demo-bar
├─ index.js
└─ package.json
扁平化的方案并不完美,反而引入了一些新的问题:
幽灵依赖(Phantom dependencies)指的是没有显示声明在 package.json 中的依赖,却可以直接引用到对应的包,这个问题是由扁平化的结构产生的,会将依赖的依赖也至于 node_modules 的顶层,也就可以在项目中直接引用到。当某一天这个子依赖不再是引用包的依赖时,项目中的引用则会出现问题。
例如在包含 demo-foo 和 demo-baz 的项目中可以得到如下依赖,此时 demo-bar 作为依赖的依赖也出现在了 node_modules 中:
node_modules
└─ demo-bar
├─ index.js
└─ package.json
└─ demo-baz
├─ index.js
└─ package.json
└─ demo-foo
├─ index.js
└─ package.json
NPM 分身(NPM doppelgangers)则指的是对于相同依赖的不同版本,由于 hoist 的机制,只会提升一个,其他版本则可能会被重复安装,还是上面的例子,当依赖的 demo-bar 升级到 v1.0.1 时,作为 demo-foo 和 demo-baz 依赖的 v1.0.0 版本则以嵌套的形式被重复安装:
node_modules
└─ demo-bar // v1.0.1
├─ index.js
└─ package.json
└─ demo-baz
├─ index.js
├─ package.json
└─ node_modules
└─ demo-bar // v1.0.0
├─ index.js
└─ package.json
└─ demo-foo
├─ index.js
├─ package.json
└─ node_modules
└─ demo-bar // v1.0.0
├─ index.js
└─ package.json
pnpm 首先将依赖安装到全局 store,然后通过 symbolic link 和 hard link 来组织目录结构,将全局的依赖链接到项目中,将项目的直接依赖链接到 node_modules 的顶层,所有的依赖则平铺于 node_modules/.pnpm 目录下,实现了所有项目的依赖共享 store 的全局依赖,解决了幽灵依赖和 NPM 分身的问题
链接是操作系统中文件共享的方式,其中 symbolic link 是符号链接,也称软链接,hard link 是硬链接,从在使用的角度看,二者没有什么区别,都支持读写,如果是可执行文件也可以直接执行,主要区别在于底层原理不太一样:
inode(索引节点),源文件与硬链接指向同一个索引节点Windows 的快捷方式inode 值不一样,文件类型也不同,因此符号链接可以跨分区访问# symbolic ink
ln -s myfile mysymlink
# hard link
ln myfile myhardlink在 pnpm 中,会将依赖安装到当前分区的 <home dir>/.pnpm-store 位置中,可以通过以下命令获得当前的 store 位置:
pnpm store path然后利用 hard link 将所需的包从 node_modules/.pnpm 硬链接到 store 中,最后通过 symbolic link 将 node_modules 中的顶层依赖以及依赖的依赖符号链接到 node_modules/.pnpm 中,一个依赖 [email protected] 和 [email protected] 的例子,node_modules 结构如下:
node_modules
└─ .pnpm
└─ [email protected]
└─ node_modules
└─ demo-bar -> <store>/demo-bar
└─ [email protected]
└─ node_modules
└─ demo-bar -> <store>/demo-bar
└─ [email protected]
└─ node_modules
├─ demo-bar -> ../../[email protected]/node_modules/demo-bar
└─ demo-baz -> <store>/demo-baz
└─ [email protected]
└─ node_modules
├─ demo-bar -> ../../[email protected]/node_modules/demo-bar
└─ demo-foo -> <store>/demo-foo
└─ demo-baz -> ./pnpm/[email protected]/node_modules/demo-baz
└─ demo-foo -> ./pnpm/[email protected]/node_modules/demo-foo
这里引用了官网的截图帮助你更好地理解 symbolic ink 与 hard link 在项目结构中是如何组织的:
pnpm 对于链接的实际应用,以下是相关源码:
function createImportPackage (packageImportMethod?: 'auto' | 'hardlink' | 'copy' | 'clone' | 'clone-or-copy') {
// this works in the following way:
// - hardlink: hardlink the packages, no fallback
// - clone: clone the packages, no fallback
// - auto: try to clone or hardlink the packages, if it fails, fallback to copy
// - copy: copy the packages, do not try to link them first
switch (packageImportMethod ?? 'auto') {
case 'clone':
packageImportMethodLogger.debug({ method: 'clone' })
return clonePkg
case 'hardlink':
packageImportMethodLogger.debug({ method: 'hardlink' })
return hardlinkPkg.bind(null, linkOrCopy)
case 'auto': {
return createAutoImporter()
}
case 'clone-or-copy':
return createCloneOrCopyImporter()
case 'copy':
packageImportMethodLogger.debug({ method: 'copy' })
return copyPkg
default:
throw new Error(`Unknown package import method ${packageImportMethod as string}`)
}
}pnpm 目前可以脱离 Node.js 的 runtime 去安装使用,还可以通过 pnpm env 来对 Node.js 版本进行管理,类似 nvm,与 npm/yarn 完整的功能比较详见:feature-comparison
symbolic link 在一些场景下有兼容性问题,目前 Eletron 以及 labmda 部署的应用上无法使用 pnpm,详见:discussion可以通过在 .npmrc 中 node-linker=hoisted 可以创建一个没有符号链接的扁平的 node_modules,此时 pnpm 创建的目录结构将与 npm/yarn 类似
store,因此当需要修改 node_modules 内的内容时,会直接影响全局 store 中对应的内容,对其他项目也会造成影响关于这个问题,其实最推荐的方式是 clone(copy-on-write),使用写入时复制,默认多个引用指向同一个文件,只有当用户需要修改的时候才进行复制,这样就不会影响其他引用对于源文件内容的读取
但是并不是所有的操作系统都支持,pnpm 默认会尝试使用 clone,如果不支持,则会退回至使用 hard link,你也可以通过在 npmrc 中指定 package-import-method 来手动设置包的引用方式
bun: https://github.com/oven-sh/bun
Zig 写的一个 JS runtime,bun 也提供了包管理工具,但是 bun 会有一些兼容性问题Volt:https://github.com/dimensionhq/volt
Rust 写的 Node.js 包管理器,速度极快,目前仍在 beta 阶段pnpm 很快,但是并不是所有的 pnpm 命令都很快,例如 pnpm run 比较慢,未来可能会使用 Rust 来写一些子命令的 cli wrapper,参见这个 discussion
前言:js如何实现一个深拷贝
这是一个老生常谈的问题,也是在求职过程中的高频面试题,考察的知识点十分丰富,本文将对浅拷贝和深拷贝的区别、实现等做一个由浅入深的梳理
在js中,变量类型分为基本类型和引用类型。对变量直接进行赋值拷贝:
直接拷贝引用类型变量,只是复制了变量的指针地址,二者指向的是同一个引用类型数据,对其中一个执行操作都会引起另一个的改变。
关于浅拷贝和深拷贝:
因此,浅拷贝与深拷贝根本上的区别是 是否共享内存空间 。简单来讲,深拷贝就是对原数据递归进行浅拷贝。
三者的简单比较如下:
| 是否指向原数据 | 子数据为基本类型 | 子数据包含引用类型 | |
|---|---|---|---|
| 赋值 | 是 | 改变时原数据改变 | 改变时原数据改变 |
| 浅拷贝 | 否 | 改变时原数据 不改变 | 改变时原数据改变 |
| 深拷贝 | 否 | 改变时原数据 不改变 | 改变时原数据 不改变 |
数组和对象中常见的浅拷贝方法有以下几种:
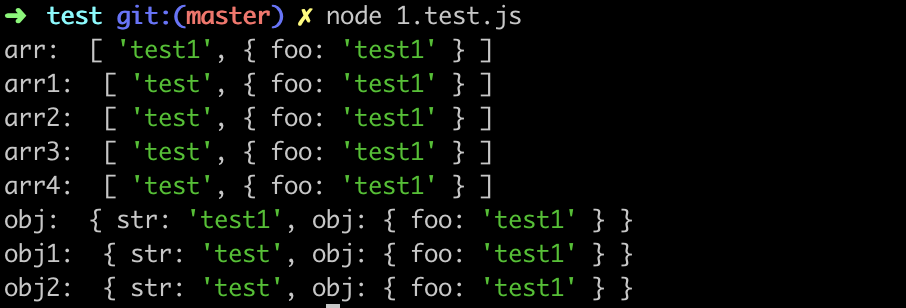
使用下面的 用例 1.test.js 进行测试:
const arr = ['test', { foo: 'test' }]
const obj = {
str: 'test',
obj: {
foo: 'test'
}
}
const arr1 = arr.slice()
const arr2 = arr.concat()
const arr3 = Array.from(arr)
const arr4 = [...arr]
const obj1 = Object.assign({}, obj)
const obj2 = {...obj}
//修改arr
arr[0] = 'test1'
arr[1].foo = 'test1'
// 修改obj
obj.str = 'test1'
obj.obj.foo = 'test1'结果如下:
可以看到经过浅拷贝以后,我们去修改原对象或数组中的基本类型数据,拷贝后的相应数据未发生改变;而修改原对象或数组中的引用类型数据,拷贝后的数据会发生相应变化,它们共享同一内存空间
这里我们列举常见的深拷贝方法并尝试自己手动实现,最后对它们做一个总结、比较
使用 JSON.parse(JSON.stringify(data)) 来实现深拷贝,这种方法基本可以涵盖90%的使用场景,但它也有其不足之处,涉及到下面这几种情况下时则需要考虑使用其他方法来实现深拷贝:
JSON.parse 只能序列化能够被处理为JSON格式的数据,因此无法处理以下数据
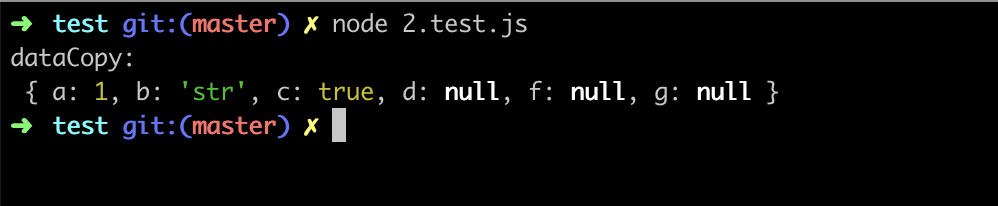
undefined 、 NaN 、 Infinity 等JSON.parse 只能序列化对象可枚举的自身属性,因此会丢弃构造函数的 constructor使用下面的 用例 2.test.js 来对基本类型进行验证:
const data = {
a: 1,
b: 'str',
c: true,
d: null,
e: undefined,
f: NaN,
g: Infinity,
}
const dataCopy = JSON.parse(JSON.stringify(data))可以看到 NaN 、 Infinity 在序列化的过程中被转化为了 null ,而 undefined 则丢失了:
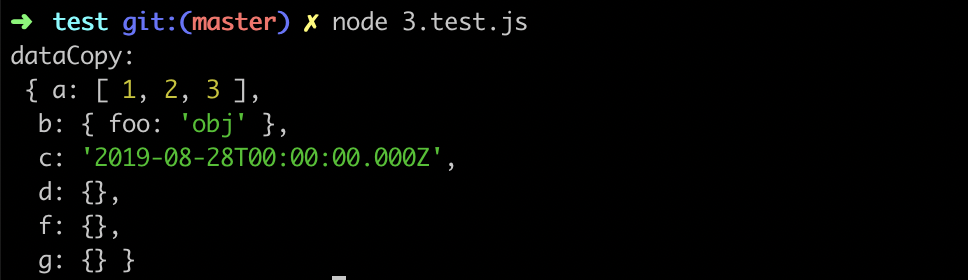
再使用 用例 3.test.js 对引用类型进行测试:
const data = {
a: [1, 2, 3],
b: {foo: 'obj'},
c: new Date('2019-08-28'),
d: /^abc$/g,
e: function() {},
f: new Set([1, 2, 3]),
g: new Map([['foo', 'map']]),
}
const dataCopy = JSON.parse(JSON.stringify(data))对于引用类型数据,在序列化与反序列化过程中,只有数组和对象被正常拷贝,其中时间对象被转化为了字符串,函数会丢失,其他的都被转化为了空对象:
利用 用例 4.test.js 对构造函数进行验证:
function Person(name) {
// 构造函数实例属性name
this.name = name
// 构造函数实例方法getName
this.getName = function () {
return this.name
}
}
// 构造函数原型属性age
Person.prototype.age = 18
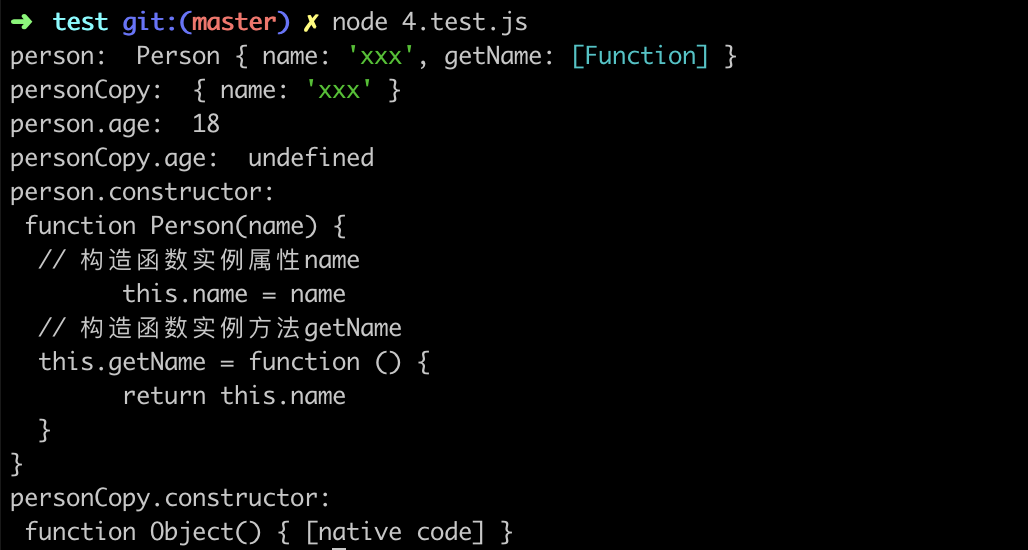
const person = new Person('xxx')
const personCopy = JSON.parse(JSON.stringify(person))在拷贝过程中只会序列化对象可枚举的自身属性,因此无法拷贝 Person 上的原型属性 age ;由于序列化的过程中构造函数会丢失,所以 personCopy 的 constructor 会指向顶层的原生构造函数 Object 而不是自定义构造函数Person
我们先来实现一个简单版的深拷贝,思路是,判断data类型,若不是引用类型,直接返回;如果是引用类型,然后判断data是数组还是对象,并对data进行递归遍历,如下:
function cloneDeep(data) {
if(!data || typeof data !== 'object') return data
const retVal = Array.isArray(data) ? [] : {}
for(let key in data) {
retVal[key] = cloneDeep(data[key])
}
return retVal
}执行 用例 clone1.test.js :
const data = {
str: 'test',
obj: {
foo: 'test'
},
arr: ['test', {foo: 'test'}]
}
const dataCopy = cloneDeep(data)可以看到对于对象和数组能够实现正确的拷贝
首先是只考虑了对象和数组这两种类型,其他引用类型数据依然与原数据共享同一内存空间,有待完善;其次,对于自定义的构造函数而言,在拷贝的过程中会丢失实例对象的 constructor ,因此其构造函数会变为默认的 Object
在上一步我们实现的简单深拷贝,只考虑了对象和数组这两种引用类型数据,接下来将对其他常用数据结构进行相应的处理
我们首先定义一个方法来正确获取数据的类型,这里利用了 Object 原型对象上的 toString 方法,它返回的值为 [object type] ,我们截取其中的type即可。然后定义了数据类型集合的常量,如下:
const getType = (data) => {
return Object.prototype.toString.call(data).slice(8, -1)
}
const TYPE = {
Object: 'Object',
Array: 'Array',
Date: 'Date',
RegExp: 'RegExp',
Set: 'Set',
Map: 'Map',
}接着我们完善对于其他类型的处理,根据不同的 data 类型,对 data 进行不同的初始化操作,然后进行相应的递归遍历,如下:
const cloneDeep = (data) => {
if (!data || typeof data !== 'object') return data
let cloneData = data
const Constructor = data.constructor;
const dataType = getType(data)
// data 初始化
if (dataType === TYPE.Array) {
cloneData = []
} else if (dataType === TYPE.Object) {
// 获取原对象的原型
cloneData = Object.create(Object.getPrototypeOf(data))
} else if (dataType === TYPE.Date) {
cloneData = new Constructor(data.getTime())
} else if (dataType === TYPE.RegExp) {
const reFlags = /\w*$/
// 特殊处理regexp,拷贝过程中lastIndex属性会丢失
cloneData = new Constructor(data.source, reFlags.exec(data))
cloneData.lastIndex = data.lastIndex
} else if (dataType === TYPE.Set || dataType === TYPE.Map) {
cloneData = new Constructor()
}
// 遍历 data
if (dataType === TYPE.Set) {
for (let value of data) {
cloneData.add(cloneDeep(value))
}
} else if (dataType === TYPE.Map) {
for (let [mapKey, mapValue] of data) {
// Map的键、值都可以是引用类型,因此都需要拷贝
cloneData.set(cloneDeep(mapKey), cloneDeep(mapValue))
}
} else {
for (let key in data) {
// 不考虑继承的属性
if (data.hasOwnProperty(key)) {
cloneData[key] = cloneDeep(data[key])
}
}
}
return cloneData
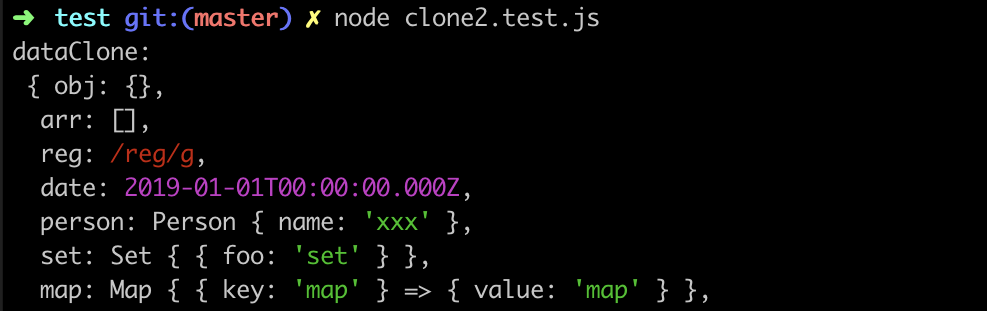
}上面的代码完整版可以参考 clone2.js ,接下来使用 用例 clone2.test.js 进行验证:
const data = {
obj: {},
arr: [],
reg: /reg/g,
date: new Date('2019'),
person: new Person('lixx'),
set: new Set([{test: 'set'}]),
map: new Map([[{key: 'map'}, {value: 'map'}]])
}
function Person(name) {
this.name = name
}
const dataClone = cloneDeep(data)可以看到对于不同类型的引用数据都能够实现正确拷贝,结果如下:
函数的拷贝我这里没有实现,两个对象中的函数使用同一个内存空间并没有什么问题。实际上,查看了 lodash/cloneDeep 的相关实现后,对于函数它是直接返回的:
到这一步,我们的深拷贝方法已经初具雏形,实际上需要特殊处理的数据类型远不止这些,还有 Error 、 Buffer 、 Element 等,有兴趣的小伙伴可以继续探索实现一下~
目前为止深拷贝能够处理绝大部分常用的数据结构,但是当数据中出现了循环引用时它就束手无策了
const a = {}
a.a = a
cloneDeep(a)可以看到,对于循环引用,在进行递归调用的时候会变成死循环而导致栈溢出:
那么如何破解呢?
