Comments (41)
 linouk23
commented on May 30, 2024
1
linouk23
commented on May 30, 2024
1
@abintrd we're happy to let you know we've just released 0.9.0 version of TF Provider that fixes the issue.
from terraform-provider-confluent.
 iamjekyun
commented on May 30, 2024
1
iamjekyun
commented on May 30, 2024
1
Based on the UI, it seemed like it took 3~5 minutes. Sad part is that we are using atlantis + terraform remote, so it's pretty hard to import the resource. We'll look forward to the further release for now.
from terraform-provider-confluent.
iamjekyun
commented on May 30, 2024
1
I think that the idea makes perfect sense for temporary workaround.
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
1
For the record, we received an email and created an internal ticket to track the issue.
from terraform-provider-confluent.
 abintrd
commented on May 30, 2024
1
abintrd
commented on May 30, 2024
1
Is there any update on the internal ticket? I wonder if it even makes sense to keep the status of the connector as part of terraform state. Imagine a situation where the terraform apply is done as part of an automated CD pipeline.
- A developer makes some modification in the configuration, runs a
terraform planand finds the new plan matches with what he/she needs. - Developer opens a PR and merges it to master.
- CD pipeline runs
terraform apply.
Now if an existing connector fails between steps 2 and 3, for any number of reasons, terraform apply will delete and recreate that connector. This is behaviour in my opinion developer would not be expecting and could cause cascading failures in downstream.
from terraform-provider-confluent.
 bjaggi
commented on May 30, 2024
1
bjaggi
commented on May 30, 2024
1
@linouk23 @nmaves
we are seeing the same issue again...
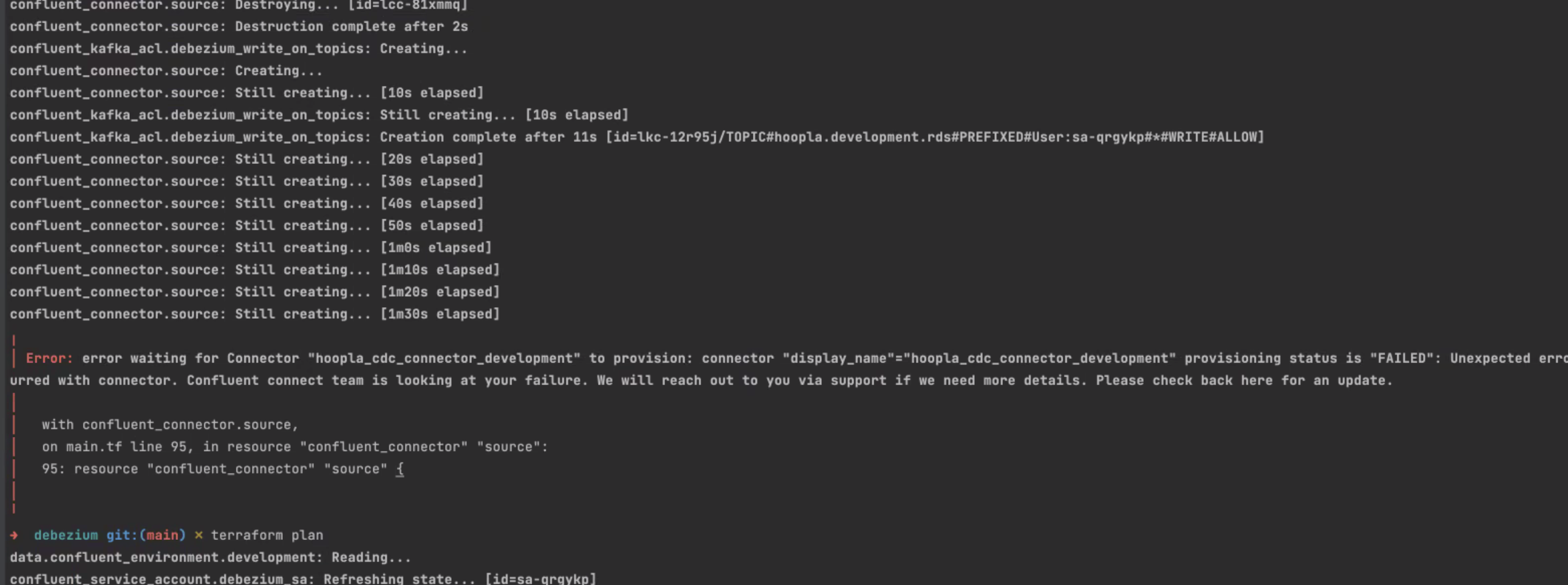
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
1
👋
update: we released a new 1.10.0 version of TF Provider that should mitigate this issue by adding an initial wait when creating a confluent_connector resource.
cc @bjaggi
from terraform-provider-confluent.
 nmaves
commented on May 30, 2024
1
nmaves
commented on May 30, 2024
1
@linouk23 the 1.10.0 release fixed our issue.
