Comments (42)
 johnjim0816
commented on May 19, 2024
1
johnjim0816
commented on May 19, 2024
1
在 FrozenLake 演示中,Policy-Iteration 在第 5 步收敛,而 Value-iteration 在迭代 1373 收敛。为什么前者比后者快得多?(In the FrozenLake demo , Policy-Iteration converged at step 5 whereas Value-iteration converged at iteration 1373. Why former is much faster than the latter?)
首先可以肯定的是,一般策略迭代(PI)比值迭代(VI)快得多。个人认为通俗的理解就是,PI每次是在上一次迭代后的策略基础上进行优化的,而VI是一次性的从一开始一直迭代到最优策略,比如在一个大地图上找东西,PI每次学到一点就会运用之前学到的东西也就是以非线性的方式扩大视野再进一步找,而VI则是不断的找最优点(即每次找max的点),每次都是固定的视野范围,需要的迭代次数也更多,也可以参考stackoverflow的回答
from easy-rl.
 Azhe9510
commented on May 19, 2024
Azhe9510
commented on May 19, 2024
在全期望公式下面的证明中 令S_t = s后面 从期望形式展开成两个求和操作的那一步能不能再细说一下
from easy-rl.
 qiwang067
commented on May 19, 2024
qiwang067
commented on May 19, 2024
感谢您的反馈,笔记已更新。
在全期望公式下面的证明中 令S_t = s后面 从期望形式展开成两个求和操作的那一步能不能再细说一下
from easy-rl.
 s-w-c-2
commented on May 19, 2024
s-w-c-2
commented on May 19, 2024
Prediction and Control那边例子Gridworld给的背景是不是有问题,由给的条件一开始理解不了,搜了一下Gridworld,好像条件不大一样
from easy-rl.
qiwang067
commented on May 19, 2024
Prediction and Control那边例子Gridworld给的背景是不是有问题,由给的条件一开始理解不了,搜了一下Gridworld,好像条件不大一样
感谢您的反馈,背景应该是没有问题的,Gridworld 有很多例子,笔记中列出的只是其中一个例子。
from easy-rl.
 nc-yc
commented on May 19, 2024
nc-yc
commented on May 19, 2024
在 FrozenLake 演示中,Policy-Iteration 在第 5 步收敛,而 Value-iteration 在迭代 1373 收敛。为什么前者比后者快得多?(In the FrozenLake demo , Policy-Iteration converged at step 5 whereas Value-iteration converged at iteration 1373. Why former is much faster than the latter?)
from easy-rl.
nc-yc
commented on May 19, 2024
在 FrozenLake 演示中,Policy-Iteration 在第 5 步收敛,而 Value-iteration 在迭代 1373 收敛。为什么前者比后者快得多?(In the FrozenLake demo , Policy-Iteration converged at step 5 whereas Value-iteration converged at iteration 1373. Why former is much faster than the latter?)
首先可以肯定的是,一般策略迭代(PI)比值迭代(VI)快得多。个人认为通俗的理解就是,PI每次是在上一次迭代后的策略基础上进行优化的,而VI是一次性的从一开始一直迭代到最优策略,比如在一个大地图上找东西,PI每次学到一点就会运用之前学到的东西也就是以非线性的方式扩大视野再进一步找,而VI则是不断的找最优点(即每次找max的点),每次都是固定的视野范围,需要的迭代次数也更多,也可以参考stackoverflow的回答
感谢精彩的回答!
from easy-rl.
 jalunli
commented on May 19, 2024
jalunli
commented on May 19, 2024
请问为什么价值函数计算那里是从Rt+1开始的呢?即时奖励的话不应该是Rt吗
from easy-rl.
qiwang067
commented on May 19, 2024
请问为什么价值函数计算那里是从Rt+1开始的呢?即时奖励的话不应该是Rt吗

from easy-rl.
 Strawberry47
commented on May 19, 2024
Strawberry47
commented on May 19, 2024
感谢博主~
from easy-rl.
qiwang067
commented on May 19, 2024
感谢博主~
能对您有所帮助就好,XD
from easy-rl.
Strawberry47
commented on May 19, 2024
我有一个小小的疑问~ RL问题都需要建模为MDP吗?他们俩是什么关系呀?s,a,r,p是属于MDP而非RL的对吗?
from easy-rl.
qiwang067
commented on May 19, 2024
解答见下图:

我有一个小小的疑问~ RL问题都需要建模为MDP吗?他们俩是什么关系呀?s,a,r,p是属于MDP而非RL的对吗?
from easy-rl.
Strawberry47
commented on May 19, 2024
@qiwang067
解答见下图:
我有一个小小的疑问~ RL问题都需要建模为MDP吗?他们俩是什么关系呀?s,a,r,p是属于MDP而非RL的对吗?
谢谢博主的回答~
from easy-rl.
 Amateur-lay
commented on May 19, 2024
Amateur-lay
commented on May 19, 2024
Policy evaluation的例子1表述似乎有一点问题,"现在的奖励函数应该是关于动作以及状态两个变量的一个函数。但我们这里规定,不管你采取什么动作,只要到达状态$$s_1$$,就有 5 的奖励。只要你到达状态
之前笔记中对reward的介绍是$R(s,a)$,只是当前状态s的函数而非$$R(s,s',a)$$即s和$s'$的函数。
而且,按照后面的计算结果和$R$向量的一维性来理解,更符合结果的表述是“只有当前处于状态$s_1$,就有5的奖励,只要当前处于$s_7$,就有10的奖励,与采取任何动作无关”。
不知道我理解的错了没有?
from easy-rl.
qiwang067
commented on May 19, 2024
Policy evaluation的例子1表述似乎有一点问题,"现在的奖励函数应该是关于动作以及状态两个变量的一个函数。但我们这里规定,不管你采取什么动作,只要到达状态s1s_1,就有 5 的奖励。只要你到达状态 s7s_7了,就有 10 的奖励,中间没有任何奖励。"
之前笔记中对reward的介绍是R(s,a)R(s,a),只是当前状态s的函数而非R(s,s′,a)R(s,s',a)即s和s′s'的函数。
而且,按照后面的计算结果和RR向量的一维性来理解,更符合结果的表述是“只有当前处于状态s1s_1,就有5的奖励,只要当前处于s7s_7,就有10的奖励,与采取任何动作无关”。
不知道我理解的错了没有?
Hi,感谢您的反馈,回复见下图:

from easy-rl.
 xx529
commented on May 19, 2024
xx529
commented on May 19, 2024
策略迭代
初始化一个 policy 和 value
用 policy evaluation 方式迭代至 value 收敛
用现在的 policy 和 收敛的 value 去倒推每个 q(s, a) 的值,每个 state 取最大 q 值最大的那个 action 作为 policy
不停重复1~3直到 policy 没有变化
价值迭代
不需要 policy 的参与,初始化 value
每次迭代的 value 就是用即时的奖励加上当前状态执行某一个 action 后的状态的最大 value
最后就看每一个 state 能取最大 value 的 action 作为最终的 policy
policy 生成过程区别
价值迭代过程中没有初始化一个 policy 参与,通过迭代后是最后才生成
策略迭代是一开始就不停迭代提升一个 policy 直到收敛
博主我有理解正确吗?
from easy-rl.
 VZGVainglory
commented on May 19, 2024
VZGVainglory
commented on May 19, 2024
中的
为什么多了个s不是很理解
想知道是怎么变换的
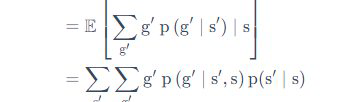
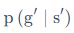
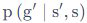
from easy-rl.
 zaoan660
commented on May 19, 2024
zaoan660
commented on May 19, 2024
感谢博主的教程,我收获很多,只是我还有两个问题:
policy iteration 每进行一次 sweep 就使用贪心算法更新一次 policy 就是 value iteration 吗,因为算出来的结果是一样的
一次 policy evaluation 是指更新到价值收敛还是一次 sweep 呀
sweep 词语是我在博主推荐可视化网站看到的就是 'Policy Evaluation (one sweep) '按钮
https://cs.stanford.edu/people/karpathy/reinforcejs/gridworld_dp.html
from easy-rl.
 uncle-yi
commented on May 19, 2024
uncle-yi
commented on May 19, 2024
请问纸质书第62页的价值迭代算法的第(3)步公式是否有误,以我的理解应该在argmax后有一个方括号,且V的下标应该是H,在电子版同一个章节并没有看到对应的内容。如果我的理解有问题,恳请博主指点一下迷津,对这章的数学部分确实有点一知半解的感觉。
from easy-rl.
qiwang067
commented on May 19, 2024
请问纸质书第62页的价值迭代算法的第(3)步公式是否有误,以我的理解应该在argmax后有一个方括号,且V的下标应该是H,在电子版同一个章节并没有看到对应的内容。如果我的理解有问题,恳请博主指点一下迷津,对这章的数学部分确实有点一知半解的感觉。
感谢您的反馈,arg max 后是应该有一个方括号,V 的下标应该是 H+1,具体细节见勘误:
https://datawhalechina.github.io/easy-rl/#/errata
from easy-rl.
 violaBook
commented on May 19, 2024
violaBook
commented on May 19, 2024
您好,Policy Evaluation(Prediction)中的QA里的迭代公式好像漏了\pi的累加?和前面给的公式不同,不知道是不是有问题?
from easy-rl.
qiwang067
commented on May 19, 2024
您好,Policy Evaluation(Prediction)中的QA里的迭代公式好像漏了\pi的累加?和前面给的公式不同,不知道是不是有问题?
@Tricol-Viola 感谢您的反馈,您所提到的迭代公式是状态价值函数 v 的迭代公式,前面给的公式是 Q 函数的迭代公式,这两者不同 : )
from easy-rl.
qiwang067
commented on May 19, 2024
中的
为什么多了个s不是很理解
想知道是怎么变换的
@VZGVainglory 感谢您的反馈,具体推导见下图:

from easy-rl.
qiwang067
commented on May 19, 2024
感谢博主的教程,我收获很多,只是我还有两个问题: policy iteration 每进行一次 sweep 就使用贪心算法更新一次 policy 就是 value iteration 吗,因为算出来的结果是一样的 一次 policy evaluation 是指更新到价值收敛还是一次 sweep 呀
sweep 词语是我在博主推荐可视化网站看到的就是 'Policy Evaluation (one sweep) '按钮 https://cs.stanford.edu/people/karpathy/reinforcejs/gridworld_dp.html
价值迭代做的工作类似于价值的反向传播,每次迭代做一步传播,所以中间过程的策略和价值函数是没有意义的。而策略迭代的每一次迭代的结果都是有意义的,都是一个完整的策略。
一次策略迭代就是一次 sweep。
from easy-rl.
 guoruiqi01
commented on May 19, 2024
guoruiqi01
commented on May 19, 2024
作者好,第二章中好多公式无法正常显示。
from easy-rl.
qiwang067
commented on May 19, 2024
作者好,第二章中好多公式无法正常显示。
@guoruiqi01 感谢您的反馈,公式解析的链接出问题了,我们会尽快修复这个问题,建议您先看 pdf 版:
https://github.com/datawhalechina/easy-rl/releases
from easy-rl.
qiwang067
commented on May 19, 2024
作者好,第二章中好多公式无法正常显示。
@guoruiqi01 感谢您的反馈,公式解析链接已修复。
from easy-rl.
 jzhangCSER01
commented on May 19, 2024
jzhangCSER01
commented on May 19, 2024
感觉这一章好难啊
from easy-rl.
 argb
commented on May 19, 2024
argb
commented on May 19, 2024
每节课没有对应的代码可以跟着实践吗?
from easy-rl.
argb
commented on May 19, 2024
最大的缺点就是缺少配套代码
from easy-rl.
qiwang067
commented on May 19, 2024
每节课没有对应的代码可以跟着实践吗?
有的
from easy-rl.
qiwang067
commented on May 19, 2024
最大的缺点就是缺少配套代码
请查看:
https://github.com/datawhalechina/easy-rl/tree/master/notebooks
from easy-rl.
 nickyi1990
commented on May 19, 2024
nickyi1990
commented on May 19, 2024
2.2.2贝尔曼方程 -> 2.5图下面的矩阵等式的最右侧,不应该是v(s`)么?
from easy-rl.
 Gaben21
commented on May 19, 2024
Gaben21
commented on May 19, 2024
最大的缺点就是缺少配套代码
请查看:
https://github.com/datawhalechina/easy-rl/tree/master/notebooks
您好,可以标注一下代码分别对应书上的哪个章节吗?还有就是代码的注释也有点少,辛苦了
from easy-rl.
qiwang067
commented on May 19, 2024
2.2.2贝尔曼方程 -> 2.5图下面的矩阵等式的最右侧,不应该是v(s`)么?