抛开循环引用不谈,我们先来看看基本的 引用 问题,前文所实现的深拷贝方法以及 JSON 序列化拷贝都会解除原引用类型对于其他数据的引用,来看下面这个例子:
const temp = {}
const data = {
a: temp,
b: temp,
}
const dataJson = JSON.parse(JSON.stringify(data))
const dataClone = cloneDeep(data)验证一下引用关系:
如果解除这种引用关系是你想要的,那完全ok。如果你想保持数据之间的引用关系,那么该如何去实现呢?
一种做法是可以用一个数据结构将已经拷贝过的内容存储起来,然后在每次拷贝之前进行查询,如果发现已经拷贝过了,直接返回存储的拷贝值即可保持原有的引用关系。
因为能够被正确拷贝的数据均为引用类型,所以我们需要一个 key-value 且 key 可以是引用类型的数据结构,自然想到可以利用 Map/WeakMap 来实现。
这里我们利用一个 WeakMap 的数据结构来保存已经拷贝过的结构, WeakMap 与 Map 最大的不同,就是它的键是弱引用的,它对于值的引用不计入垃圾回收机制,也就是说,当其他引用都解除时,垃圾回收机制会释放该对象的内存;假如使用强引用的 Map ,除非手动解除引用,否则这部分内存不会得到释放,容易造成内存泄漏。
具体的实现如下:
const cloneDeep = (data, hash = new WeakMap()) => {
if (!data || typeof data !== 'object') return data
// 查询是否已拷贝
if(hash.has(data)) return hash.get(data)
let cloneData = data
const Constructor = data.constructor;
const dataType = getType(data)
// data 初始化
if (dataType === TYPE.Array) {
cloneData = []
} else if (dataType === TYPE.Object) {
// 获取原对象的原型
cloneData = Object.create(Object.getPrototypeOf(data))
} else if (dataType === TYPE.Date) {
cloneData = new Constructor(data.getTime())
} else if (dataType === TYPE.RegExp) {
const reFlags = /\w*$/
// 特殊处理regexp,拷贝过程中lastIndex属性会丢失
cloneData = new Constructor(data.source, reFlags.exec(data))
cloneData.lastIndex = data.lastIndex
} else if (dataType === TYPE.Set || dataType === TYPE.Map) {
cloneData = new Constructor()
}
// 写入 hash
hash.set(data, cloneData)
// 遍历 data
if (dataType === TYPE.Set) {
for (let value of data) {
cloneData.add(cloneDeep(value, hash))
}
} else if (dataType === TYPE.Map) {
for (let [mapKey, mapValue] of data) {
// Map的键、值都可以是引用类型,因此都需要拷贝
cloneData.set(cloneDeep(mapKey, hash), cloneDeep(mapValue, hash))
}
} else {
for (let key in data) {
// 不考虑继承的属性
if (data.hasOwnProperty(key)) {
cloneData[key] = cloneDeep(data[key], hash)
}
}
}
return cloneData
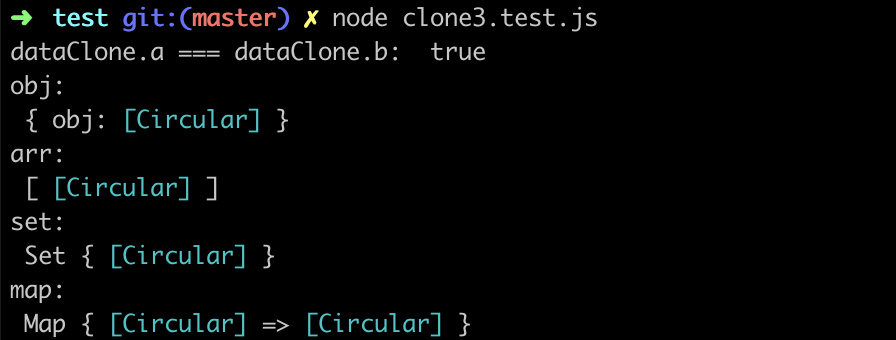
}经过改造后的深拷贝函数能够保留原数据的引用关系,也可以正确处理不同引用类型的循环引用,利用下面的用例 clone3.test.js 来进行验证:
const temp = {}
const data = {
a: temp,
b: temp,
}
const dataClone = cloneDeep(data)
const obj = {}
obj.obj = obj
const arr = []
arr[0] = arr
const set = new Set()
set.add(set)
const map = new Map()
map.set(map, map)结果如下:
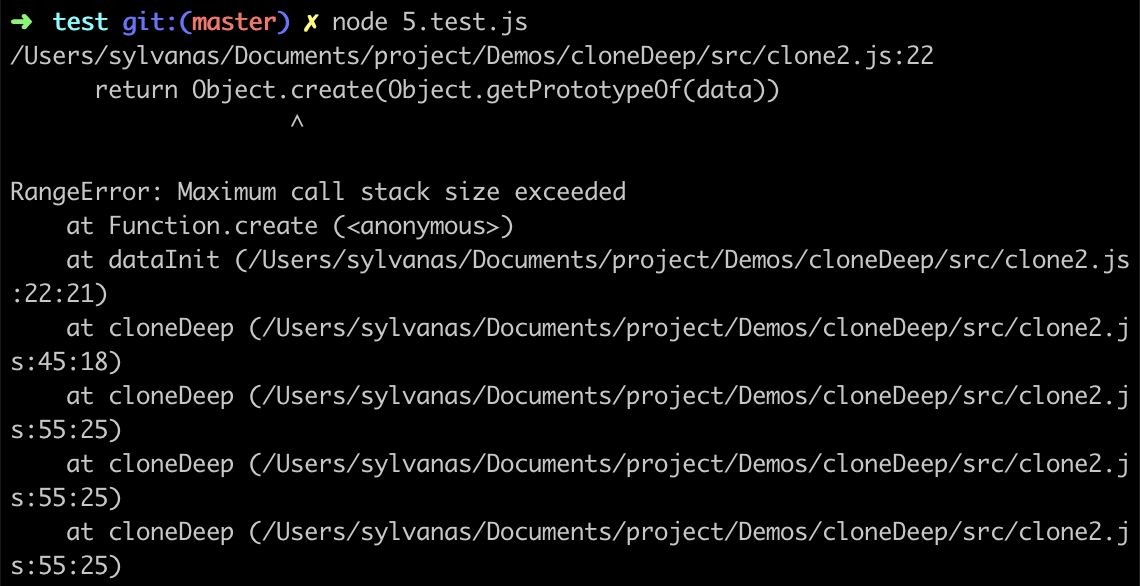
在前面的深拷贝实现方法中,均是通过递归的方式来进行遍历,当递归的层级过深时,也会出现栈溢出的情况,我们使用下面的 create 方法创建深度为10000,广度为100的示例数据:
function create(depth, breadth) {
const data = {}
let temp = data
let i = j = 0
while(i < depth) {
temp = temp['data'] = {}
while(j < breadth) {
temp[j] = j
j++
}
i++
}
return data
}
const data = create(10000, 100)
cloneDeep(data)结果如下:
那么假如不使用递归,我们应该如何实现呢?
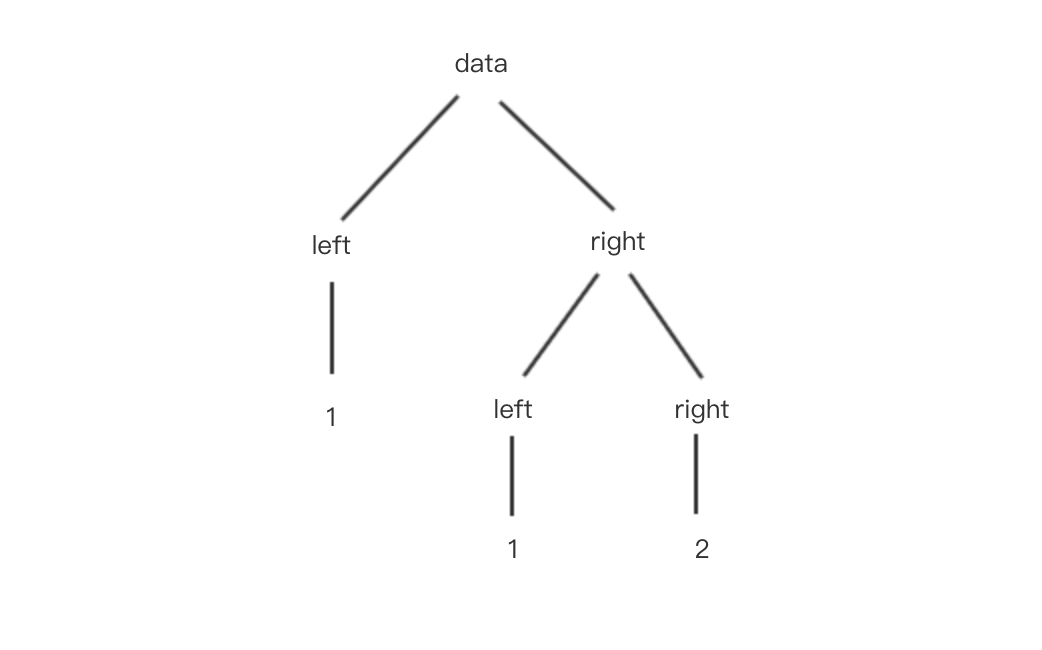
以对象为例,存在下面这样一个数据结构:
const data = {
left: 1,
right: {
left: 1,
right: 2,
}
}那么换个角度看,其实它就是一个类树形结构:
我们对该对象进行遍历实际上相当于模拟对树的遍历。树的遍历主要分为深度优先遍历和广度优先遍历,前者一般借助栈来实现,后者一般借助队列来实现。
这里模拟了树的深度优先遍历,仅考虑对象和非对象,利用栈来实现一个不使用递归的简单深拷贝方法:
function cloneDeep(data) {
const retVal = {}
const stack = [{
target: retVal,
source: data,
}]
// 循环整个stack
while(stack.length > 0) {
// 栈顶节点出栈
const node = stack.pop()
const { target, source } = node
// 遍历当前节点
for(let item in source) {
if (source.hasOwnProperty(item)) {
if (Object.prototype.toString.call(source[item]) === '[object Object]') {
target[item] = {}
// 子节点如果是对象,将该节点入栈
stack.push({
target: target[item],
source: source[item],
})
} else {
// 子节点如果不是对象,直接拷贝
target[item] = source[item]
}
}
}
}
return retVal
}关于完整的深拷贝非递归实现,可以参考 clone4.js ,对应的测试用例为 用例 clone4.test.js ,这里就不给出了
这里列举了常见的几种深拷贝方法,并进行简单比较
关于耗时比较,采用前文的 create 方法创建了一个广度、深度均为1000的数据,在 node v10.14.2 环境下循环执行以下方法各10000次,这里的耗时取值为运行十次测试用例的平均值,如下:
| 基本类型 | 数组、对象 | 特殊引用类型 | 循环引用 | 耗时 | |
|---|---|---|---|---|---|
| JSON | 无法处理 NaN 、 Infinity 、 Undefined |
丢失对象原型 | ❌ | ❌ | 7280.6ms |
| $.extend | 无法处理 Undefined |
丢失对象原型、拷贝原型属性 | ❌ (使用同一引用) |
❌ | 5550.6ms |
| cloneDeep | ✔️ | ✔️ | ✔️(待完善) | ✔️ | 5035.3ms |
| _.cloneDeep | ✔️ | ✔️ | ✔️ | ✔️ | 5854.5ms |
在日常的使用过程中,如果你确定你的数据中只有数组、对象等常见类型,你大可以放心使用JSON序列化的方式来进行深拷贝,其它情况下还是推荐引入 loadsh/cloneDeep 来实现
深拷贝的水很“深”,浅拷贝也不“浅”,小小的深拷贝里面蕴含的知识点十分丰富:
我相信,要是面试官愿意挖掘的话,能考查的知识点远不止这么多,这个时候就要考验你自己的基本功以及知识面的深广度了,而这些都离不开平时的积累。千里之行,积于跬步,万里之船,成于罗盘
本文如有错误,还请各位批评指正~
最近在对项目做 IE 11 兼容,由 IE 的缓存问题,引发我对于浏览器缓存策略的思考。
web缓存主要可以分为下面几类:
这里我们主要关注客户端,也就是浏览器缓存。
浏览器和服务器通信是通过 HTTP 协议,浏览器向服务器发起 HTTP 请求,服务器作出响应。当再次发起请求的时候,可以直接读取缓存中的数据,减少网络带宽的消耗,提升页面的访问速度。
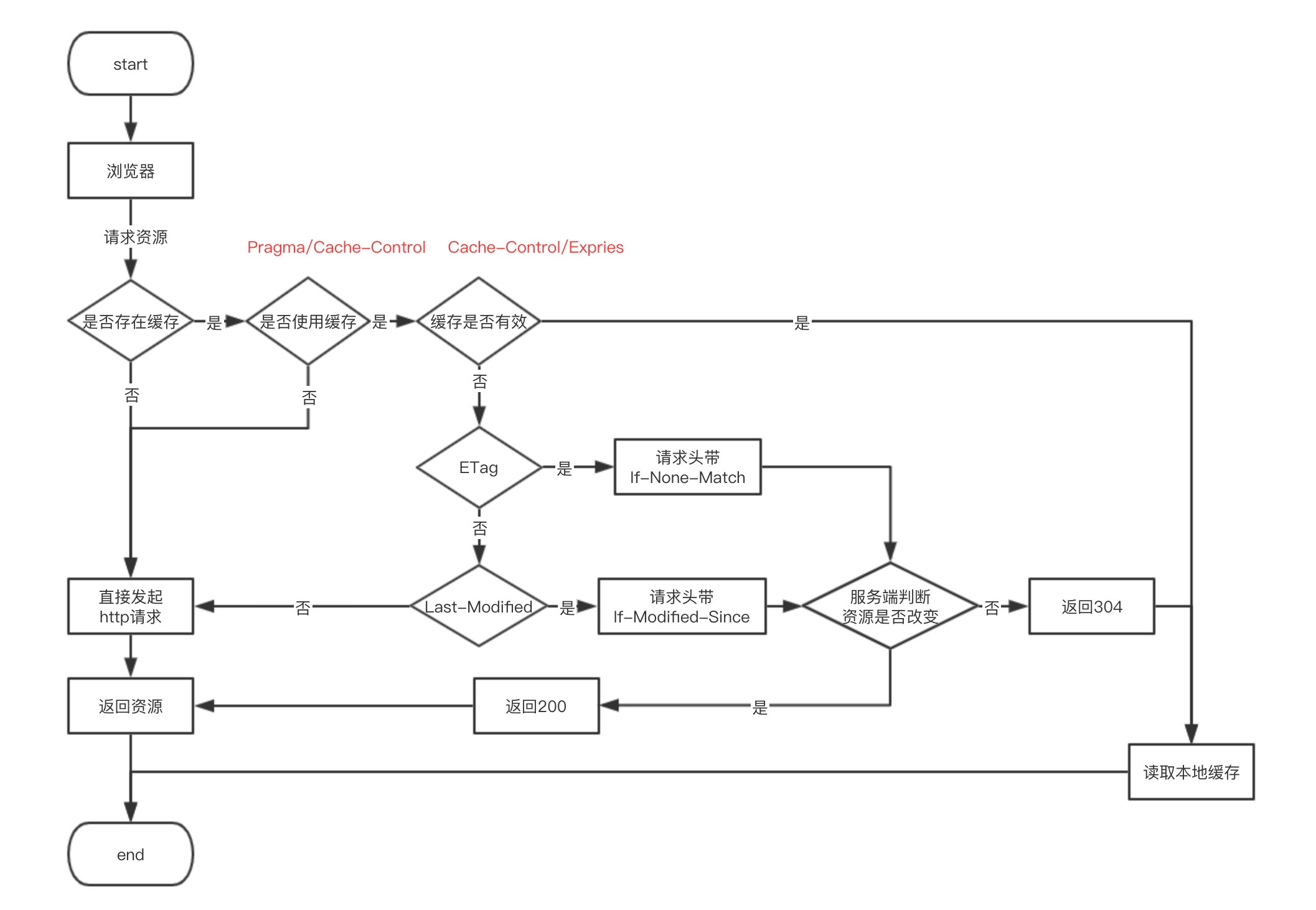
根据是否重新发起 HTTP 请求,可以将浏览器缓存分为两种:强制缓存和协商缓存。
与强制缓存有关的 HTTP 头部有 Expires 和 Cache-Control
Expires 响应头包含一个 HTTP 日期(GMT 时间,非本地时间),表示资源过期的时间。
当设置无效值,例如 0,表示资源立即过期,即不使用缓存。
//...