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
Thanks for reporting an issue @abintrd!
After some time the connector goes from failed to running state. but because of the first failure terraform aborts and the state file doesn't get updated.
That's a very good observation, which is why we included this block of code:
PollInterval: 45 * time.Second,
// Workaround to fix `PROVISIONING` -> `RUNNING` -> `FAILED` -> `RUNNING`.
ContinuousTargetOccurence: 4,
that basically waits for 4 * 45 = 3 minutes of RUNNING state before exiting on FAILED.
It sounds like we need to tune these constants, based on your experience, how long did you have to wait to see RUNNING state?
For a quick fix (until we update the provider), I'd recommend importing the connector like this:
$ export CONFLUENT_CLOUD_API_KEY="<cloud_api_key>"
$ export CONFLUENT_CLOUD_API_SECRET="<cloud_api_secret>"
$ terraform import confluent_connector.my_connector "env-abc123/lkc-abc123/S3_SINKConnector_0"
from terraform-provider-confluent.
abintrd
commented on May 30, 2024
@linouk23 Thanks, happy that you already am aware of the situation. From terraform apply the last entry form log is
module.somemodule.confluent_connector.source: Still creating... [2m40s elapsed] and I see a log entry for every 10s. So its probably is because of the 3 minutes limit. Can this limit be made configurable through terraform or as an environment variable?
And we are currently using the work around that you suggested. But we should find a solution where there is no failure to make this into our CI/CD pipeline.
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
I see a log entry for every 10s
fun fact: TF will display a log every 10s even if TF sends a request every minute.
Sounds like we might want to override 4 * 45 to 4 * 60 or something.
from terraform-provider-confluent.
iamjekyun
commented on May 30, 2024
we are having the exact same error of PROVISIONING -> FAILED -> RUNNING Root cause is also ""Failed to access Avro data from topic name.of.topic : Unauthorized; error code: 401" in 0.9.0.
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
@iamjekyun based on your experience, how long did you have to wait to see RUNNING state?
For a quick fix (until we update the provider), I'd recommend importing the connector like this:
$ export CONFLUENT_CLOUD_API_KEY="<cloud_api_key>"
$ export CONFLUENT_CLOUD_API_SECRET="<cloud_api_secret>"
$ terraform import confluent_connector.my_connector "env-abc123/lkc-abc123/S3_SINKConnector_0"
FWIW our backend team is working on a fix to avoid this weird transition.
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
@iamjekyun that's interesting, 0.9.0. basically waits for 2*4 = 8 minutes of resource being in a RUNNING state before the resource is marked as successfully created 🤔
But yeah, as I mentioned,
FWIW our backend team is working on a fix to avoid this weird transition.
For now we could increase this timeout even more to like 15 minutes if you think it might help (and if you don't mind waiting a little bit more when applying the plan).
from terraform-provider-confluent.
iamjekyun
commented on May 30, 2024
I see. I can conduct some experiments on our end, but before that, we can confirm that 15 minutes of timeout would fix the issue.
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
@iamjekyun thanks, that'd be super helpful!
Just to make sure, it's technically not exactly a timeout but rather a period of time for which TF Provider waits to ensure the connector is indeed created. Let me be more specific: the way it works for other resources that take 10 minutes to provision (for example, networks) is TF Provider checks every minute to see whether its status is RUNNING by sending a GET request. As soon as the status is RUNNING, TF Providers marks the resource as provisioned and successfully exists the creation flow.