from easy-rl.
qiwang067
commented on May 19, 2024
最大的缺点就是缺少配套代码
请查看:
https://github.com/datawhalechina/easy-rl/tree/master/notebooks您好,可以标注一下代码分别对应书上的哪个章节吗?还有就是代码的注释也有点少,辛苦了
@Gaben21
内容导航中已增加配套代码,如下图所示:

另外,蘑菇书代码还在迭代中,后续版本会加入更多注释。
from easy-rl.
Gaben21
commented on May 19, 2024
最大的缺点就是缺少配套代码
请查看:
https://github.com/datawhalechina/easy-rl/tree/master/notebooks您好,可以标注一下代码分别对应书上的哪个章节吗?还有就是代码的注释也有点少,辛苦了
@Gaben21
内容导航中已增加配套代码,如下图所示:
另外,蘑菇书代码还在迭代中,后续版本会加入更多注释。
好的,谢谢您
from easy-rl.
qiwang067
commented on May 19, 2024
最大的缺点就是缺少配套代码
请查看:
https://github.com/datawhalechina/easy-rl/tree/master/notebooks您好,可以标注一下代码分别对应书上的哪个章节吗?还有就是代码的注释也有点少,辛苦了
@Gaben21
内容导航中已增加配套代码,如下图所示:
另外,蘑菇书代码还在迭代中,后续版本会加入更多注释。好的,谢谢您
客气啦~
from easy-rl.
 Jacklililil
commented on May 19, 2024
Jacklililil
commented on May 19, 2024
2.3.10马尔可夫决策过程控制 倒数第二段的第一句话不对吧:对于一个事先定好的马尔可夫决策过程,当智能体采取最佳策略的时候,最佳策略一般都是确定的。
是不是要将第二个最佳策略改成最佳价值函数呢
from easy-rl.
qiwang067
commented on May 19, 2024
2.3.10马尔可夫决策过程控制 倒数第二段的第一句话不对吧:对于一个事先定好的马尔可夫决策过程,当智能体采取最佳策略的时候,最佳策略一般都是确定的。 是不是要将第二个最佳策略改成最佳价值函数呢
您好,这句话是没问题的,当智能体采取最佳策略的时候,最佳策略一般都是确定的,即确定性策略:

from easy-rl.
 quarkerdlz
commented on May 19, 2024
quarkerdlz
commented on May 19, 2024
在本章的配套代码中from envs.simple_grid import DrunkenWalkEnv的envs找不到,能不能看一下完整代码?
from easy-rl.
Related Issues (20)
- 1.7.1 Gym示例 返回值增多了 HOT 3
- 第四章图4.10标注是不是有误? HOT 1
- Edit problem in Chapter3 HOT 1
- 随书代码在哪 HOT 6
- 第五章勘误 HOT 1
- 内容勘误? HOT 3
- 添加参考文献 HOT 1
- SAC代码问题 HOT 2
- 4.3 REINFORCE:蒙特卡洛策略梯度 HOT 1
- 最新的版本,可以出PDF吗 HOT 2
- value_iteration 算法不收敛 ? HOT 1
- 错别字 HOT 2
- DuelingDQN.ipynb中可能存在的两个BUG~
- 我在运行DQN代码时,初始的state总会多一个值。
- 图6.8左下角标识应该是“动作价值(Q)”? HOT 1
- DDPG算法实现出现问题
- 关于书中DDPG算法的疑问
- PPO算法的实现, 为啥要给概率取对数? HOT 2
- 连续动作空间的PPO算法 HOT 2
- dqn算法问题
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from easy-rl.