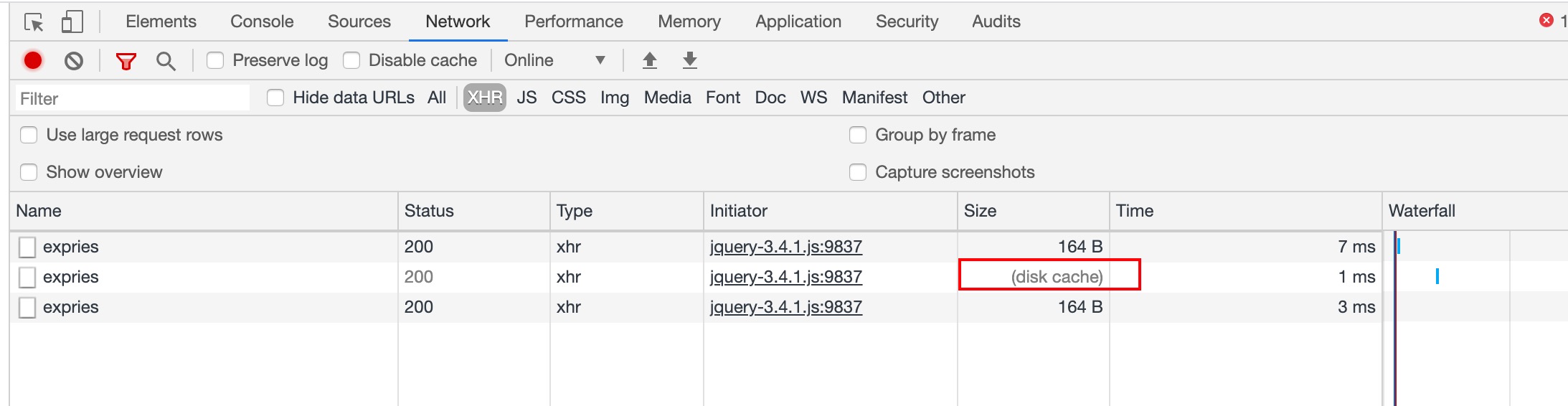
const getGMT = () => `${moment().utc().add(1, 'm').format('ddd, DD MMM YYYY HH:mm:ss')} GMT`
app.get('/expries', (req, res) => {
res.setHeader('Expires', getGMT());
res.end('ok')
});这里使用 express 创建了一个 web 服务,在 header 中添加了 Expires 响应头,利用 moment 转化为相应的 GMT 格式,设置为 10s 后过期,可以看到首次请求时向服务端发起了 HTTP 请求,第二次则使用了缓存(disk cache),超过 10s 之后再请求时(第三次)缓存过期,重新向服务端发起 HTTP 请求。
请求时带上 Expries 请求头:
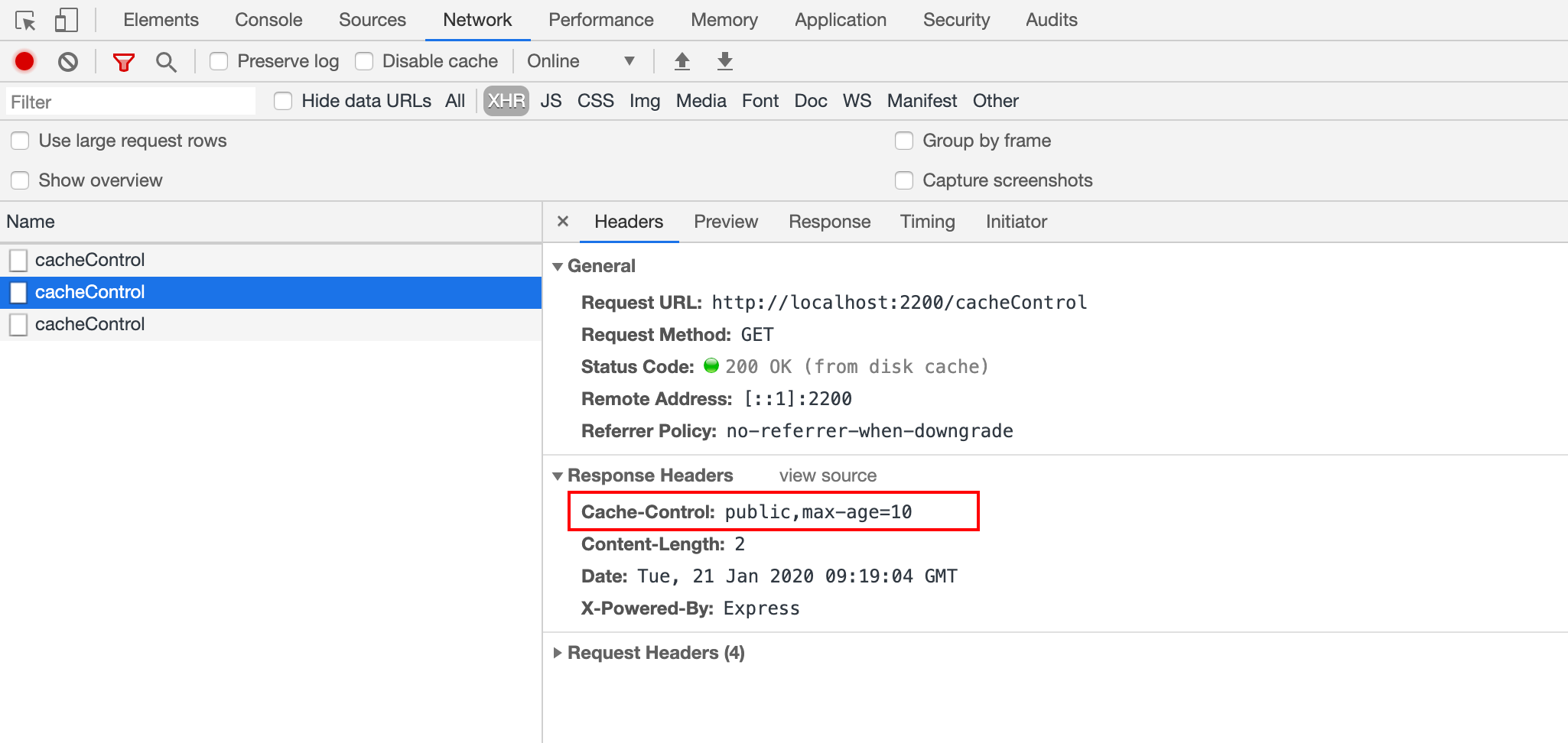
Cache-Control 是一个通用首部,既可以设置在请求头中,也可以设置在响应头中,常用的取值包括以下几种:
| Cache-Control 取值 | 含义 |
|---|---|
| no-store | 绝对禁止缓存 |
| no-cache | 会被缓存,但是立刻过期,要求将请求提交给原始服务器进行验证,相当于 max-age=0 |
| private | 只有浏览器可以缓存,禁止代理服务器、CDN等中间人缓存 |
| public | 资源可以被任何对象缓存 |
| max-age | 表示资源被缓存的最大时间,单位秒;当设置该值时,Expries 头部会被忽略 |
其中private、public只能用于响应头部中
在强制缓存中,我们根据时间来判断资源是否过期,这会存在一定弊端,当过期时间到了,即使服务端资源未改动,也会重新获取。由此我们引进了协商缓存的概念,协商缓存需要浏览器和服务器共同实现,与协商缓存有关的响应头部字段主要为以下两组:
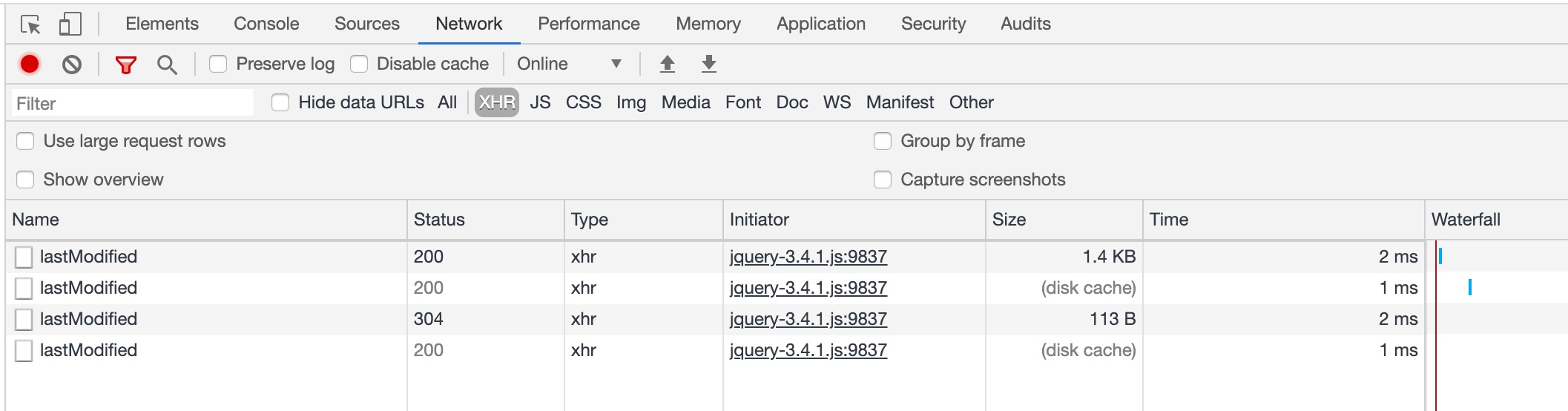
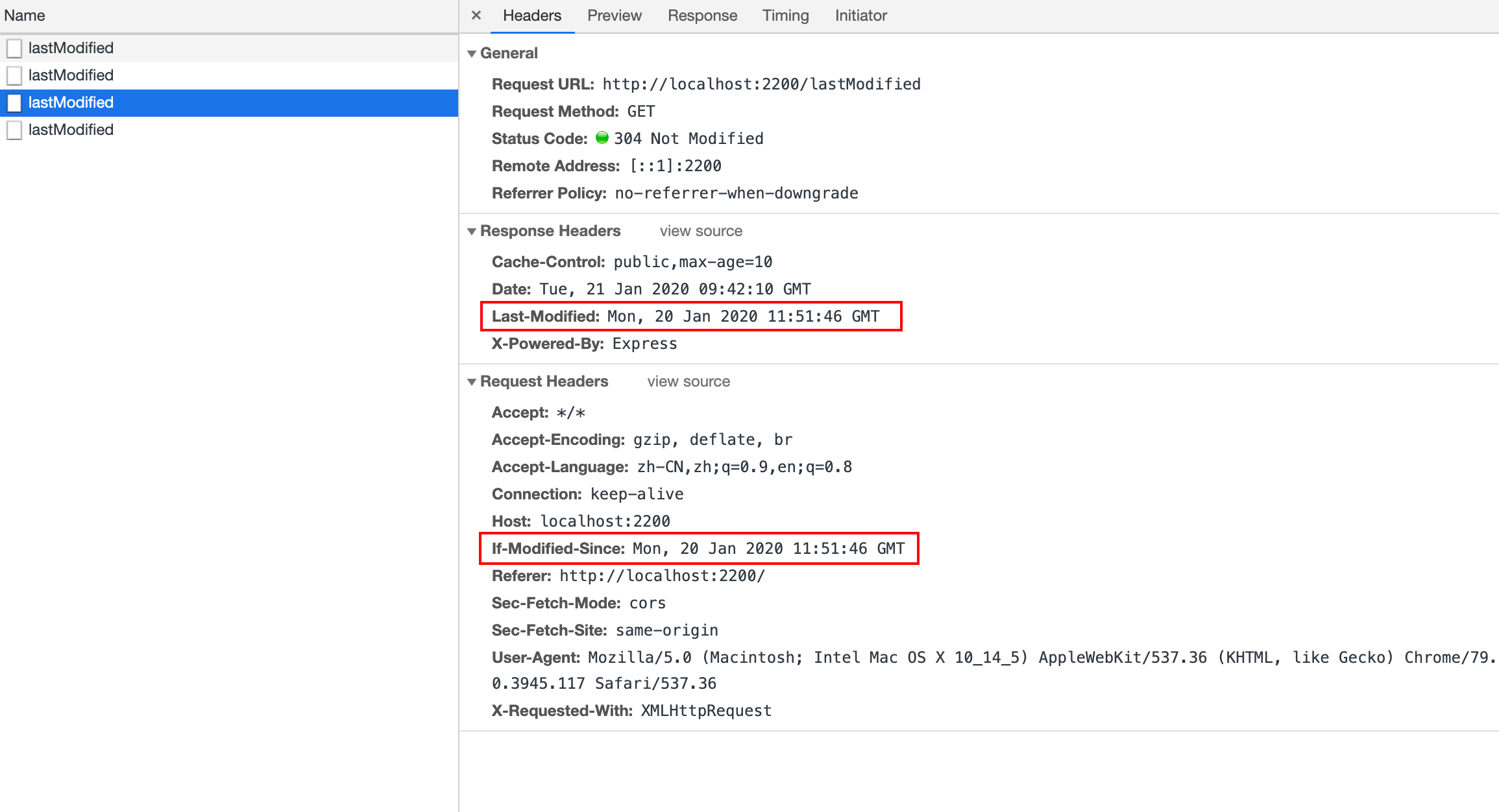
Last-Modified 和 If-Modified-SinceETag 和 If-None-MatchLast-Modified 表示资源最后的修改时间(GMT 格式),具体过程如下:
Last-Modified 响应头部,告诉浏览器该资源的最后修改时间If-Modified-Since 这个请求头部,它的值即为上一次请求响应的 Last-Modified,服务端比较两个字段的值,如果一致,说明资源未改动,返回 304,否则返回更改后的资源。可以看到再次请求时自动加上 If-Modified-Since 请求头部:
服务端实现如下:
const filePath = path.join(__dirname, '../static/index.html')
app.get('/lastModified', (req, res) => {
const stat = fs.statSync(filePath);
const file = fs.readFileSync(filePath);
const lastModified = stat.mtime.toUTCString();
res.setHeader('Cache-Control', 'public,max-age=10');
if (lastModified === req.headers['if-modified-since']) {
res.writeHead(304, 'Not Modified');
res.end();
} else {
res.setHeader('Last-Modified', lastModified);
res.writeHead(200, 'OK');
res.end(file);
}
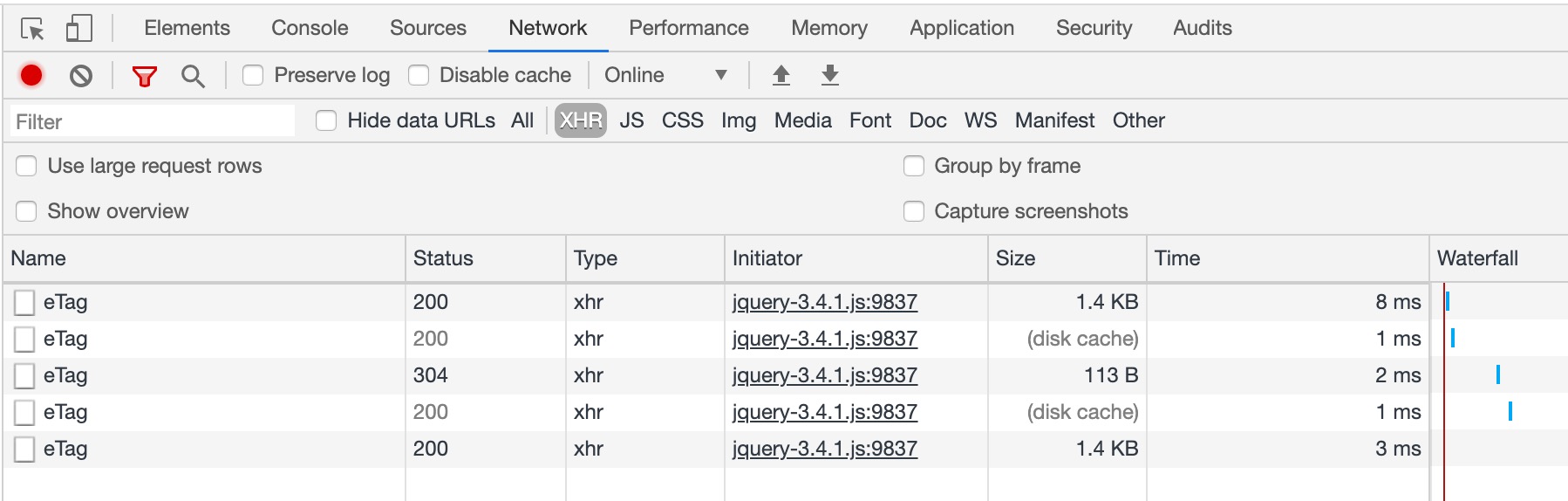
});当资源发生多次改动,但是资源内容未改变时,此时服务器仍需要重新返回资源。为了提升判断的精确度,引入 ETag 响应头部,表示资源特定版本的标识符,当文件内容未发生变化时,该标识符的值不会改变。具体过程如下:
ETag 响应头部,告诉浏览器该资源的特殊标识If-None-Match 这个请求头部,它的值即为上一次请求响应的 ETag,服务端比较两个字段的值,如果一致,说明资源未改动,返回 304,否则返回更改后的资源。当文件发生变化时,响应头部的 ETag 和请求头部的 If-None-Match 不一致:
服务端实现如下:
const filePath = path.join(__dirname, '../static/index.html')
// 创建 md5 加密
const cryptoFile = (file) => {
const md5 = crypto.createHash('md5');
return md5.update(file).digest('hex');
}
