Comments (7)
 gitmylo
commented on June 3, 2024
gitmylo
commented on June 3, 2024
Nice, for proper credit, you should create a pull request to https://github.com/gitmylo/Voice-cloning-quantizers, which has an index of voice cloning quantizers. Just add it to the models.json
from bark-voice-cloning-hubert-quantizer.
 junwchina
commented on June 3, 2024
junwchina
commented on June 3, 2024
pr created.
from bark-voice-cloning-hubert-quantizer.
 Maverick1983
commented on June 3, 2024
Maverick1983
commented on June 3, 2024
@junwchina after trained model, how can use for clone voice?
from bark-voice-cloning-hubert-quantizer.
junwchina
commented on June 3, 2024
@junwchina after trained model, how can use for clone voice?
You can use tts-generation-webui to clone and test voice. Remember to replace the qunatizer model to your trained model.
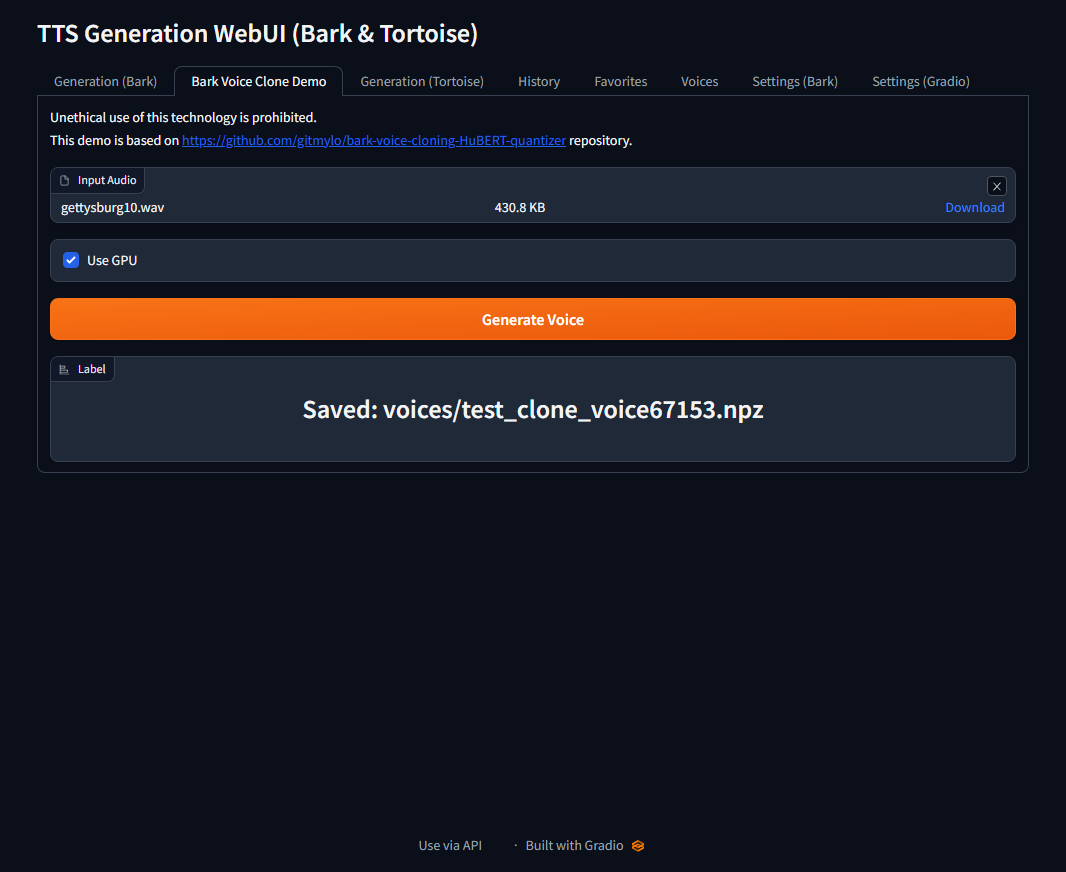
from bark-voice-cloning-hubert-quantizer.
 Naozumi520
commented on June 3, 2024
Naozumi520
commented on June 3, 2024
I'm happy to see we can actually add a new language to bark. Can you please guide me to add an language to it (Cantonese)? I have few issue about this:
-
bark-data-gen generate training data yes. But for unsupported language we cannot use it directly. How did u overcome this issue and use your own dataset to train your Japanese quantizer?
-
How should the dataset looks like?
-
Other steps?
I'll be super grateful if you can help, thank you.
Update: My discord is .naozumi, it'll be easier for me to talk in there!
from bark-voice-cloning-hubert-quantizer.
junwchina
commented on June 3, 2024
bark-data-gen is a tool used to generate training data and train your quantizer model. The models we use to generate training data come from Bark itself, so It should support Chinese/Cantonese very well.
You need to follow these steps:
- Generate semantic data from text(Chinese/Cantonese content).
- Generate wav files from above semantic data.
- Train your Cantonese model from wavs and semantic data. Wav files is input of this model, semantic data is the output.
For more details, you can check my train script .
from bark-voice-cloning-hubert-quantizer.
junwchina
commented on June 3, 2024
I am going to close this issue. It's better to create new issue If you still have other problems.
from bark-voice-cloning-hubert-quantizer.
Related Issues (20)
- Switch fairseq dependency to transformers' Hubert HOT 1
- issues in notebook due to fairseq version HOT 2
- RuntimeError: The size of tensor a (28) must match the size of tensor b (33) at non-singleton dimension 2
- `KeyError: 'best_loss'` when testing self-trained model HOT 2
- HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/GitMylo/bark-voice-cloning/resolve/main/japanese-HuBERT-quantizer_24_epoch.pth HOT 1
- german-HuBERT-quantizer_14_epoch.pth does not have all meta data HOT 2
- Omni-Lingual Quantizer? HOT 1
- adding batches to training?
- Support for Turkish langauge
- No module named 'hubert' HOT 1
- [Question] This notebook it's for create a speark with trained semantic model?
- How To Train Chinese Tokenizer
- How to create a quantizer in a dialect that Bark didn't support? HOT 2
- Request: Write a tutorial for training quantizers
- Added improved functionality and RestAPI
- Stuck on `Installing Demucs`
- How to Train for Non-Verbal Effects Voice? HOT 2
- Torch compile errors on windows 11
- Support for Swahili Language
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from bark-voice-cloning-hubert-quantizer.