However since we can see RUNNING -> ERROR -> RUNNING confusing transition for connector resources (and while we're waiting on our team to fix it on their side) the mentioned algorithm doesn't work so instead we proactively added a hack to TF Provider: check its status every 2 minutes and wait until it's RUNNING 4 consecutive times. The idea was it'll basically wait for connector to be in RUNNING status for 8 minutes but it seems like it doesn't always help so waiting for 8 -> 15 minutes might help (and since you use CI to apply terraform configuration waiting for a little bit longer shouldn't be too much of a concern -- again, until our backend team fixes this issue).
Let me know if ⬆️ makes sense or if you have a better idea about fixing it.
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
That's great to hear @iamjekyun! We're going to release a new version (that will include the fix) tomorrow or something.
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
@iamjekyun we've just published 0.10.0 version, could you try it out and let us know whether this temporary workaround fixes the issue?
from terraform-provider-confluent.
iamjekyun
commented on May 30, 2024
Sure, I'll try it out today. But I have single concern. When we re-provisioned the connector way before with the same name, the connector consumed the message with the earliest offset (what we wanted is to consume from the latest, or pick up from the latest offset that the previous connector read). What could be the expected behavior of the re-deployed connector this time?
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
I'm not an expert in connectors unfortunately, you might find the docs about PostgreSQL CDC Source Connector (Debezium) for Confluent Cloud here.
from terraform-provider-confluent.
iamjekyun
commented on May 30, 2024
Hi, we managed to try out 0.10.0 and the connector still fails. We saw that "RUNNING -> FAILED -> RUNNING" cycle runs less than 8 minute. (though varies). The most strange part is that CI fails in 1 minute. Very confusing,,,
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
Oh I might know where the issue is: the code effectively exits once it sees FAILED status (thinking that it's a terminal state) so our fix should be not to query every minute immediately but rather wait for like 10 minutes first (to ensure the connector went RUNNING -> FAILED -> RUNNING) and then wait for RUNNING state or something. Thanks for trying it out!
We're planning to do our next release early next week.
from terraform-provider-confluent.
iamjekyun
commented on May 30, 2024
This might be an overwhelming request, but could you please make a temporary version that might fix the issue? Our production environment is in an unstable state to leave it this way.
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
@iamjekyun sure thing, we'll include this fix in a release early next week, let me know if that's OK.
from terraform-provider-confluent.
iamjekyun
commented on May 30, 2024
If it's only possible, we want it as soon as possible
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
@iamjekyun tomorrow is a day off for my team, but we'll see what we can do.
from terraform-provider-confluent.
iamjekyun
commented on May 30, 2024
Sure. Really appreciate it
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
Update: you might need to wait until early next week unfortunately.
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
@iamjekyun could you try again? We've just released 0.11.0 version with a fix that waits for 15 minutes first (to ensure the connector went RUNNING -> FAILED -> RUNNING) and then waits for RUNNING state.
from terraform-provider-confluent.
iamjekyun
commented on May 30, 2024
It seems like 0.11.0 includes a lot of resource name change. We already have handful s3 connectors that has been successfully provisioned by this provider (Some connectors, by sheer luck, had no intermittent FAILURE state). And these are not being integrated. It says:
Error: no schema available for confluent_connector.new-s3-sink-connector["slots2-sss-dev-s3-sink"] while reading state; this is a bug in Terraform and should be reported
I saw that the 0.11.0 upgrade guide requires some modifications on terraform state file. Is there any way to bypass this seding on state file?
from terraform-provider-confluent.
iamjekyun
commented on May 30, 2024

Also terraform.tfstate file inside the atlantis scheme doesn't seem to store all the resources in it. (This PR had lots of plan and apply before and it's still open)
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
It seems like 0.11.0 includes a lot of resource name change.
That's right, unfortunately we made a decision to make this breaking change (FWIW it's similar to what k8s provider does).
I saw that the 0.11.0 upgrade guide requires some modifications on terraform state file. Is there any way to bypass this seding on state file?
None that I'm aware of but let us know if you figure out how to avoid it. Well, alternatively you could run a bunch of imports if it's easier for you.
Also terraform.tfstate file inside the atlantis scheme doesn't seem to store all the resources in it.
Interesting, are there any state files inside that module directory?
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
I'm not sure but this comment might help you to find TF state file.
from terraform-provider-confluent.
iamjekyun
commented on May 30, 2024
We followed the steps of that very comment, but we don't feel quite comfy about manipulating the state file by ourselves. I think we have to come back to your official connector after the RUNNING -> FAIILED -> RUNNING connector issue has been solved. Meantime, we might just go back to the unofficial provider that we used. Sorry for not testing the release, but if it really just sleeps for 15 minutes, then it would be sufficient. (It approximately takes for 5~7 minutes to come back normal)
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
We followed the steps of that very comment, but we don't feel quite comfy about manipulating the state file by ourselves.