app.get('/eTag', (req, res) => {
const file = fs.readFileSync(filePath);
const eTag = cryptoFile(file)
res.setHeader('Cache-Control', 'public,max-age=10');
if (eTag === req.headers['if-none-match']) {
res.writeHead(304, 'Not Modified');
res.end();
} else {
res.setHeader('ETag', eTag);
res.writeHead(200, 'OK');
res.end(file);
}
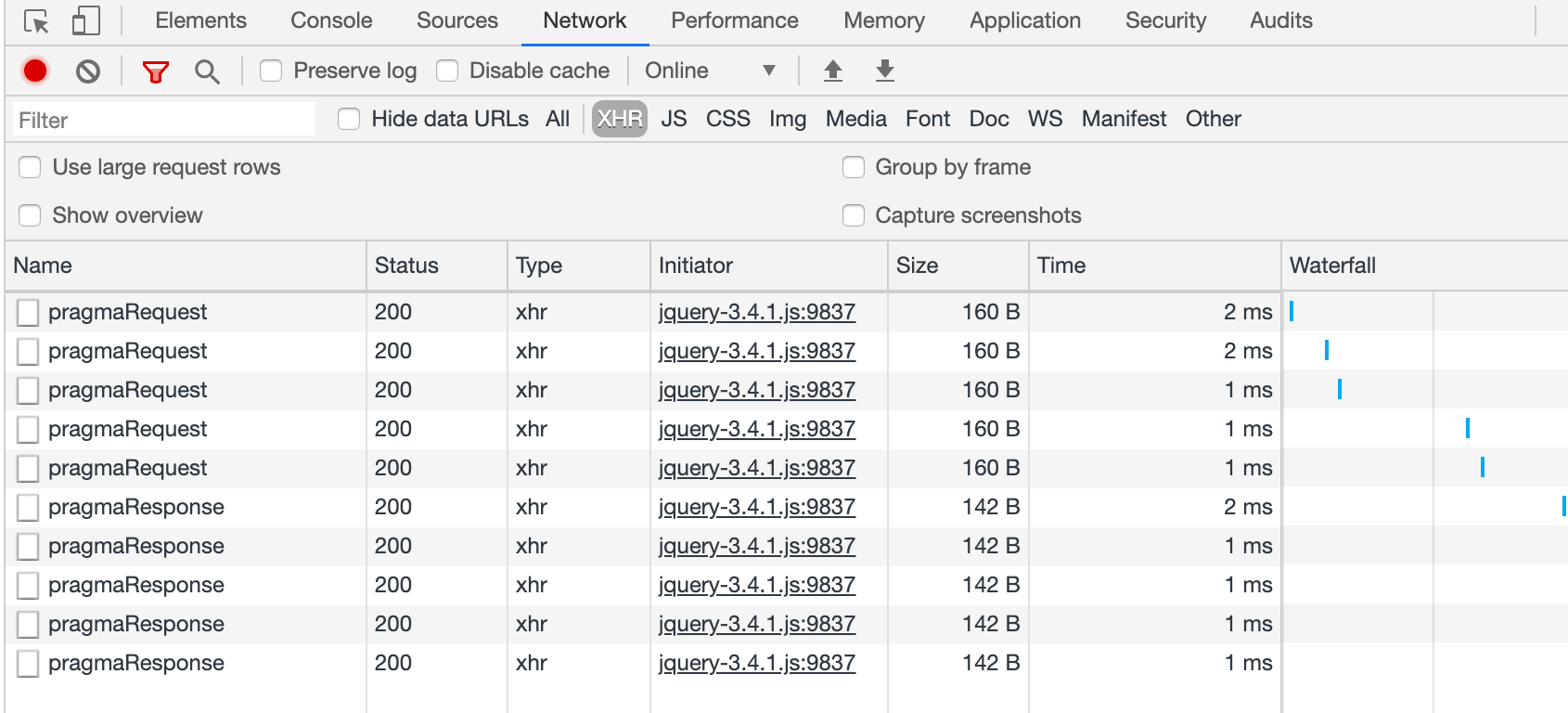
})在 HTTP/1.0 时期存在一个通用首部 Pragma ,当它的值为 no-cache 时,与 Cache-Control: no-cache 的行为一致。它在“请求-响应”链中可能会有不同的效果,现在一般用于向后兼容只支持 HTTP/1.0 的客户端。
Chrome 下测试,在请求头部/响应头部中设置 Pragma: 'no-cache' 均可以实现禁用缓存:
但在 IE 11 下,当 Pragma 置于响应头部时并未生效,可以在 IE 11 下运行测试代码进行验证。
在 chrome 下控制台可以看到浏览器本地缓存分为两类:memory cache 和 disk cache,即内存缓存和磁盘缓存。
那么浏览器是如何区分哪些资源存放在内存中,哪些又存在磁盘中呢?
其实这个问题没有一个标准答案,普遍认为和系统当前内存的使用情况有关,如果当前系统内存使用率高,那么会优先存储在磁盘中;另外一个就是对于大文件,一般存储在磁盘中。
关于优先级,强制缓存的优先级总是大于协商缓存,只有在强制缓存失效后才会发起请求进行协商缓存;
而在协商缓存中,Last-Modified表示的是一个 GMT 格式的时间,只能精确到秒,因此 ETag 的精确度要高于 Last-Modified,但同时每次进行 hash 运算生成标识也会带来额外的开销。二者都存在时,服务端应以 ETag 为准。
总的优先级如下:
Pragma > Cache-Control > Expries > ETag > Last-Modified
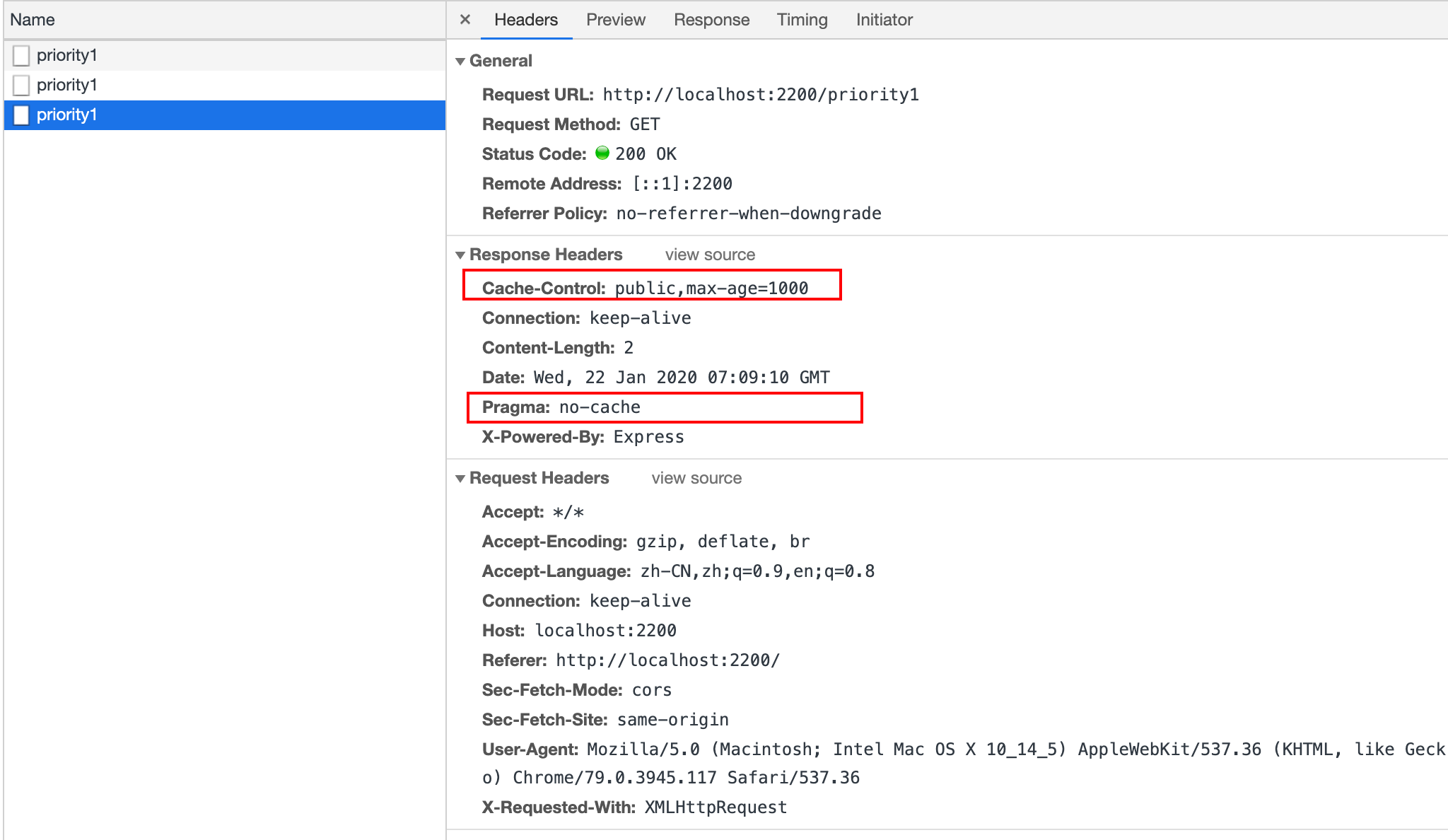
在Chrome下验证,当 Pragma为 no-cache,Cache-Control 设置 1000s 缓存时,浏览器会禁用缓存:
同样,设置响应头为 Cache-Control: 'no-cache' 和 Expries 为 1000s 后过期,浏览器依然禁用缓存:
整体的缓存过程如下:
兼容 IE 11 的过程中踩过一些坑,在实际项目中遇到的印象比较深刻的问题是下面这个:
::: tip
由于 IE 对 GET 接口的缓存,当用户首次进入系统时,因为未登录跳转至sso,登录成功之后仍然返回的是缓存中的未登录,导致登录之后出现闪屏,在原系统和sso之间不停来回跳转。
:::
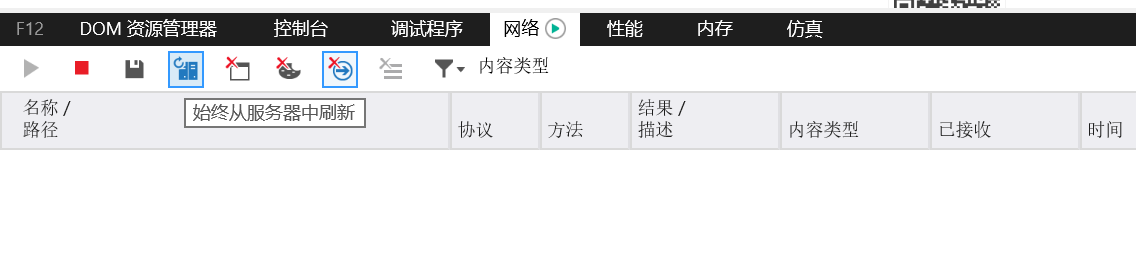
另外,由于 IE 浏览器打开控制台之后默认开启始终从服务端刷新,在 debug 阶段着实给我造成了不小的困扰,后来放弃使用控制台,通过抓包工具Charles进行截取、分析,这才定位到问题。
究其原因,是 IE 对于 GET 请求的缓存策略问题:
多次发起 GET 请求时,若 url 未发生变化,IE 则认为这是非首次请求,直接读取缓存。
通过在 get 请求的 url 中加入随机标识,例如时间戳、随机数等,来达到变更 url 的目的,此时浏览器不会从缓存中读取数据
服务端设置响应头部禁止浏览器缓存
{
'Cache-Control': 'no-cache',
'Pragma': 'no-cache',
'Expires': -1,
}在实际项目中我采用的是这种解决方案
{
'Cache-Control': 'no-cache',
'Pragma': 'no-cache',
}本文旨在总结 TypeScript 的体系化知识,帮助你了解并熟悉 TypeScript 的各项特性
TypeScript 是 JavaScript 的超集,通过添加静态类型定义与检查来对 JavaScript 进行扩展,TypeScript 与 JavaScript 的关系类似 Less/Sass 与 Css
JavaScript 是弱类型语言,很多错误会在运行时才被发现,而 TypeScript 提供的静态类型检查可以帮助开发者避免大部分运行时的错误,并且能够大大增强代码的可维护性。相应的,付出的代价则是开发阶段需要书写相关的类型,成本方面有一定的提升
TypeScript 官方提供了一个在线的 TypeScript 开发环境 Playground,你可以很方便地在上面进行 TypeScript 的相关练习,支持配置 tsconfig,静态类型检测以及 TypeScript 代码编译执行等
在 TypeScript 中,对于 JavaScript 中的原始数据类型都有对应的类型:
e.g.
const str: string = 'text'
const num: number = 1
const bool: boolean = true
const undef: undefined = undefined
const null: null = null
const symb: symbol = Symbol('symb')
const bigint: bigint = BigInt(9007199254740993)object 表示所有的非原始类型,包括数组、对象、函数等e.g.
let demo: object
demo = []
demo = {}
demo = () => {}
demo = 1 // Error: Type 'number' is not assignable to type 'object'在 JavaScript 里 Object 是所有原型链的最上层,在 TypeScript 里则表现为 Object 可以表示所有的类型, 而 {} 均表示所有非 null 和 undefined 的类型,null 和 undefined 在 strictNullChecks=false 时才允许被赋值给 Object 和 {}
let demo1: Object
demo1 = []
demo1 = {}
demo1 = 1
demo1 = null // Error: Type 'null' is not assignable to type 'Object'
demo1 = undefined // Error: Type 'undefined' is not assignable to type 'Object'
let demo2: {}
demo2 = []
demo2 = {}
demo2 = 1
demo2 = null // Error: Type 'null' is not assignable to type '{}'
demo2 = undefined // Error: Type 'undefined' is not assignable to type '{}'使用建议:
- 在任何时候都不要使用
Object及类似的装箱类型- 避免使用
{},它表示任何非null/undefined的值,与any类似- 对于无法确定类型,但可以确定不为原始类型的,可以使用
object-- 更推荐使用具体的描述:Record<string, any>或者unknown[]等
数组定义有两种方式:
const arr: string[] = []
// 等价于
const arr: Array<string> = []数组合并了相同的类型,元组则合并不同的类型:
const tup: [string, number] = ['LiHua', 18]元组中的选项还可以是可选的
// 支持可选
const tup1: [string, number?] = ['LiHua']
// 支持对属性命名
const tup2: [name: string, age?: number] = ['LiHua']
// 一个 react useState 的例子
const [state, setState] = useState();函数定义方式可以是以下几种:
// 函数式声明
function test1(x: number, y: number): number {
return x + y
}
// 表达式声明
const test2: (x: number, y: number) => number = (x, y) => {
return x + y
}
// 或
const test3 = (x: number, y: number): number => {
return x + y
}在 JavaScript 中,void 作为立即执行的函数表达式,用于获取 undefined:
// 返回 undefined
void 0
// 等价于
void(0)在 TypeScript 中则描述了一个函数没有显示返回值时的类型,例如下面这几种情况都可以用 void 来描述:
// case 1
function test1() {}
// case 2
function test2() {
return;
}
// case 3
function test3() {
return undefined;
}区别
any,any 也可以赋值给任意类型;任意类型都能赋值给 unknown,但是 unknown 只能赋值给 unknown/any 类型:let type1: any
// 被任意类型赋值
type1 = 1
// 赋值给任意类型
let type2: number = type1
let type3: unknown
// 被任意类型赋值
type3 = 1
// 赋值给任意类型
let type4: number = type3 // Error: Type 'unknown' is not assignable to type 'number'let str1: unknown = 'string';
str1.slice(0, 1) // Error: Object is of type 'unknown'.
let str2: any = 'string';
str2.slice(0, 1) // Success添加类型推断后则可以正常使用:
let str: unknown = 'string';
// 1. 通过 as 类型断言
(str as string).slice(0, 1)
// 2. 通过 typeof 类型推断
if (typeof str === 'string') {
str.slice(0, 1)
}滥用 any 的一些场景以及使用建议:
- 类型不兼容时使用
any:推荐使用as进行类型断言- 类型太复杂不想写使用
any:推荐使用as进行类型断言,找到你所需要的最小单元- 不清楚具体类型是什么而使用
any:推荐声明时使用unknown来代替,在具体调用的地方再进行断言
表示不存在的类型,一般在抛出异常以及出现死循环的时候会出现:
// 1.抛出异常
function test1(): never {
throw new Error('err')
}
// 2. 死循环
function test2(): never {
while(true) {}
}never 也存在主动的使用场景,比如我们可以进行详细的类型检查,对穷举之后剩下的 else 条件分支中的变量设置类型为 never,这样一旦 value 发生了类型变化,而没有更新相应的类型判断的逻辑,则会产生报错提示
const checkValueType = (value: string | number) => {
if (typeof value === 'string') {
// do something
} else if (typeof value === 'number') {
// do something
} else {
const check: never = value
// do something
}
}例如这里 value 发生类型变化而没有做对应处理,此时 else 里的 value 则会被收窄为 boolean,无法赋值给 never 类型,导致报错,这样可以确保处理逻辑总是穷举了 value 的类型:
const checkValueType = (value: string | number | boolean) => {
if (typeof value === 'string') {
// do something
} else if (typeof value === 'number') {
// do something
} else {
const check: never = value // Error: Type 'boolean' is not assignable to type 'never'.
// do something
}
}指定具体的值作为类型,一般与联合类型一起使用:
const num_literal: 1 | 2 = 1
const str_literal: "text1" | "text2" = "text1"枚举使用 enum 关键字来声明:
enum TestEnum {
key1 = 'value1',
key2 = 2
}JavaScript 对象是单向映射,而对于 TypeScript 中的枚举,字符串类型是单向映射,数字类型则是双向映射的,上面的枚举编译成 JavaScript 会被转换成如下内容:
"use strict";
var TestEnum;
(function (TestEnum) {
TestEnum["key1"] = "value1";
TestEnum[TestEnum["key2"] = 2] = "key2";
})(TestEnum || (TestEnum = {}));对于数字类型的枚举,相当于执行了 obj[k] = v 和 obj[v] = k,以此来实现双向映射
使用 const 定义,与普通枚举的区别主要在于不会生成上面的辅助函数 TestEnum,编译产物只有 const val = 2
const enum TestEnum {
key1 = 'value1',
key2 = 2
}
const val = TestEnum.key2接口 interface 是对行为的抽象, TypeScript 里常用来对对象进行描述
可选属性,通过? 将该属性标记为可选
interface Person {
name: string
addr?: string
}只读属性,对于对象修饰对象的属性为只读;对于 数组/元组 只能将整个 数组/元组 标记为只读
interface Person {
name: string
readonly age: number
}
const person: Person = { name: 'LiHua', age: 18 }
person.age = 20 // Cannot assign to 'age' because it is a read-only property
const list: readonly number[] = [1, 2]
list.push(3) // Property 'push' does not exist on type 'readonly number[]'.
list[0] = 2 // Index signature in type 'readonly number[]' only permits reading类型别名主要利用 type 关键字,来用于对一组特定类型进行封装,我们在 TypeScript 里的类型编程以及各种类型体操都离不开类型别名
type Person = {
name: string;
readonly age: number;
addr?: string;
}相同点:
type Person = {
name: string
}
// 接口通过继承的方式实现类型扩展:
interface Person1 extends Person {
age: number
}
// 类型别名通过交叉类型的方式实现类型扩展:
type Person2 = Person & {
age: number
}不同点:
type 可以用来定义原始类型、联合/交叉类型、元组等,interface 则不行type str = string
type num = number
type union = string | number
type tup = [string, number]interface 声明的同名类型可以进行合并,而 type 则不可以,会报标识符重复的错误interface Person1 {
name: string
}
interface Person1 {
age: string
}
let person: Person1 // { name: string; age: string }
type Person2 {
name: string
}
// Error: Duplicate identifier 'Person2'
type Person2 {
age: string
}interface 会有索引签名的问题,而 type 没有interface Test1 {
name: string
}
type Test2 = {
name: string
}
const data1: Test1 = { name: 'name1' }
const data2: Test2 = { name: 'name2' }
interface PropType {
[key: string]: string
}
let prop: PropType
prop = data1 // Error: Type 'Test1' is not assignable to type 'PropType'. Index signature for type 'string' is missing in type 'Test1'
prop = data2 // success因为只有当该类型的所有属性都已知并且可以对照该索引签名进行检查时,才允许将子集分配给该索引签名类型。而 interface 允许类型合并,所以它的最终类型是不确定的,并不一定是它定义时的类型;type 声明的类型时的索引签名是已知的
建议:
官方推荐使用interface,当interface无法满足,例如需要定义联合类型等,再选择使用type
TypeScript/type-aliases
表示一组可用的类型集合,只要属于其中之一就属于这个联合类型
const union: string | number = 'text'表示一组类型的叠加,需要满足所有条件才可以属于这个交叉类型,一般用于接口的合并
interface A {
field1: string
}
interface B {
field2: number
}
const test: A & B = { field1: 'text', field2: 1 }如果新的类型不可能存在,则会被转换为 never,例如这里的 number & string:
type A = number
type B = string
type Union = A & B // never对于对象类型的交叉类型,会按照同名属性进行交叉,例如下面的 common 需要即包含 fieldA 也包含 fieldB:
interface A {
field1: string
common: {
fieldA: string
}
}
interface B {
field2: number
common: {
fieldB: number
}
}
const fields: A & B = {
field1: 'text1',
field2: 1,
common: { fieldA: 'text2', fieldB: 2 }
}
// success“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
鸭子类型放在 TypeScript 里来说就是我们可以在鸟上构建走路、游泳、叫等方法,创建一只像鸭子的鸟,来绕开对鸭子的类型检测
e.g.
interface Param {
field1: string
}
const func = (param: Param) => param
func({ field1: '111', field2: 2 }) // Error
const param1 = { field1: '111', field2: 2 }
func(param1) // success在这里我们构造了一个函数 func 接受参数为 Param ,当我们直接调用 func 传参时,相当于是赋值给变量 param,此时会严格按照参数校验进行,因此会报错;
而如果我们使用一个变量存储,再将变量传递给 func,此时则会应用鸭子类型的特性,因为 param1 中 包含 field1 ,TypeScript 会认为 param1 已经完全实现了 Param ,可以认为 param1 对应的类型是 Param 的子类,这个时候则可以绕开对多余的 field2 的检测
类型断言也可以绕过类型检测,上面的例子可以改成用类型断言来实现:
interface Param {
field1: string
}
const func = (param: Param) => param
func({ field1: '111', field2: 2 } as Param) // success另外一种断言方式是非空断言,利用 ! 关键词,可以从类型中排除 undefined 和 null :
const func = (str: string) => str
const param = ['text1', 'text2'].find(str => str === 'text1')
func(param) // Error
func(param!) // success泛型是一种抽象类型,只有在调用时才知道具体的类型。如果将类型类比为函数,那么泛型就相当于函数中的参数了
// 定义
type Test<T> = T | string;
// 使用
const test: Test<number> = 1
// react 中的例子
const [state, setState] = useState<number>(0)函数中定义泛型
// 函数式声明
function func<T>(param: T): T {
return param;
}
// 表达式声明
const func: <T>(param: T) => T = (param) => {
return param;
}在 TypeScript 中,可以通过类型操作符来对类型进行操作,基于已有的类型创建新的类型,主要包括以下几种:
typeof 可以获取变量或者属性对应的类型,返回的是一个 TypeScript 类型:
const str = 'text'
type Str = typeof str // string对于对象类型的变量,则会保留键名,返回推断得到的键值的类型:
const obj = {
field1: 'text',
field2: 1,
field3: {
field: 'text'
}
}
type ObjType = typeof obj
// {
// field1: string;
// field2: number;
// field3: {
// field: string;
// };
// }注意:
如果你为变量指定了相应的类型,例如any,那么typeof将会直接返回你预定义的类型而不会进行类型推断
keyof 用于获取类型中所有的键,返回一个联合类型:
interface Test {
field1: string;
field2: number;
}
type Fields = keyof Test
// "field1" | "field2"in 用于遍历类型,它是 JavaScript 里已有的概念:
type Fields = 'field1' | 'field2'
type Test = {
[key in Fields]: string
}
// Test: { field1: string; field2: string }extends 用于对泛型添加约束,使得泛型必须继承这些类型,例如这里要求泛型 T 必须要属于 string 或者 number:
type Test<T extends string | number> = T[]
type TestExtends1 = Test<string> // success
type TestExtends2 = Test<boolean> // Type 'boolean' does not satisfy the constraint 'string | number'.extends 还可以在条件判断语句中使用:
type Test<T> = T extends string | number ? T[] : T
type TestExtends1 = Test<string> // string[]
type TestExtends2 = Test<boolean> // booleaninfer 主要用于声明一个待推断的类型,只能结合 extends 在条件判断语句中使用,我们以内置的工具类 ReturnType 为例,它主要作用是返回一个函数返回值的类型,这里用 infer 表示待推断的函数返回值类型:
type ReturnType<T extends (...args: any) => any> = T extends (
...args: any
) => infer R ? R : any这里声明了一个包含索引签名且键为 string 的类型:
interface Test {
[key: string]: string;
}包含索引签名时,其他具体键的类型也需要符合索引签名声明的类型:
interface Test {
// Error: Property 'field' of type 'number' is not assignable to 'string' index type 'string'
field: number;
[key: string]: string;
}获取索引类型,通过 keyof 关键字,返回一个由索引组成的联合类型:
interface Test {
field1: string;
field2: number;
}
type Fields = keyof Test
// "field1" | "field2"访问索引类型,通过访问键的类型,来获取对应的索引签名的类型:
interface Test {
field1: string;
field2: number
}
type Field1 = Test["field1"] // string
type Field2 = Test["field2"] // number
// 配合 keyof,可以获取索引签名对应类型的联合类型
type Fields = Test[keyof Test] // string | number注意:
这里的 field1/field2 不是字符串,而是字面量类型
因此我们还可以通过键的类型来访问:
interface Test {
[key: string]: number;
}
type Field = Test[string] // number与索引类型常常搭配使用的是映射类型,主要概念是根据键名映射得到键值类型,从旧的类型生成新的类型。我们利用 in 结合 keyof 来对泛型的键进行遍历,即可得到一个映射类型,很多 TypeScript 内置的工具类的实现都离不开映射类型。
以实现一个简单的 ToString ,能将接口中的所有类型映射为 string 类型为例:
type ToString<T> = {
[key in keyof T]: string
}
interface Test {
field1: string;
field2: number;
field3: boolean;
}
type Fields = ToString<Test>这里我们列举了一些 TypeScript 内置的常用工具链的具体实现:
将所有属性变为可选,首先通过 in 配合 keyof 遍历 T 的所有属性赋值给 P,然后配合 ? 将属性变为可选,最后 T[P] 以及 undefined 作为返回类型:
type Partial<T> = {
[P in keyof T]?: T[P] | undefined;
}使用示例:
interface Person {
name: string;
age?: number;
}
type PersonPartial = Partial<Person>
// { name?: string | undefined; age?: number | undefined }Partial 只能将最外层的属性变为可选,类似浅拷贝,如果要想把深层地将所有属都变成可选,可以手动实现一下:
type DeepPartial<T> = {
[P in keyof T]?: T[P] extends object ? DeepPartial<T[P]> : T[P] | undefined
}将所有属性变为必选,与 Partial 实现的思路类似,只不过变成了通过 -? 来去除可选符号:
type Required<T> = {
[P in keyof T]-?: T[P];
}使用示例:
interface Person {
name: string;
age?: number;
}
type PersonRequired = Required<Person>
// { name: string; age: number }将所有属性都变成只读,不可修改,与 Partial 实现的思路类似,利用 readonly 关键字来标识:
type Readonly<T> = {
readonly [P in keyof T]: T[P];
}使用示例:
interface Person {
name: string;
age?: number;
}
type PersonReadonly = Readonly<Person>
// { readonly name: string; readonly age?: number | undefined }以指定的类型生成对应类型的键值对,例如我们经常会使用 Record<string, unknown> 或者 Record<string, any> 来对对象的类型进行声明,这里主要通过 K extends string | number | symbol 来限制 K 必须符合索引的类型:
type Record<K extends string | number | symbol, T> = {