Sure thing, makes sense.
have to come back to your official connector.... Meantime, we might just go back to the unofficial provider that we used.
I guess what you meant is to continue using 0.10.0 and wait for a fix from the backend team.
That's totally reasonable, no worries! One thing to note is we're planning to GA (start recommending it for prod usage instead of just for testing purposes) TF Provider soon so you'll have to go through this migration step sooner or later (hopefully someone will figure out a better way to do it instead of running sed -- that said, in similar cases other providers made users reimport all the resources so that might be unlikely).
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
@iamjekyun thanks for waiting and I'm happy to let you know
RUNNING -> FAIILED -> RUNNING
problem was resolved by our backend team and starting from 1.1.0 version of TF Provider confluent_connector is marked as GA (i.e., ready for usage in production):

Let me know if it helps!
from terraform-provider-confluent.
abintrd
commented on May 30, 2024
I am using provider version 1.4.0 and the issue still not resolved. conenctor goes from RUNNING -> FAILED -> RUNNING. But the terraform fails
╷ │ Error: error waiting for Connector "connector-name" to provision: connector "display_name"="connector-name" provisioning status is "FAILED": Unexpected error occurred with connector. Confluent connect team is looking at your failure. We will reach out to you via support if we need more details. Please check back here for an update. │
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
That's unfortunate to hear!
Could you share the org ID & data & time when you run into this issue again with [email protected] so our team could investigate?
We did test our fix with other connectors and it seemed to work 🤔
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
cc @abintrd
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
👋 @abintrd! Thanks for the message!
The internal ticket (CNC-154) is still marked as In Progress unfortunately. The main challenge here is the team launched an initial fix a while ago that seemed to resolve an issue for most of the scenarios but based on your previous feedback we can still see this one-off in some corner case.
Regarding the other question, there're 2 things:
pause/resumefunctionality seems to be popular sostatusattribute is pretty useful. In your specific scenario, I think what will happen isupdate()operation will fail with the following error.- on top of that we recommend our users to use
lifecycle {
prevent_destroy = true
}
to avoid unexpected resource deletions.
from terraform-provider-confluent.
linouk23
commented on May 30, 2024
Thanks for sharing the information!
We'll try to increase our initial waiting time in our next release of TF Provider to mitigate the issue until CNC-154 is resolved.
from terraform-provider-confluent.
Related Issues (20)
- Error: All 4 schema_registry_api_key, schema_registry_api_secret, schema_registry_rest_endpoint, schema_registry_id attributes should be set or not set in the provider block at the same time HOT 1
- confluent_schema_exporter: automatically pause schema exporter for update HOT 3
- confluent_invitation resource is trying to create inviation as service account HOT 2
- Flink compute resource thinks it needs to be recreated HOT 4
- Configuring SSO strictly through Terraform seems to not work.
- Crate a dependency between SR ID and the SR endpoint to avoid errors when two or more clusters share the same endpoint
- CRUD operations of kafka_acl uses the APIKey in the credentials block instead of provider block HOT 3
- Is it possible to get Kafka `credentials` from `confluent_kafka_cluster`? HOT 1
- Stale resource due to terraform provider upgrade HOT 4
- Schema diff can match against an earlier version of the schema
- RBAC support for "DataDiscovery" in Terraform HOT 2
- Is it possible to set a topic schema within `confluent_kafka_topic`? HOT 1
- Incompatible schemas, and Client.Timeout while contacting schema registry corrupt tfstate file during apply HOT 2
- Creating and managing user groups HOT 2
- Feature request - support default values for topic config items after expert mode edit
- Upon mirror topic creation, have the option to not store credentials in the Terraform state file.
- Add support for new topic configuration fields - message.timestamp.after.max.ms and message.timestamp.before.max.ms HOT 6
- Schema not found when importing a schema in a 20000+ schemas in Schema Registry HOT 3
- Request: allow export of API keys with confluent_tf_importer HOT 1
- Support importing network,schema registry,tgw attachment resources using Resource Importer
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from terraform-provider-confluent.