[P in K]: T;
}移除属于指定类型的部分,通过判断如果 T 继承自 U,那么返回 never ,则会移除 T 中属于 U 的类型:
type Exclude<T, U> = T extends U ? never : T使用示例:
type Test = string | number
type TestExclude = Exclude<Test, string> // number保留属于指定类型的部分,与 Exclude 逻辑相对应,在这里则指保留 T 中属于 U 的类型:
type Extract<T, U> = T extends U ? T : never使用示例:
type Test = string | number
type TestExtract = Extract<Test, string> // string去除类型中的 null 和 undefined :
type NonNullable<T> = T extends null | undefined ? never : T使用示例:
type Test = string | number | null | undefined
type TestNonNullable = NonNullable<Test> // string | number以选中的属性生成新的类型,类似 lodash.pick,这里首先通过 extends 配置 keyof 获取到 T 中的所有子类型并赋值给 K,当 P 属于 K 中的属性时,返回 T 对应的类型 T[P]:
type Pick<T, K extends keyof T> = {
[P in K]: T[P];
}使用示例:
interface Person {
name: string;
age?: number;
}
type PersonPick = Pick<Person, 'age'>
// { age?: number }排除选中的属性,以剩余的属性生成新的类型,与 Pick 作用刚好相反,类似 lodash.omit ,这里首先通过 Exclude<keyof T, K> 来去除掉 T 中包含的属性 K,然后当 P 属于该去除后的类型时,返回 T 对应的类型 T[P]:
type Omit<T, K extends string | number | symbol> = {
[P in Exclude<keyof T, K>]: T[P];
}使用示例:
interface Person {
name: string;
age?: number;
}
type PersonOmit = Omit<Person, 'name'>
// { age?: number }获得函数参数的类型,返回一个元组,这里首先通过扩展运算法,将泛型函数中的参数通过 infer 定义为 P,然后判断 T 是否符合函数的类型定义,如果是则返回 P:
type Parameters<T extends (...args: any) => any> = T extends (
...args: infer P
) => any ? P : never使用示例:
type Func = (param: string) => string[]
type FuncParam = Parameters<Func> // [param: string]获取函数返回值的类型,实现与 Parameters 类似,将定义的类型从函数参数调整为函数的返回值类型:
type ReturnType<T extends (...args: any) => any> = T extends (
...args: any
) => infer R ? R : anytype Func = (param: string) => string[]
type FuncReturn = ReturnType<Func> // string[]tsconfig 是 TypeScript 的项目配置文件,通过它你可以配置 TypeScript 的各种类型检查以及编译选项,这里主要介绍一些常用的 compilerOptions 选项:
// tsconfig.json
{
"compilerOptions": {
/* 构建、工程化选项 */
// baseUrl: 解析的根目录
"baseUrl": "src",
// target: 编译代码到目标 ECMAScript 版本,一般是 es5/es6
"target": "es5",
// lib: 运行时环境支持的语法,默认与 tagert 的值相关联
"lib": ["dom", "es5", "es6", "esnext"],
// module: 编译产物对应的模块化标准,常用值包括 commonjs/es6/esnext 等
"module": "esnext",
// moduleResolution: 模块解析策略,支持 node/classic,后者基本不推荐使用
"moduleResolution": "node",
// allowJs:是否允许引入 .js 文件
"allowJs": true,
// checkJs: 是否检查 .js 文件中的错误
"checkJs": true,
// declaration: 是否生成对应的 .d.ts 类型文件,一般作为 npm 包提供时需要开启
"declaration": false,
// sourceMap: 是否生成对应的 .map 文件
"sourceMap": true,
// noEmit: 是否将构建产物写入文件系统,一个常见的实践是只用 tsc 进行类型检查,使用单独的打包工具进行打包
"noEmit": true,
// jsx: 如何处理 .tsx 文件中对于 jsx 的生成,常用值包括:react/preserve
// 详细比对:https://www.typescriptlang.org/tsconfig#jsx
"jsx": "preserve",
// esModuleInterop: 开启后会生成辅助函数以兼容处理在 esm 中导入 cjs 的情况
"esModuleInterop": true,
// allowSyntheticDefaultImports: 在 cjs 没有默认导出时进行兼容,配合 esModuleInterop 使用
"allowSyntheticDefaultImports": true,
// forceConsistentCasingInFileNames: 是否强制导入文件时与系统文件的大小写一致
"forceConsistentCasingInFileNames": true,
// resolveJsonModule:是否支持导入 json 文件,并做类型推导和检查
"resolveJsonModule": true,
// experimentalDecorators: 是否支持装饰器实验性语法
"experimentalDecorators": true,
/* 类型检查选项 */
// strict: 是否启动严格的类型检查,包含一系列选项:https://www.typescriptlang.org/tsconfig#strict
"strict": true,
// skipLibCheck: 是否跳过非源代码中所有类型声明文件(.d.ts)的检查
"skipLibCheck": true,
// strictNullChecks: 是否启用严格的 null 检查
"strictNullChecks": true,
// noImplicitAny: 包含隐式 any 声明时是否报错
"noImplicitAny": true,
// noImplicitReturns: 是否要求所有函数执行路径中都有返回值
"noImplicitReturns": true,
// noUnusedLocals: 存在未使用的变量时是否报错
"noUnusedLocals": false,
// noUnusedParameters: 存在未使用的参数时是否报错
"noUnusedParameters": false,
}
}gulp是一个自动化构建工具,开发者可以用它来自动执行一些常见的任务。这里以我之前做的一个demo为例,简要介绍如何使用gulp实现前端工程自动化
其中src目录下表示的是项目的源代码,可以看到其中有less、js、html等,而dist目录则是保存的是gulp编译后生成的代码,相当于生产环境。最后也最重要的是gulpfile.js,这个文件用于设置gulp相关的配置,类似于webpack中的webpack.config.js。
这里使用的gulp为v3.9.1,语法和最新的v4.x有所出入,想学习最新的gulp语法,可以参考gulp.js - The streaming build system 。
3.9.1 安装如下:
npm install --save-dev gulpgulp.task()用于定义一个gulp任务,在命令行中可以使用gulp [任务名]开启该任务。gulp.src()会返回符合匹配的文件流,可以被pipe()到其他插件中。gulp.dest():输出所有数据。gulp.watch()用于监测文件的变动。在这个项目中,有一些常见的需求,这里使用gulp来实现自动化:
在gulpfile.js中首先需要导入gulp和一些常用的插件,本次demo使用到的插件如下:
var gulp = require('gulp'),
less = require('gulp-less'), //less 转 css
csso = require('gulp-csso'), //css压缩
concat = require('gulp-concat'), //合并文件
uglify = require('gulp-uglify'), //js 压缩
jshint = require('gulp-jshint'), //js 检查
clean = require('gulp-clean'), //清除文件
imagemin = require('gulp-imagemin'), //图片压缩
rev = require('gulp-rev'), //添加版本号
revReplace = require('gulp-rev-replace'), //版本号替换
useref = require('gulp-useref'), //解析html资源定位
gulpif = require('gulp-if'), //if语句
connect = require('gulp-connect'); //创建web服务器获取到src下所有以.jpg或.png结尾的图片,将其压缩后输出到dist目录下。
gulp.task('dist:img', () => {
gulp.src(['./src/**/*.jpg', './src/**/*.png'])
.pipe(imagemin())
.pipe(gulp.dest('dist/'))
})先清除已存在的css,然后将src下以.less结尾的文件通过less()转为css文件,再通过csso()以及concat()实现对css的压缩合并。
gulp.task('dist:css', () => {
gulp.src('dist/css/*.css').pipe(clean());
return gulp.src('./src/less/*.less')
.pipe(less())
.pipe(csso())
.pipe(concat('public.css'))
.pipe(gulp.dest('dist/css/'));
});js压缩合并的过程大同小异,增加了一个jshint()代码审查的过程,它会将不符合规范的错误代码输出到控制台。
gulp.task('dist:js', () => {
gulp.src('dist/js/*.js').pipe(clean());
return gulp.src('./src/js/*.js')
.pipe(jshint())
.pipe(jshint.reporter('default'))
.pipe(uglify())
.pipe(concat('public.js'))
.pipe(gulp.dest('dist/js/'))
});在开发过程中,因为html不能直接引入.less文件,因此还需要生成开发环境的.css。
gulp.task('src:css', () => {
gulp.src('src/css/*.css').pipe(clean());
return gulp.src('./src/less/*.less')
.pipe(less())
.pipe(gulp.dest('src/css/'));
});为了防止浏览器对文件进行缓存,需要对文件添加版本号,保证每次获取到的都是最新的代码。
gulp.task('revision', ['dist:css', 'dist:js'], () => {
return gulp.src(["dist/css/*.css", "dist/js/*.js"])
.pipe(rev())
.pipe(gulpif('*.css', gulp.dest('dist/css'), gulp.dest('dist/js')))
.pipe(rev.manifest())
.pipe(gulp.dest('dist'))
})
gulp.task('build', ['dist:img'], () => {
var manifest = gulp.src('dist/rev-manifest.json');
return gulp.src('src/index.html')
.pipe(revReplace({
manifest: manifest
}))
.pipe(useref())
.pipe(gulp.dest('dist/'))
})在revision中,首先通过rev()对dist目录下的.css/.js生成一个文件名带版本号的文件,例如本例中public.css生成public-5c001c53f6.css,然后分别输出到不同的目录下,最后生成一个rev-manifest.json文件,存储了原文件和带版本号文件之间的映射关系,如下:
{
"public.css": "public-5c001c53f6.css",
"public.js": "public-93c275a836.js"
}在build中,先获取到rev-manifest.json中的对象,然后利用revReplace()来替换版本号,再使用useref()来进行资源的解析定位,最后输出即可。
以引入js文件为例,源html文件中对文件的引入则要改写为以下形式,即以注释的形式写入构建后生成的文件路径,如下:
<!-- build:js ./js/public.js -->
<script src="./js/jquery-1.12.4.min.js"></script>
<script src="./js/myAlbum.js"></script>
<!-- endbuild -->最后生成的html为:
<script src="./js/public-93c275a836.js"></script>具体的语法规则可以参见gulp-useref。
使用connet.server()来创建一个本地服务器,利用gulp.watch()来对src下的文件进行监测,如果发生变化,则执行编译less为css和刷新页面的任务。
gulp.task('connect', () => {
connect.server({
root: 'src',
livereload: true,
port: 8888
})
})
gulp.task('reload', () => {
gulp.src('src/*.html')
.pipe(connect.reload())
})
gulp.task('watch', () => {
gulp.watch('src/**/*', ['src:css', 'reload'])
})完整的代码可以参见github
VSCode 是一个轻量级的 IDE,许多功能都是依靠插件来进行支持的,这里介绍一些常见好用的 VSCode 插件,帮助大家提升开发体验和效率~
【JavaScript (ES6) code snippets】 JS 代码片段,e.g.
console.log()setTimeOut(() => {})【React-Native/React/Redux snippets for es6/es7】 React 代码片段,e.g.
import React from 'react';import React, { Component } from 'react';【React Hooks Snippets】hooks 代码片段,例如
const [, set] = useState()【Vue VSCode Snippets】Vue 代码片段,e.g.
<template>
<div>
</div>
</template>
<script>
export default {
}
</script>
<style lang="scss" scoped>
</style>"editor.codeActionsOnSave": {
"source.fixAll.eslint": true
}v0.2.12 只支持 js/ts,vue 中无法使用注册事件有好几种方法,每种方法或多或少都有一些不足之处,这里讲一下如何处理注册事件的兼容性问题
一般来说,注册事件有以下三种方法:
ele.on 事件类型这个注册事件的方法兼容性最好,但是无法为同一个元素绑定多个相同的事件,后面注册的会覆盖掉之前注册的
addEventlistener
这个支持为同一元素绑定多个相同事件,但只有高版本的浏览器支持,对于IE来说 IE9+ 才支持。
attachEvent
它也支持为同一元素绑定多个相同事件,是早期IE浏览器的一个专有的替代性标准,用于替代 addEventlistener ,在IE6 thru 10中支持(IE11中不再支持)。
提到事件,就离不开事件的捕获和冒泡,对于一个事件的触发,存在三个阶段:捕获、目标、冒泡:
而在IE和低版本的Opera中(使用attachEvent来注册事件)是不支持事件捕获的,只支持事件冒泡。
一般的标准浏览器对于捕获和冒泡则都支持,使用addEventListener中可选的参数useCaptrue来控制使用哪种传递机制。
useCaptrue 是 addEventListener 方法中可选的参数,是一个 Boolean 类型的值,MDN上对其解释如下:
Boolean,是指在DOM树中,注册了该listener的元素,是否会先于它下方的任何事件目标,接收到该事件。沿着DOM树向上冒泡的事件不会触发被指定为use capture(也就是设为true)的listener。当一个元素嵌套了另一个元素,两个元素都对同一个事件注册了一个处理函数时,所发生的事件冒泡和事件捕获是两种不同的事件传播方式。事件传播模式决定了元素以哪个顺序接收事件。
简单来说,点击element2,当参数为 true 时,事件在捕获阶段触发,冒泡阶段不触发。先触发element1.onclick,再触发element2.onclick。
当参数为 false(默认值)时,事件在冒泡阶段触发,捕获阶段不触发。先触发element2.onclick,再触发element1.onclick。
如何实现注册事件的兼容性处理?这里以一个div为例。
window.onload = function() {
var div = document.getElementsByTagName('div')[0];
if(div.addEventListener) {
div.addEventListener('click', function() {
alert('Hello!');
});
}else if(div.attachEvent) {
div.attachEvent('onclick', function() {
alert('Hello!');
});
}else{
div['onclick'] = function () {
alert('Hello!');
}
}
}这样就实现了兼容性处理,但是它也存在一定的问题:复用性太差。
经过改进后,可以提高代码的复用性,如下:
//target是目标元素、type是绑定事件的类型、handler的回调函数
function registerEvent(target, type, handler) {
if(target.addEventListener) {
target.addEventListener(type, handler);
}else if(target.attachEvent) {
target.attachEvent('on' + type, handler);
}else{
target['on' + type] = handler;
}
}
window.onload = function() {
var div = document.getElementsByTagName('div')[0];
registerEvent(div, 'click', function() {
alert('Hello!');
});
}这里实现了封装,有了一定的复用性,但还有改进的空间:每次调用时都需要判断,可以进一步改进,使其只需要判断一次即可。
这里可以使用闭包的相关知识,返回一个注册事件的函数,这样就实现了只需判断一次,减少了代码的判断次数,如下:
function createEventRegister() {
if(window.addEventListener) {
return function(target, type, handler) {
target.addEventListener(type, handler);
}
}else if(window.attachEvent) {
return function(target, type, handler) {
target.attachEvent('on' + type, handler);
}
}else {
return function(target, type, handler) {
target['on' + type] = handler;
}
}
}
var registerEvent = createEventRegister();
window.onload = function() {
var div = document.getElementsByTagName('div')[0];
registerEvent(div, 'click', function() {
alert('Hello!');
});
}这样写可以说是非常nice了,可还是有一点小问题:关于 this 对象和 event 对象
关于 this 对象,有如下代码:
window.onload = function() {
var div = document.getElementsByTagName('div')[0];
registerEvent(div, 'click', function() {
console.log(this);
alert('Hello!');
});
}通过输出的结果可以看到,注册事件的处理函数中 this 指向不一致:
target,即注册事件的目标对象;window;target。
要解决这个问题,就要使函数中 this 指向一致,可以使用apply或call方法来为回调函数指定 this,使其指向 target,attachEvent部分修改如下:
//...
else if(window.attachEvent) {
return function(target, type, handler) {
target.attachEvent('on' + type, function() {
handler.call(target);
});
}
}
//...关于event对象,回调函数中获取事件对象的方式不一致:
前面提到过标准浏览器中获取事件对象使用的是传递参数的方法,而IE中则是使用window.event,那么这里为了统一获取event对象的方法,将window.event作为参数传递进去,attachEvent 修改如下:
//...
else if(window.attachEvent) {
return function(target, type, handler) {
target.attachEvent('on' + type, function() {
handler.call(target, window.event);
});
}
}
//...综合以上几点,最终封装的代码如下,可以统一调用 this 对象和 event 对象:
function createEventRegister() {
if(window.addEventListener) {
return function(target, type, handler) {
target.addEventListener(type, handler);
}
}else if(window.attachEvent) {
return function(target, type, handler) {
target.attachEvent('on' + type, function() {
handler.call(target, window.event);
});
}
}else {
return function(target, type, handler) {
target['on' + type] = handler;
}
}
}promise 是 ES6 中新增的一种异步解决方案,在日常开发中也经常能看见它的身影,例如原生的 fetch API 就是基于 promise 实现的。那么 promise 有哪些特性,如何实现一个具有 promise/A+ 规范的 promise 呢?
首先我们整理一下 promise 的一些基本特性和 API,完整的 promise/A+ 规范可以参考 【翻译】Promises/A+规范
接下来我们逐步实现一个具有 promise/A+ 规范的 promise
先定义一个常量,表示 promise 的三个状态
const STATE = {
PENDING: 'pending',
FULFILLED: 'fulfilled',
REJECTED: 'rejected'
}然后在 promise 中初始化两个参数 value 和 reason,分别表示状态为 fulfill 和 reject 时的值,接着定义两个函数,函数内部更新状态以及相应的字段值,分别在成功和失败的时候执行,然后将这两个函数传入构造函数的函数参数中,如下:
class MyPromise {
constructor(fn) {
// 初始化
this.state = STATE.PENDING
this.value = null
this.reason = null
// 成功
const fulfill = (value) => {
// 只有 state 为 pending 时,才可以更改状态
if (this.state === STATE.PENDING) {
this.state = STATE.FULFILLED
this.value = value
}
}
// 失败
const reject = (reason) => {
if (this.state === STATE.PENDING) {
this.state = STATE.REJECTED
this.reason = reason
}
}
// 执行函数出错时调用 reject
try {
fn(fulfill, reject)
} catch (e) {
reject(e)
}
}
}接下来初步实现一个 then 方法,当当前状态是 fulfulled 时,执行成功回调,当前状态为 rejected 时,执行失败回调:
class MyPromise {
constructor(fn) {
//...
}
then(onFulfilled, onRejected) {
if (this.state === STATE.FULFILLED) {
onFulfilled(this.value)
}
if (this.state === STATE.REJECTED) {
onRejected(this.reason)
}
}
}这个时候一个简单的 MyPromise 就实现了,但是此时它还只能处理同步任务,对于异步操作却无能为力
要想处理异步操作,可以利用队列的特性,将回调函数先缓存起来,等到异步操作的结果返回之后,再去执行相应的回调函数。
具体实现来看,在 then 方法中增加判断,若为 pending 状态,将传入的函数写入对应的回调函数队列;在初始化 promise 时利用两个数组分别保存成功和失败的回调函数队列,并在 fulfill 和 reject 回调中增加它们。如下:
class MyPromise {
constructor(fn) {
// 初始化
this.state = STATE.PENDING
this.value = null
this.reason = null
// 保存数组
this.fulfilledCallbacks = []
this.rejectedCallbacks = []
// 成功
const fulfill = (value) => {
// 只有 state 为 pending 时,才可以更改状态
if (this.state === STATE.PENDING) {
this.state = STATE.FULFILLED
this.value = value
this.fulfilledCallbacks.forEach(cb => cb())
}
}
// 失败
const reject = (reason) => {
if (this.state === STATE.PENDING) {
this.state = STATE.REJECTED
this.reason = reason
this.rejectedCallbacks.forEach(cb => cb())
}
}
// 执行函数出错时调用 reject
try {
fn(fulfill, reject)
} catch (e) {
reject(e)
}
}
then(onFulfilled, onRejected) {
if (this.state === STATE.FULFILLED) {
onFulfilled(this.value)
}
if (this.state === STATE.REJECTED) {
onRejected(this.reason)
}
// 当 then 是 pending 时,将这两个状态写入数组中
if (this.state === STATE.PENDING) {
this.fulfilledCallbacks.push(() => {
onFulfilled(this.value)
})
this.rejectedCallbacks.push(() => {
onRejected(this.reason)
})
}
}
}接下来对 MyPromise 进行进一步改造,使其能够支持链式调用,使用过 jquery 等库应该对于链式调用非常熟悉,它的原理就是调用者返回它本身,在这里的话就是要让 then 方法返回一个 promise 即可,还有一点就是对于返回值的传递:
class MyPromise {
constructor(fn) {
//...
}
then(onFulfilled, onRejected) {
return new MyPromise((fulfill, reject) => {
if (this.state === STATE.FULFILLED) {
// 将返回值传入下一个 fulfill 中
fulfill(onFulfilled(this.value))
}
if (this.state === STATE.REJECTED) {
// 将返回值传入下一个 reject 中
reject(onRejected(this.reason))
}
// 当 then 是 pending 时,将这两个状态写入数组中
if (this.state === STATE.PENDING) {
this.fulfilledCallbacks.push(() => {
fulfill(onFulfilled(this.value))
})
this.rejectedCallbacks.push(() => {
reject(onRejected(this.reason))
})
}
})
}
}实现到这一步的 MyPromise 已经可以支持异步操作、链式调用、传递返回值,算是一个简易版的 promise,一般来说面试时需要手写一个 promise 时,到这个程度就足够了,完整实现 promise/A+ 规范在面试这样一个较短的时间内也不太现实。
到这一步的完整代码可以参考 promise3.js
promise/A+ 规范中规定,onFulfilled/onRejected 返回一个值 x,对 x 需要作以下处理:
TypeError 错误Promise ,则保持 then 方法返回的 promise 的值与 x 的值一致x.then 赋值给 then 并调用
then 是一个函数,则将 x 作为作用域 this 调用,并传递两个参数 resolvePromise 和 rejectPromise,如果 resolvePromise 和 rejectPromise 均被调用或者被调用多次,则采用首次调用并忽略剩余调用then 方法出错,则以抛出的错误 e 为拒因拒绝 promisethen 不是函数,则以 x 为参数执行 promise接下来对上一步实现的 MyPromise 进行进一步优化,使其符合 promise/A+ 规范:
class MyPromise {
constructor(fn) {
//...
}
then(onFulfilled, onRejected) {
const promise2 = new MyPromise((fulfill, reject) => {
if (this.state === STATE.FULFILLED) {
try {
const x = onFulfilled(this.value)
generatePromise(promise2, x, fulfill, reject)
} catch (e) {
reject(e)
}
}
if (this.state === STATE.REJECTED) {
try {
const x = onRejected(this.reason)
generatePromise(promise2, x, fulfill, reject)
} catch (e) {
reject(e)
}
}
// 当 then 是 pending 时,将这两个状态写入数组中
if (this.state === STATE.PENDING) {
this.fulfilledCallbacks.push(() => {
try {
const x = onFulfilled(this.value)
generatePromise(promise2, x, fulfill, reject)
} catch(e) {
reject(e)
}
})
this.rejectedCallbacks.push(() => {
try {
const x = onRejected(this.reason)
generatePromise(promise2, x, fulfill, reject)
} catch (e) {
reject(e)
}
})
}
})
return promise2
}
}这里将处理返回值 x 的行为封装成为了一个函数 generatePromise,实现如下:
const generatePromise = (promise2, x, fulfill, reject) => {
if (promise2 === x) {
return reject(new TypeError('Chaining cycle detected for promise'))
}
// 如果 x 是 promise,调用它的 then 方法继续遍历
if (x instanceof MyPromise) {
x.then((value) => {
generatePromise(promise2, value, fulfill, reject)
}, (e) => {
reject(e)
})
} else if (x != null && (typeof x === 'object' || typeof x === 'function')) {
// 防止重复调用,成功和失败只能调用一次
let called;
// 如果 x 是对象或函数
try {
const then = x.then
if (typeof then === 'function') {
then.call(x, (y) => {
if (called) return;
called = true;
// 说明 y是 promise,继续遍历
generatePromise(promise2, y, fulfill, reject)
}, (r) => {
if (called) return;
called = true;
reject(r)
})
} else {
fulfill(x)
}
} catch(e) {
if (called) return
called = true
reject(e)
}
} else {
fulfill(x)
}
}promise/A+ 规范中还规定,对于 promise2 = promise1.then(onFulfilled, onRejected)
对于 then 方法做最后的完善,增加 setTimeout 模拟异步调用,增加对于 onFulfilled 和 onRejected 方法的判断:
class MyPromise {
constructor(fn) {
//...
}
then(onFulfilled, onRejected) {
// 处理 onFulfilled 和 onRejected
onFulfilled = typeof onFulfilled === 'function' ? onFulfilled : value => value
onRejected = typeof onRejected === 'function' ? onRejected : e => { throw e }
const promise2 = new MyPromise((fulfill, reject) => {
// setTimeout 宏任务,确保onFulfilled 和 onRejected 异步执行
if (this.state === STATE.FULFILLED) {
setTimeout(() => {
try {
const x = onFulfilled(this.value)
generatePromise(promise2, x, fulfill, reject)
} catch (e) {
reject(e)
}
}, 0)
}
if (this.state === STATE.REJECTED) {
setTimeout(() => {
try {
const x = onRejected(this.reason)
generatePromise(promise2, x, fulfill, reject)
} catch (e) {
reject(e)
}
}, 0)
}
// 当 then 是 pending 时,将这两个状态写入数组中
if (this.state === STATE.PENDING) {
this.fulfilledCallbacks.push(() => {
setTimeout(() => {
try {
const x = onFulfilled(this.value)
generatePromise(promise2, x, fulfill, reject)
} catch(e) {
reject(e)
}
}, 0)
})
this.rejectedCallbacks.push(() => {
setTimeout(() => {
try {
const x = onRejected(this.reason)
generatePromise(promise2, x, fulfill, reject)
} catch (e) {
reject(e)
}
}, 0)
})
}
})
return promise2
}
}实现 promise/A+ 规范的 promise 完整代码可以参考 promise4.js
如何知道你实现的 promise 是否遵循 promise/A+ 规范呢?可以利用 promises-aplus-tests 这样一个 npm 包来进行相应测试
这里对其他常用的 promise API 进行了实现
class MyPromise {
constructor(fn) {
//...
}
then(onFulfilled, onRejected) {
//...
}
catch(onRejected) {
return this.then(null, onRejected)
}
finally(callback) {
return this.then(callback, callback)
}
}返回一个 resolved 状态的 Promise 对象
MyPromise.resolve = (value) => {
// 传入 promise 类型直接返回
if (value instanceof MyPromise) return value
// 传入 thenable 对象时,立即执行 then 方法
if (value !== null && typeof value === 'object') {
const then = value.then
if (then && typeof then === 'function') return new MyPromise(value.then)
}
return new MyPromise((resolve) => {
resolve(value)
})
}返回一个 rejected 状态的 Promise 对象
MyPromise.reject = (reason) => {
// 传入 promise 类型直接返回
if (reason instanceof MyPromise) return reason
return new MyPromise((resolve, reject) => {
reject(reason)
})
}返回一个 promise,一旦迭代器中的某个 promise 状态改变,返回的 promise 状态随之改变
MyPromise.race = (promises) => {
return new MyPromise((resolve, reject) => {
// promises 可以不是数组,但必须存在 Iterator 接口,因此采用 for...of 遍历
for(let promise of promises) {
// 如果当前值不是 Promise,通过 resolve 方法转为 promise
if (promise instanceof MyPromise) {
promise.then(resolve, reject)
} else {
MyPromise.resolve(promise).then(resolve, reject)
}
}
})
}返回一个 promise,只有迭代器中的所有的 promise 均变为 fulfilled,返回的 promise 才变为 fulfilled,迭代器中出现一个 rejected,返回的 promise 变为 rejected
MyPromise.all = (promises) => {
return new MyPromise((resolve, reject) => {
const arr = []
// 已返回数
let count = 0
// 当前索引
let index = 0
// promises 可以不是数组,但必须存在 Iterator 接口,因此采用 for...of 遍历
for(let promise of promises) {
// 如果当前值不是 Promise,通过 resolve 方法转为 promise
if (!(promise instanceof MyPromise)) {
promise = MyPromise.resolve(promise)
}
// 使用闭包保证异步返回数组顺序
((i) => {
promise.then((value) => {
arr[i] = value
count += 1
if (count === promises.length || count === promises.size) {
resolve(arr)
}
}, reject)
})(index)
// index 递增
index += 1
}
})
}只有等到迭代器中所有的 promise 都返回,才会返回一个 fulfilled 状态的 promise,并且返回的 promise 状态总是 fulfilled,不会返回 rejected 状态
MyPromise.allSettled = (promises) => {
return new MyPromise((resolve, reject) => {
const arr = []
// 已返回数
let count = 0
// 当前索引
let index = 0
// promises 可以不是数组,但必须存在 Iterator 接口,因此采用 for...of 遍历
for(let promise of promises) {
// 如果当前值不是 Promise,通过 resolve 方法转为 promise
if (!(promise instanceof MyPromise)) {
promise = MyPromise.resolve(promise)
}
// 使用闭包保证异步返回数组顺序
((i) => {
promise.then((value) => {
arr[i] = value
count += 1
if (count === promises.length || count === promises.size) {
resolve(arr)
}
}, (err) => {
arr[i] = err
count += 1
if (count === promises.length || count === promises.size) {
resolve(arr)
}
})
})(index)
// index 递增
index += 1
}
})
}本文如有错误,欢迎批评指正~
参考
本文主要归纳 macOS 下一些常见 Terminal 相关的软件配置,快速搭建本地开发环境,大部分内容已收纳至 dotfiles 项目中,开箱即用,欢迎体验。
HomeBrew 是 macOS 下的包管理工具,后续的其他软件包都会通过 HomeBrew 来安装,它类似于 Debian 下的 apt、CentOS 下的 yum,安装命令如下:
# 安装 HomeBrew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# 配置 HomeBrew,安装好之后会提示类似的命令,复制粘贴即可
echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> /Users/your_user_name/.zprofile
eval "$(/opt/homebrew/bin/brew shellenv)"iTerm2 是 macOS 下常用的终端工具,支持主题配置、智能提示、历史记录等等,利用 HomeBrew 进行安装:
brew install --cask iterm2安装好之后可以通过 Preferences 来配置 Colors、Status Bar、Hot Key 等
on-my-zsh 是一款开源工具,用于管理 zsh 配置,它支持丰富的扩展和主题配置,相关配置存储在 ~/.zshrc 中,安装命令如下:
sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"Powerlevel10k 是一款 zsh 中流行的主题包,你可以根据自身喜好决定是否安装,命令如下:
git clone --depth=1 https://github.com/romkatv/powerlevel10k.git ${ZSH_CUSTOM:-$HOME/.oh-my-zsh/custom}/themes/powerlevel10k安装完成后在 .zshrc 中更改主题设置:
ZSH_THEME="powerlevel10k/powerlevel10k"
然后重启终端,跟随引导进行设置就可以应用了,如果设置好之后想要修改,可以通过以下命令重新唤起配置引导:
p10k configure配置好之后在 VSCode 的终端中会出现配置的 icon 丢失的情况,需要在 terminal.integrated.fontFamily 中设置字体为:MesloLGS NF,其他更详细的字体相关的问题可以参考:powerlevel10k/font
当你在终端中进行输入时,zsh-autosuggestions 可以帮你根据历史记录和自动补全进行提示,大大提高了效率:
git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions下载完成后在 .zshrc 中添加这个扩展:
plugins=(
# other plugins...
zsh-autosuggestions
)nvm 是一款优秀的 NodeJS 版本管理工具,通过它你可以轻松地管理本地的 NodeJS 版本:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.1/install.sh | bash 因为个人使用的 Alfred workflow 的部分插件依赖于 php 运行时,而 macOS 在 12 Monterey 版本之后不再默认安装 php,因此需要手动安装,相关命令如下:
brew install [email protected]然后配置 php 命令:
brew link [email protected]至此,大部分 Terminal 所需软件包安装完成,可以开始愉快的 coding 了~
2022 年了,如何快速从零开始搭建一个合适的前端项目?
首先本地需要安装好 node 环境以及包管理工具,推荐直接使用 pnpm,也可以通过 pnpm 来直接管理 nodejs 版本。
pnpm 安装:
# Mac or Linux
curl -fsSL https://get.pnpm.io/install.sh | sh -
# Windows
iwr https://get.pnpm.io/install.ps1 -useb | iex使用 pnpm 安装 nodejs 的 LTS 版本:
pnpm env use --global lts这里我们以搭建一个 React + TypeScript 项目为例
脚手架方面,新项目可以考虑直接使用 vite,我们通过以下命令创建一个基于 vite 的初始化项目:
pnpm create vite my-react-app --template react-ts进入目录可以看到如下的结构:
.
├── public
├── src
├── index.html
├── package.json
├── tsconfig.json
├── tsconfig.node.json
└── vite.config.ts
ESLint 可以通过静态分析,来审查你代码中的错误,对于前端项目也是不可或缺的存在,这里我们选择社区比较流行的 airbnb 风格的 ESLint 规则,通过以下命令安装基础的配置与插件:
pnpm add eslint eslint-config-airbnb-base eslint-plugin-import -D 然后在项目根目录中添加 .eslintrc.json 文件:
{
"extends": [
"eslint:recommended",
"airbnb-base",
],
"plugins": [
"import"
],
}对于 TypeScript 以及 React 项目,还需要额外的 parser 和 plugin 来支持:
# TypeScirpt eslint parser
pnpm add @typescript-eslint/parser @typescript-eslint/eslint-plugin -D
# React eslint plugin
pnpm add eslint-plugin-react eslint-plugin-react-hooks -D在 .eslintrc.json 文件中添加相应的规则:
{
"extends": [
"eslint:recommended",
"airbnb-base",
"plugin:react/recommended",
"plugin:react/jsx-runtime",
"plugin:react-hooks/recommended",
"plugin:@typescript-eslint/eslint-recommended",
"plugin:@typescript-eslint/recommended"
],
"plugins": [
"import",
"@typescript-eslint",
"react",
],
"parser": "@typescript-eslint/parser",
}最后在 package.json 中添加对应的 scripts 就大功告成了:
{
"scripts": {
"lint": "eslint --fix --quiet --ext .ts,.tsx src"
}
}prettier 是一个代码格式化工具,可以通过它来实现代码缩进、空行等排版风格的统一,通过以下命令进行安装:
pnpm add prettier -D然后在根目录中添加 .prettierrc.json 配置文件:
{
"printWidth": 80,
"tabWidth": 2,
"semi": true,
"singleQuote": true
}我们可以通过 prettier 的 ESLint 插件来实现检查 ESLint 规则时也同步检查 prettier 代码风格的规则:
pnpm add eslint-plugin-prettier eslint-config-prettier -D安装后在 .eslintrc.json 中添加相应配置,注意需要设置 prettier/prettier 相关规则为 error:
{
"extends": [
"eslint:recommended",
"airbnb-base",
"plugin:react/recommended",
"plugin:react/jsx-runtime",
"plugin:react-hooks/recommended",
"plugin:@typescript-eslint/eslint-recommended",
"plugin:@typescript-eslint/recommended",
"prettier"
],
"plugins": [
"import",
"@typescript-eslint",
"react",
"prettier"
],
"parser": "@typescript-eslint/parser",
"rules": {
"prettier/prettier": "error",
}
}配置好 ESLint 和 prettier 之后,你需要一个工作流来触发 lint 的相关检查,这里我们选择比较常用的 husky + lint-staged 的组合:
pnpm add husky lint-staged -D在根目录的 package.json 中添加对应的配置:
{
"lint-staged": {
"**/*.{ts,tsx}": [
"eslint --fix --quiet",
"prettier --write",
"git add"
]
}
}它会在匹配到 .ts/.tsx 后缀的文件时去执行 ESLint 和 prettier 的修复工作。
你还需要在 .husky 中添加 precommit 文件来触发 lint-staged 的这个行为:
#!/bin/sh
. "$(dirname "$0")/_/husky.sh"
npx lint-staged最后在 package.json 的 scripts 中添加 husky 的初始化脚本,来保证上述钩子能够正常触发:
{
"scripts": {
"prepare": "husky install"
}
}顺利的话,通过以上配置,你在每次进行 commit 之后都会由 husky 触发 precommit 钩子并由 lint-staged 来匹配文件规则,执行相应的 lint 检查与修复。
单元测试是项目开发中比较重要的一部分,通过单元测试可以一定程度上保障项目的代码质量以及逻辑的完整性,对于 vite 创建的项目,我们选择与之匹配度比较高的测试框架 vitest 来编写测试用例,安装如下:
pnpm create vitest jsdom -D在 vite.config.ts 中配置 vitest,选择 js-dom 环境,这里在顶部添加 vitest 的类型声明引入后,即可在 vitest **享 vite 的 plugins 等配置,无需配置 vitest.config.ts 文件:
/// <reference types="vitest" />
import { defineConfig } from 'vite';
import react from '@vitejs/plugin-react';
export default defineConfig({
plugins: [react()],
test: {
testTimeout: 20000,
environment: 'jsdom',
},
});一个使用 @testing-library/react 编写的测试用例的简单例子可以参考:react-typescript
CI 则是项目自动化中比较重要的一环,通过 CI 可以帮助你自动执行一些任务,我们以 github 为例,这里配置一个 CI 相关的 workflow, 它的主要功能是在你 push/pull_request 代码到 github 时,自动执行相关的 ESLint 检查、TypeScript 类型检查以及对测试用例的执行。
首先我们在根目录新建 .github/workflows 文件夹,然后创建一个 ci.yml 文件,主要内容为:
name: CI
on:
push:
branches:
- main
pull_request:
branches:
- main
jobs:
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set node v14
uses: actions/setup-node@v3
with:
node-version: '14'
- name: Install
run: npm install
- name: Lint
run: npm run lint
typecheck:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set node v14
uses: actions/setup-node@v3
with:
node-version: '14'
- name: Install
run: npm install
- name: Typecheck
run: npm run typecheck
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set node v14
uses: actions/setup-node@v3
with:
node-version: '14'
- name: Install
run: npm install
- name: Build
run: npm run test这里我们创建了三个 job:lint/typecheck/test,它们在触发了 push/pull_request 操作后会分别自动执行 scripts 中的 lint/typecheck/test 命令,其中 typecheck 前面没有写,主要内容其实就是 tsc
对于现在的前端项目而言,上述 TypeScript 以及 eslint、prettier、husky 等基本上属于标配了,但每次创建一个新项目都需要重新进行这样的一系列配置也比较耗费时间,因此我开发了一个小项目,可以帮助你快速创建一个配置好以上内容的项目,只需要一行代码:
pnpm create @tooltik/cap my-cap-app --template react-ts左侧固定宽度,右侧自适应的布局在网页中比较常见,像一些文档或者是后台管理系统都是这样的布局,那么实现它的方法有哪些呢?这里我归纳总结了以下七种方法实现这一布局
页面dom结构如下:
<div class="box">
<div class="aside"></div>
<div class="main"></div>
</div>基础的css样式:
body {
padding: 0;
margin: 0;
}
.aside {
width: 300px;
height: 200px;
}
.main {
height: 200px;
}那么要实现左侧定宽(300px)右侧自适应的布局效果,有以下七种方法:
.aside {
float: left;
}
.main {
margin-left: 300px;
}方法很简单,但确实实现了这个效果。
.aside {
float: left;
}
.main {
overflow: auto;
}左侧盒子浮动,右侧利用overflow: auto形成了BFC,因此右侧盒子不会与左侧盒子重叠。
.box {
position: relative;
}
.aside {
position: absolute;
left: 0;
}
.main {
margin-left: 300px;
}常见的方法之一。
.aside {
float: left;
}
.main {
float: left;
width: calc(100% - 300px);
}让左右两个盒子都浮动,然后给通过动态计算宽度使右侧自适应。
.aside {
display: inline-block;
}
.main {
display: inline-block;
width: calc(100% - 300px);
}设置两个盒子为行内块元素,同样通过动态计算宽度使右侧自适应。
.box {
display: flex;
}
.main {
flex: 1;
}设置父盒子为flex布局,然后让右侧自动占满剩余宽度。
.box {
display: grid;
grid-template-columns: 300px 1fr;
}设置父元素为grid,第二个网格的自动占满剩余宽度。
经常逛某宝可以发现,查看商品时都有如下的放大功能,鼠标放到图片上可以看到图片的细节,那么它是如何实现的呢?是真的将图片放大了吗?这篇文章就是讲述这个放大器是如何实现的
放大器其实并不是真的将图片放大了。
假如是原图片放大,那么放大后势必会出现一定程度的模糊,而我们平时所看到的,放大后反而更清晰了。所以这两张图并不相同,一个是缩略图,另一个则是前者的高清放大版。
当鼠标放在左侧盒子上时,使遮罩和右侧“放大“图片显示,鼠标移动,带着遮罩随之移动,并使右侧图片等比例进行相应移动,显示出对应的放大后的 局部位置。
当遮罩层向下移动的时候,这个时候大图等比例向上移动,就会显示对应的局部放大区域。然后把溢出的部分隐藏即可达到放大效果。
demo:
要实现上面demo中的放大器,首先你得准备两张图,一张正常大小,另一张高清放大版。
html结构比较简单:
<div class="box1">
<img src="./Images/small.jpg">
<div class="mask"></div>
</div>
<div class="box2">
<img src="./Images/big.jpg">
</div>css部分就不给出了,无非是给盒子设宽高,调一下边距什么的,这里只注意一点:
什么意思呢?
要使放大的区域与左侧遮盖的区域一样,那么左右宽高需要保持相同的比例,相信这一点不难理解。
在这里,遮罩宽高为200px,缩略图为400px,显示区域为450px,原图为900px(上图所画原图大小仅做参考)
以宽为例:
遮盖的宽 / 缩略图的宽 = 显示区域的宽 / 原图的宽。
样式设置好了,宽高也就位了,怎么让图片动起来呢?
代码如下:
box1.onmousemove = function(event) {
//...
var x = event.pageX - box1.offsetLeft - mask.offsetWidth/2;
var y = event.pageY - box1.offsetTop - mask.offsetHeight/2;
//...
}用 event.pageX减去box1.offsetLeft再减去遮罩的半宽,就得到遮罩的左侧与盒子间的距离,如下图:
(坐标相关可以参考:JS坐标获取)
再对x进行约束,使遮罩无法移出边框,最后将x赋值给left:
//..
mask.style.left = x + "px";
mask.style.top = y + "px";
//...这样每次鼠标移动就会更新遮罩的left、top值,使得遮罩移动起来。
先求得小图和大图的比例关系,再乘上x就是大图要移动的距离。
//...
var scale = box2.offsetHeight/mask.offsetHeight;
var xx = x*scale;
var yy = y*scale;
img.style.marginLeft = -xx + "px";
img.style.marginTop = -yy + "px";这样这个放大器就基本实现了,当鼠标移动时,遮罩跟随移动,同时右侧大图等比例移动,达到放大的效果。
CSS Grid 是创建网格布局强大的工具,在2017年,已获得主流浏览器的原生支持(Chrome,Firefox,Edge,Safiri),这篇博客带你快速上手 Grid 布局
在前端领域,提到某个新技术,想在实际开发中使用它,就不得不考虑兼容性问题,目前 Grid 布局在各大主流浏览器已实现支持,如下:
这里是一个网格布局,由父元素container和若干子元素item组成
<div class="container">
<div class="item">1</div>
<div class="item">2</div>
<div class="item">3</div>
<div class="item">4</div>
<div class="item">5</div>
<div class="item">6</div>
</div>要想将其变为网格布局,需要给container设置display: grid属性,然后使用grid-template-row和grid-template-column属性来定义行和列。
.container {
display: grid;
grid-template-columns: 150px 200px 250px;
grid-template-rows: 150px 100px;
}得到的效果如下:
给grid-template-columns设置了三个值,因此得到了三列,给grid-template-rows设置了两个值,因此得到了两行。
这两个属性还可以取以下值:
举个栗子
.container {
display: grid;
grid-template-columns: 150px auto 150px;
grid-template-rows: 150px 100px;
}可以看到,第二列将剩余空间全部占满。结果如下:
再看这个
.container {
display: grid;
grid-template-columns: 1fr 1fr 150px;
grid-template-rows: 150px 100px;
}第一列和第二列均为 1fr,因此他们将等分 150px 以外的宽度。
如果有重复项,可以利用repeat()简化,上面的例子还可以写成这样:
.container {
display: grid;
grid-template-columns: repeat(2, 1fr) 150px;
grid-template-rows: 150px 100px;
}要想调整 item 的大小,可以使用grid-column和grid-row来设置:
.container {
display: grid;
grid-template-columns: 200px 150px 100px;
grid-template-rows: 200px 150px 100px;
}
.item:nth-child(1) {
grid-column-start: 1;
grid-column-end: 4;
}这里设置了一个 3x3 的布局,页面只显示了6个的原因是我们只有6个item来填充这个网格,假如我们再加一个item元素,那么右下角的空白将会被填满。
这里我们让第一个 item 从第一根网格线开始,到第四根网格线结束,因此它将占据一整行。至于为什么三个网格会有四根网格线,看下图你就明白了:
上面的代码还可以这样简写:
.item:nth-child(1) {
grid-column: 1/4;
}下面我们来实践一下
.item:nth-child(1) {
grid-column: 1/3;
}
.item:nth-child(2) {
grid-column: 3/4;
grid-row: 1/3;
}
.item:nth-child(3) {
grid-row: 2/4;
}
.item:nth-child(5) {
grid-column: 2/4;
}利用上面的代码,可以轻松得到如下的布局,更多的则需要发挥你的想象力:
如果想让网格之间有一定间隙,Grid 布局提供了一个属性grid-gap,可以指定网格间距,而不需要我们手动添加margin属性。例如在上面的例子中将container属性增加如下两行:
.container {
grid-column-gap: 10px;
grid-row-gap: 10px;
}
将得到这样的结果:
如果 column 和 row 的值一样,可以简写为grid-gap:
.container {
grid-gap: 10px;
}
Grid 很强大,它也远不只我介绍的这些,关于 Grid 更多详细的内容可以关注我后续的文章更新。
对于 Grid 和 Flex 哪个更好这个问题,我的答案是:**结合使用。**Grid 是二维布局,通常用于整个页面的布局规划,Flex 是一维布局,通常用于局部布局,亦或是组件的布局。二者并不冲突,结合使用将更加轻松。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.